遷移學習/弱監督論文雜讀(門外漢級)
也不太清楚有些論文到底屬不屬於這個領域, 大多數都是淺嘗輒止。然後主要看的基於深度學習的adaptation和方面的論文,希望能對這個領域最新的工作有個概念,主要給自己看。其實個人覺得解決這個問題真的不是重點,而是研究它的成因,以便在訓練的過程中解決CNN泛化的問題才是本質
未看或未總結
[2018-arxiv]Progressive Feature Alignment for Unsupervised Domain Adaptation [paper]
[2018-NIPS]Generalizing to Unseen Domains via Adversarial Data Augmentation
[2018-ECCV] Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
[2018-ECCV-oral]Diverse Image-to-Image Translation via Disentangled Representations
[2018-ECCV-oral] A Style-Aware Content Loss for Real-time HD Style Transfer
[2018-CVPR] Joint Pixel and Feature-level Domain Adaptation in the Wild
[2018-CVPR] Iterative Learning with Open-set Noisy Labels
[2018-CVPR-weakly] Zigzag learning for weakly Supervised Object detection
[2018-arxiv-weakly] Exploring the Limits of Weakly Supervised Pretraining[paper]
分類
[2018-arxiv] Adaptive Semantic Segmentation with a Strategic Curriculum of Proxy Labels [
自從看了MCD後,對類似的論文要求就高了。這篇論文的主體思想在我看了MCD後就想到了,但是個人覺得逃不出MCD的魔爪,也就沒有嘗試。當然這篇論文有兩個東西不在我的意料之中
1 在souce domain用難例挖掘,在target domain用簡例挖掘
2 在損失函式裡面加個一個loss,使得兩個分類網路的權值不同
其實個人覺得一開始就用proxy-label(一些論文裡稱之為pseudo-label)是有一定風險的,這個跟任務有關,沒有一種很好的機制保證在很多工都work,因為一不小心就跑飛了。
另外這篇論文竟然不引用MCD不是很能理解
[2018-ICML] Learning Semantic Representations for Unsupervised Domain Adaptation
我個人覺得這篇文章一定程度上受到了adaptive bn的影響。出發點也較為合理,因為直接用proxy-label或者pseudo-lable個人是覺得不太魯棒的。作者用的是align每一個label的均值,明顯更合理些。當然還是那個問題,用proxy-label需要仔細設計,不一定在很多工都適用。
[2018-ICLR] Self-ensembling for visual domain adaptation [paper]
沒有仔細看,感覺跟下面的MCD有點異曲同工
[2018-ICML]CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION [paper]
個人覺得比較無趣的工作,用cyclegan做image translation,估計是架不住效能好
[2018-PR] Adaptive Batch Normalization for practical domain adaptation [paper]
這篇也是我非常喜歡的論文,前期沒調研清楚,我跟這篇想到一塊去了,等好多實驗做完了才發現思路已經被髮了。所以進入一個領域要早,行動也要快。個人已經驗證過這種zero-shot方法在作者沒有實驗的很多工上都能有較大的提高。 當然理論上還是有一定缺陷的,所以效能上比用了target damain資料的方法要差點,但是方案確實很簡潔,我個人覺得很優美,發PR有點小虧。
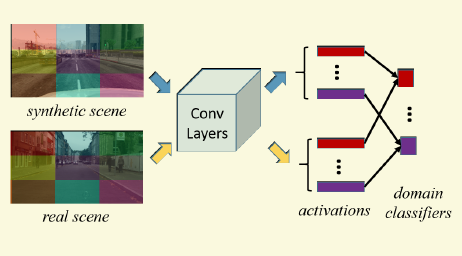
[2018-CVPR-oral] Maximum Classifier Discrepancy for Unsupervised Domain Adaption
外行的角度看,非常漂亮的工作,非常創新且有意思的文章,解決方案也非常簡潔。分類分割都適合,而且還有原始碼.
