
spark部署模式解析
單機上可以本地模式執行
單機上偽分散式模式執行
叢集上standalone模式,spark on yarn模式,spark on mesos模式,這裡主要介紹叢集前兩種。
standalone模式
類似於單機偽分散式模式,如果是使用spark-shell互動執行spark任務或者使用run-example執行官方示例,driver是執行在master節點上的。如果使用spark-submit進行任務提交或者在eclipse。idea開發時使用new sparkContext(“spark://master:7077”,”appName”)執行spark任務,driver執行在本地客戶端。
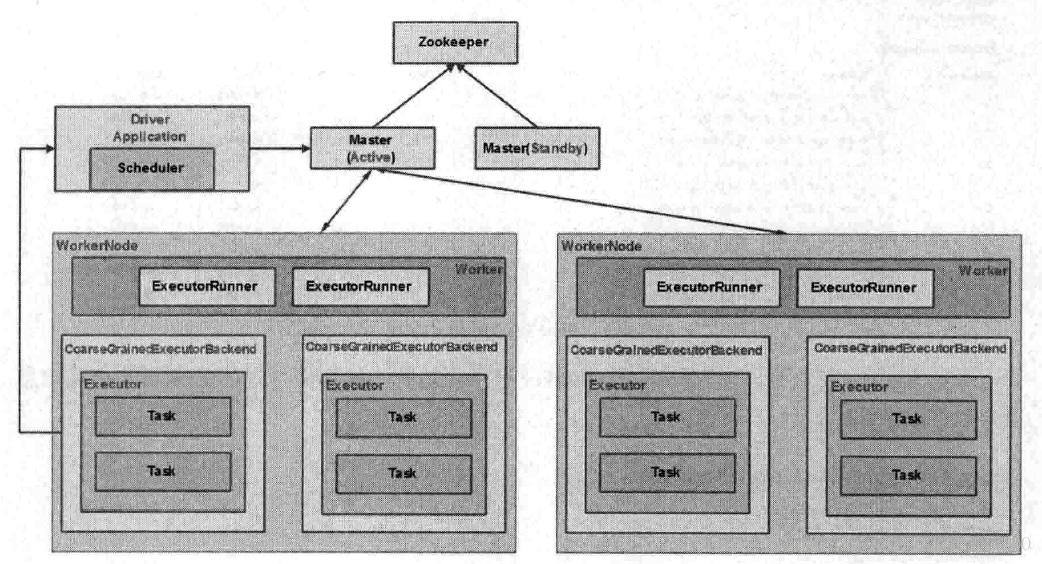
spark application執行主要流程:
(1)客戶端啟動,初始化相關環境變數,application程式碼提交。
(2)反射呼叫org.apache.spark.deploy.yarn.Client,建立DriverActor(其他方式driver可能執行在worker節點)
……
1.Master
master是spark叢集的核心,負責各種資訊,比如Driver,worker,application的註冊,還負責executor的啟動,worker心跳的管理。
2.Worker
worker相當於yarn中的NodeManager,負責當前WorkerNode上資源彙報,監督executor,worker和master之間心跳保持存活性連線。
3.CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend是一個程序,內部負責具體task的執行,和worker和driver通訊。
4.DAGScheduler
DAGScheduler是面向stage層的排程器,負責接收使用者提交的job,根據RDD的依賴關係劃分不同的stage,並且每一個stage內封裝taskset,根據當前快取情況和資料就近的原則,將TaskSet提交給TaskScheduler。
5.TaskScheduler
TaskScheduler是一個任務排程介面,功能是接收DAGScheduler提交過來的TaskSets,提交到叢集執行。如果某個Task執行失敗,根據重試條件重新執行,將執行結果返回給DAGScheduler。類似於yarn中的任務管理,TaskScheduler實現了任務推測執行機制,TaskScheduler為每個TaskSets維護了一個TaskSets維護了一個TaskSetManager用於追蹤錯誤資訊,結果和本地資訊。