基本上傳統的adapation的工作都是一個分支是對抗地區分源域和目標域,另外一個分支去對源域的樣本做分類,兩個分支共享網路(特徵生成器)的一個重要任務是將源域和目標域的樣本都投影到同一個特徵空間,那麼有可能會造成下圖左邊的情形,雖然源域和目標域區分不出來了,但是不同類別的樣本特徵空間有可能也會糾纏在一起,不利於最終的分類目標。雖然個人覺得圖中有些誇張,因為畢竟還在另外一個分支在起作用,但是確實之前的方案沒有刻意地考慮這個問題。
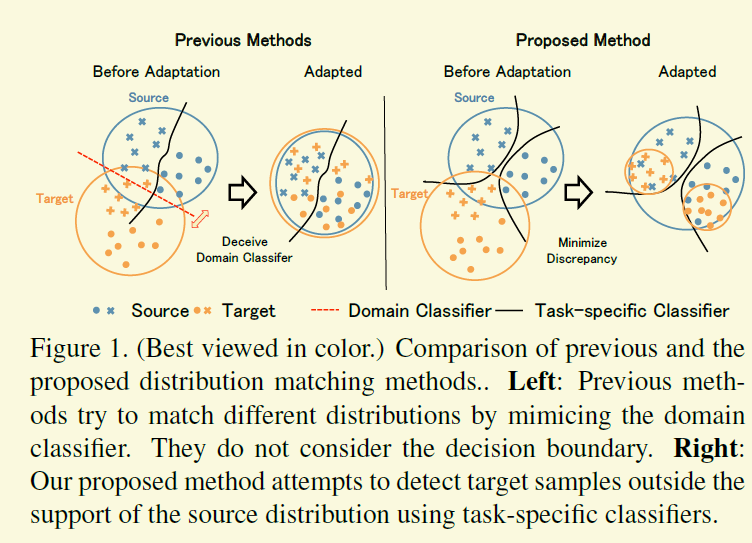
所以為了達到考慮類別分介面的目的,該工作的框架和訓練目標有了明顯的變化。同樣一個生成器,兩個分支,一個分支還是做分類,另外一個分支從對抗訓練變成了還是做分類任務.然後每次迭代訓練都分成三步。第一步,按照普通的分類損失讓生成器和兩個分類器能夠處理源域的樣本,第二步,固定生成器,訓練兩個分類器,同樣,兩個分類器需要處理源域分類損失,另外一個目標需儘量對目標域的樣本做出不同的預測。這樣訓練過後的一個好處就是,如下圖中的“maximize discrepancy”部分,如果兩個分類器都對一個目標樣本分類一致的話,那麼這個樣本肯定是比較好遷移的,兩個分類器的分介面會先向這些好處理樣本收縮。第三步,如下圖中的“Minimize discrepancy”,固定分類器,訓練生成器,使得樣本的特徵向F1,F2漂移.經過多次這樣的迭代,最終就能得到想要的結果。
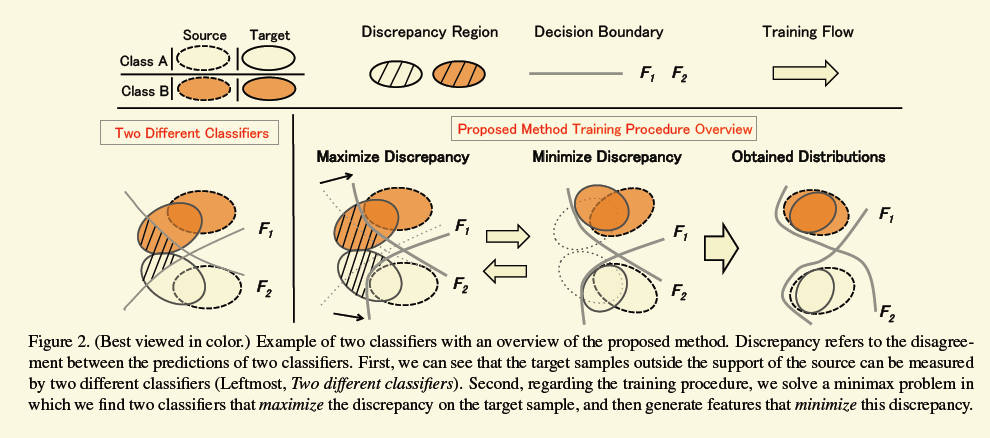
用作者的原始碼簡單地跑了一下GTA5到cityscape的實驗,發現兩個loss有量級上的差距,後面需要再仔細看看。
一個可能的小缺陷是F1和F2都太靠近分介面,另外一個就是不知道target domain資料的分佈,不一定能像作者畫的那樣,F1,F2能以合適的速度搶佔target domain的區域。
[2017-NIPS] Learning multiple visual domains with residual adapters
一些量化方法裡把大部分的權重量位元而保留少部分作為浮點型以提高精度。這篇文章的出發點其實有一點異曲同工之妙。它希望用同一個網路架構去解決不同domain的問題,但是希望共享大部分的權值,而重新訓練少部分值。跟傳統的finetuneing共享底層特徵不同,該工作利用resnet的buildblock,並將其裡面的大部分引數設定成了domain-agnostic的引數,而剩下了小部分的設定成domain-specific引數。domian-agnostic的引數可以通過在一個大型的資料庫訓練後固定下來。而domain-specific的引數就針對不同的資料或任務去調整。如下圖,domain-specific的引數包括所有的BN層和作者新加的一些卷積層。這篇還有個改進版本。

[2017-CVPR] Unsupervised Pixel-Level Domain adaption with Generative Adversarial Networks
作者給出了一個非常直觀也非常有意思的思路,應該是我看到的第一篇利用style transfer做adaption的工作。source domain的資料有label,target domain沒有label,那作者就利用source domain的資料去生成類似於target domain的資料,然後用這些生成的資料去訓練,一方面資料類似,另一方面又有label.

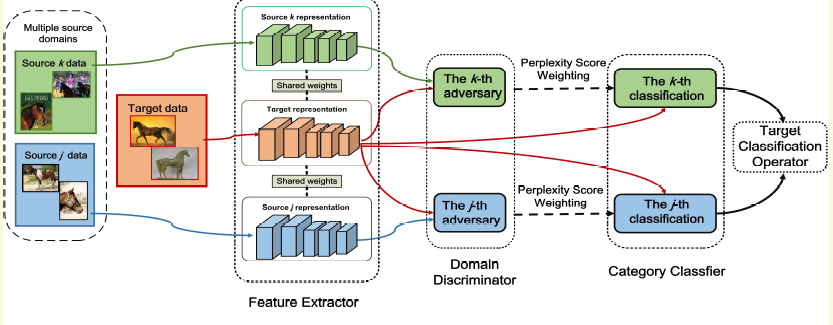
[2018-CVPR]Deep Cocktail Network:Multi-source Unsupervised Domain Adaptation with Category Shift
這一篇沒有看的太懂,囫圇吞棗。該工作主要解決兩個現實中可能出現的問題。第一個是可能有多個不同的source,因此該論文叫multi-scoure...,第二個target domain的類別不一定每個source都有,稱之為catogoryshift。作者的做法個人理解有點像ensemble,不過加了weight。
首先作者為每個source都訓練一個分類器Cs,並且還有一個domainclassifier以區別它和target domain. 那麼想要得到一幅最終圖片的類別,那麼可以ensemble多個單獨分類器Cs的結果。如果測試圖片跟那個domain最接近,那麼那個分類器的權重更高。domain的接近性可以用domain classifier的損失來判斷。沒看懂的主要地方在公式6,也就是domain classifier的損失選擇原因。
[2018-CVPR] Joint Optimization Framework for Learning with Noisy Labels
該論文處理的的有錯誤標註的情況,相比於下篇論文,應該是個close-set的案例,也就是說雖然有些樣本被標錯了,但是樣本的真實類別還包含在這個資料庫中。比如imagenet有1000類,裡面有貓有狗,然後一幅狗的圖片被標成了貓,貓這個類別還是在這1000類裡面,就稱之為close-set.如果狗的圖片被標成了狗糧,不在這1000類裡面,就定義成open-set.