6.shuffle分析
……
spark on yarn模式
spark on yarn模式是最優前景的一種模式,分為yarn-cluster和yarn-client
yarn-cluster模型:
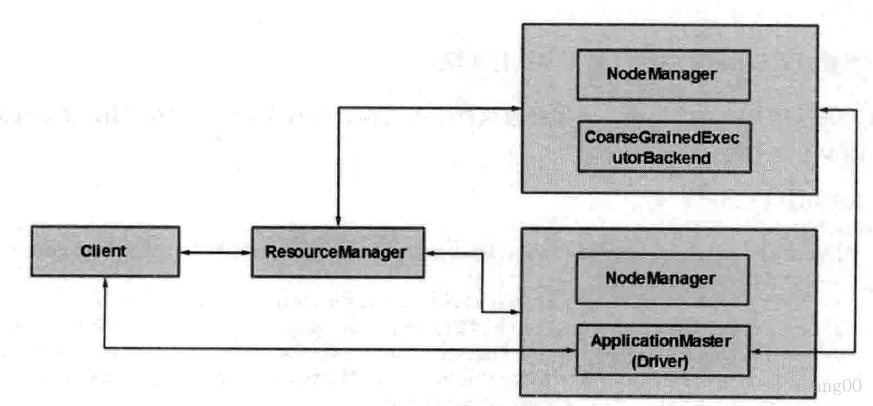
(1)client使用spark-submit向yarn提交spark application。
(2)ResourceManager接受到請求後,為application分配一個container,用來執行ApplicationMaster(其中包含sparkcontext初始化)
(3)ApplicationMaster向ResourceManager申請資源執行executor
(4)ResourceManager分配container給ApplicationMaster,ApplicationMaster和相關NodeManager通訊,在獲得的container上啟動CoarseGrainedExcecutorBacknd,CoarseGrainedExcecutorBacknd在啟動後向ApplicationMaster中sparkcontext註冊並申請task。
(5)ApplicationMaster中的sparkcontext分配task給CoarseGrainedExcecutorBacknd執行,CoarseGrainedExcecutorBacknd執行task並向sparkcontext彙報執行情況。
yarn-client模型:
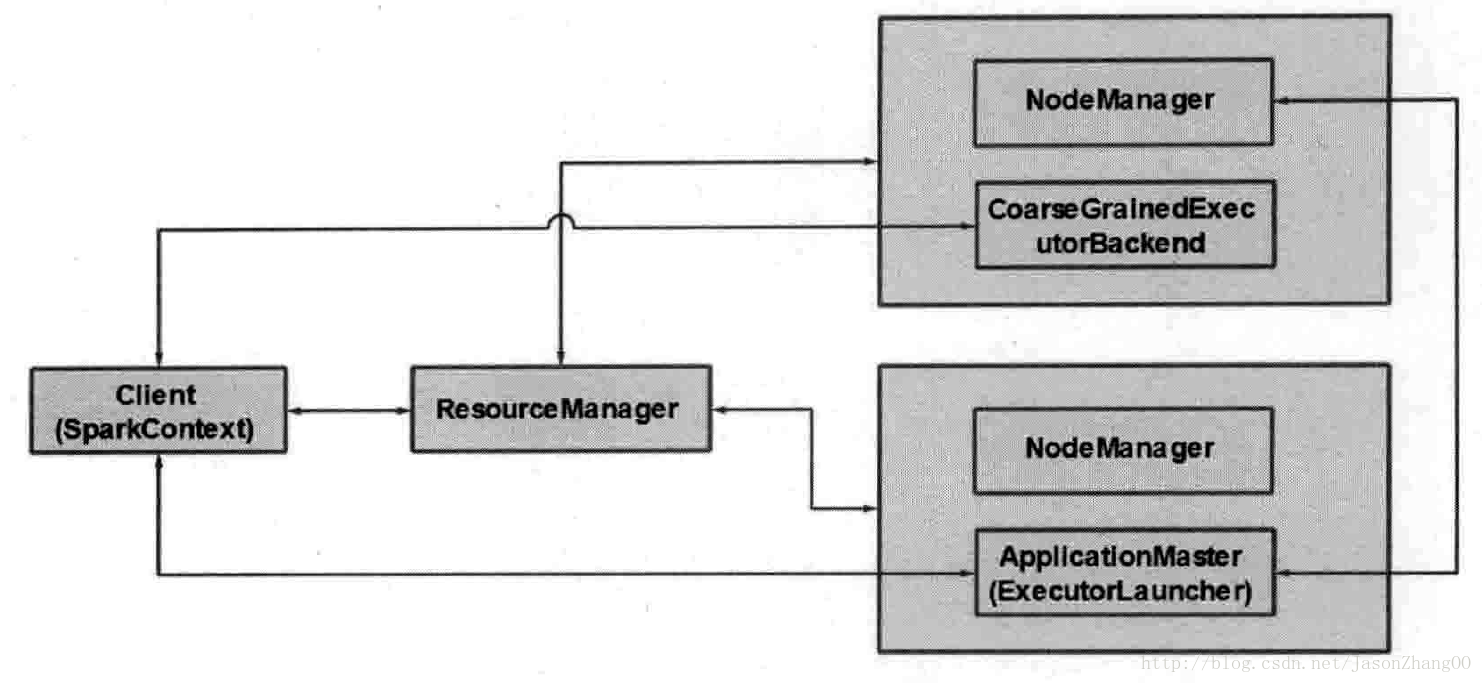
yarn-client和yarn-cluster大體相同,
yarn-client主要是客戶端向yarn提交sparkapplication後,driver在客戶端本地啟動,yarn-cluster中是ApplicationMaster啟動driver。另外,yarn-client中CoarseGrainedExcecutorBacknd獲得container資源,啟動後向客戶端本地中driver中的sparkcontext註冊並申請task。
spark on mesos模式
參考:《大資料Spark企業級實戰》《Hadoop權威指南》