這個工作首先能給人insight的一個貢獻從實驗中發現了一個很有趣的現象,當用一個高學習率去訓練網路時,網路對這種噪聲比較魯棒。
另外整個大框架的思路是很普通的,我剛進入這個領域就能想到,如下圖,不過難點就在於怎麼distill好的樣本,如果沒有好的方式,訓練出來的結果很有可能不是想要的,就和把已經有部分認知能力的中學生扔進山裡自我學習差不多,有可能出來一個傑出人才,有可能變成壞蛋,所有得想辦法做一些間接的監督。
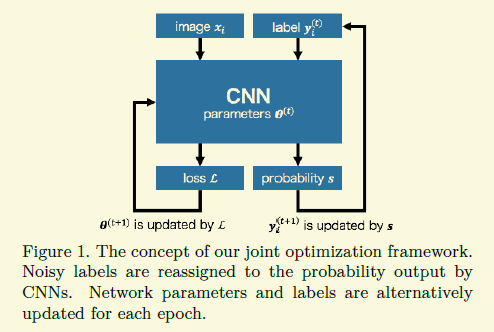
作者給出的方案是加兩個約束在損失上。第一個是預測類別分佈要與先驗知識(比如訓練集的類別分佈)儘量一致。這裡約束存在明顯的缺陷,因為訓練時候一般batch不是很大,對於一個batch的均值這個類別分佈有個比較大的bias,特別是類別比較多的情況下。第二個約束是希望每個預測的label儘量confident,比如預測的概率不要停留在0.5,儘量要麼0要麼1,這是合理的,不過沒有理解作者給出的可以防止陷入區域性最優解的理由,需要再看看。
檢測器
[2018-CVPR] Domain Adaptive Faster R-CNN for Object Detection in the Wild
檢測器的adaption問題研究的還是很少的,雖然本篇採用的還是分類器adaption的思路。如下圖,該工作在faster rcnn的基礎上加了三個模組。
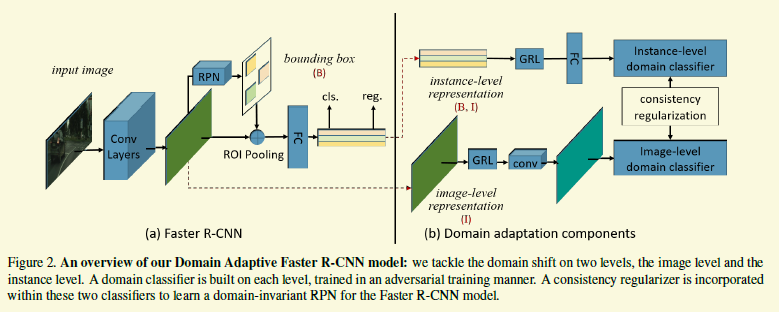
其中兩個模組是image-level adaption和 instance-leveladaption,很好理解。就是利用gradient reverse layer讓基礎的卷積層分不清圖片和其中的物體是來自源域還是目標域。第三部分的consistency regularization也很好理解,就是作者希望兩個模組的判斷有一致性,最好不要出現image-level分類成源域而instance-level把該圖的物體分類成目標域這種顯然矛盾的結果,所以作者加了一個歐式loss,只需要計算每個instance類別啟用值跟imagelevel head上特徵圖上圖個啟用值平均值的歐式距離。
(一點小疑問,由於RPN初期給出的box一般不太好,在instance的loss權重的設定上是不是能先低後高而不是一直保持在一個固定值上,實驗為準)
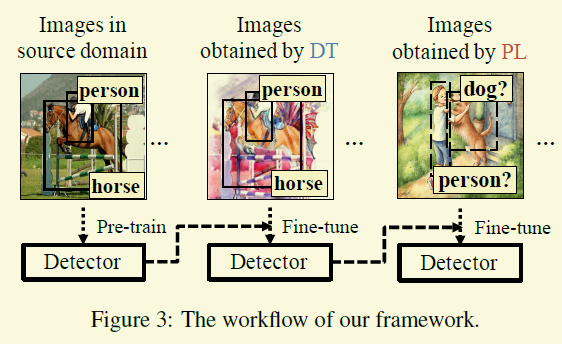
[2018-CVPR]Cross-domain weakly supervised object detection through progressive domain adaptation
不知道怎麼評價這篇文章。這篇文章想做的是跟其他的有些區別,首先他想做的是物體檢測,不過在target domain裡不像之前的完全沒有標註,而是說有一些image level的標註,比如說這幅圖裡有貓和狗,但是不知道在什麼地方。
作者用了兩個技巧,第一個他稱之為damain transfer,個人認為就是上面提到的 Unsupervised Pixel-Level Domain adaption with GenerativeAdversarial Networks 那一套,只是現在GAN上用了非常火的CycleGAN.第二個就是Pseudo-Labeling,target domain不是有影象級別的標籤麼,比如說狗和人,那麼我先用在source domain訓練的檢測器去檢測,狗和人置信度第一的框暫時認為是真值,然後去迭代訓練。其實這種思想感覺是MIL的一個子集,早在image caption上就做的比較好了,比如 From Captions toVisual Concepts and Back 這篇論文
分割
[2018-CVPR] fully convolutional adaptation networks for semantic segmentation[paper]
個人認為這篇工作每個子模組思想上都沒特別大的創新,不過由於總體上講在畫素域做adaptation的確實不多,並且本人的一些粗淺實驗顯示直接在畫素域做對抗訓練效果不好,所以這篇論文還是能給人一些啟發的。作者主要將畫素域的adaptation分成兩個子模組,並claim成兩個很高大上的詞彙叫appearance-level和representation-level domain adaptation,個人覺得其實就是style transfer和對抗訓練,即先把源域的圖片transfer到target domain,然後利用普通的畫素域進行對抗訓練。不過作者用的是老式的stype transfer的方法,一幅源域圖片感覺應該都得調好久。
[2018-CVPR]ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes
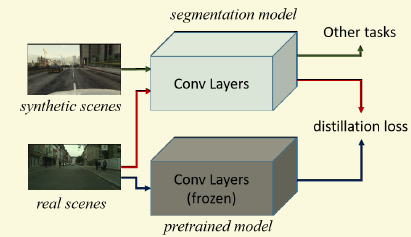
主要是想利用合成的資料遷移到實際的資料。主要創新是在損失的設計上,adaption核心的東西還是裡用分類的那一套。
作者在損失設計上考慮了兩個方面,
第一個是Target Guided Distillation,個人看完之後還是覺得比較詭異,不過按照論文裡的ablaiton study效果不錯。作者用了兩個同樣架構的網路,只是一個權值用的是ImageNet訓練的結果並且不會再改變,一個是權值需要微調以用於分割。固定不動的網路輸入是真實圖片,在某個層得到一個啟用圖f1,分割網路輸入的是合成圖片,還是在同樣的層上得到另外一個啟用圖f2.那麼這個損失的定義就是這兩個圖f1和f2的相異性,用的是逐點的歐式距離。所以很容易發現詭異的地方有兩點,第一個是合成圖片和實際圖片不是配對的,不過在低層或者高層去匹配感覺都不是合理。第二個是一個網路是為分割,一個網路是為分類,這樣的匹配合理性真是不是很能理解。
第二個在於畫素級別的domain classifier,這個很好理解,就是讓基礎網路不能區分某個畫素點是來自源域還是目標域,不過好像navie的方式不太好使,也就是直接把來自不同域的所有的畫素當成兩個類別,作者認為畫素的方差太大(個人理解是不管是源域還是目標域畫素特徵分佈糾纏在一塊了),那麼網路本來就分不出來,對抗訓練也就沒效果,
作者的方法是根據這類圖片的特殊性,把圖片分成了9塊,比如圖片上中區域對應的可能都是天空,中間都對應的都是馬路什麼的。經過這樣的切分後,某個區域的畫素點的特徵比較集中,網路更能抓住它的特徵,好區別,那麼對抗訓練才有效果。