
基於FP-Growth演算法的關聯性分析——學習筆記
資料探勘
比之前的Ap快,因為只遍歷兩次。
降序
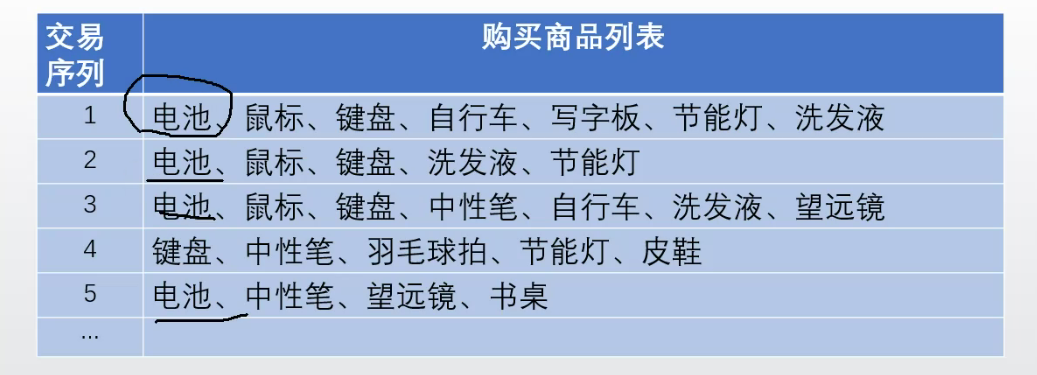
一、構建FP樹
對頻繁項集排序,以構成共用關係。
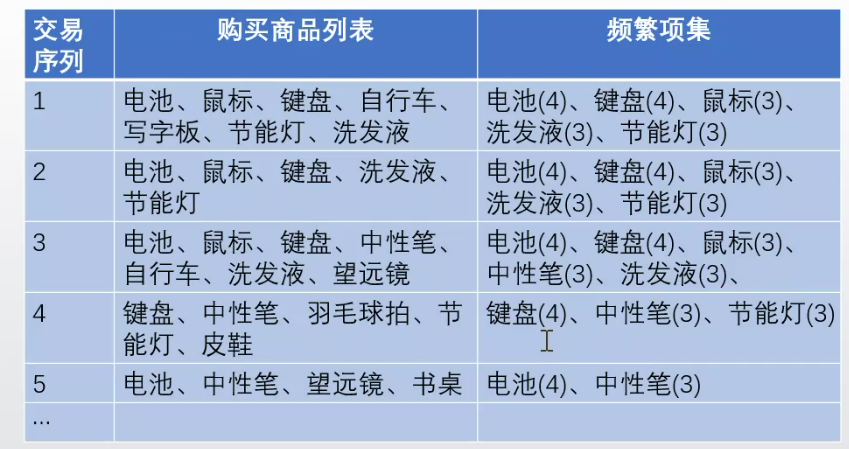
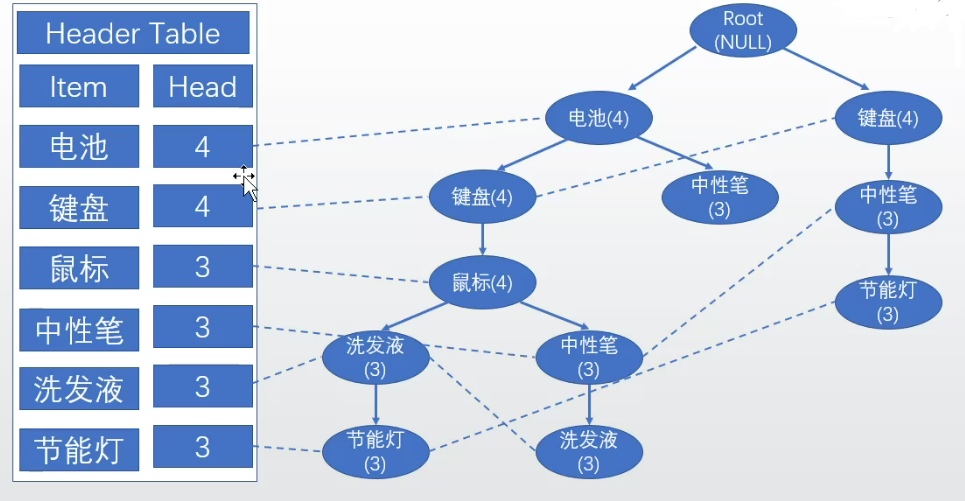
二、基於FP樹的頻繁項分析
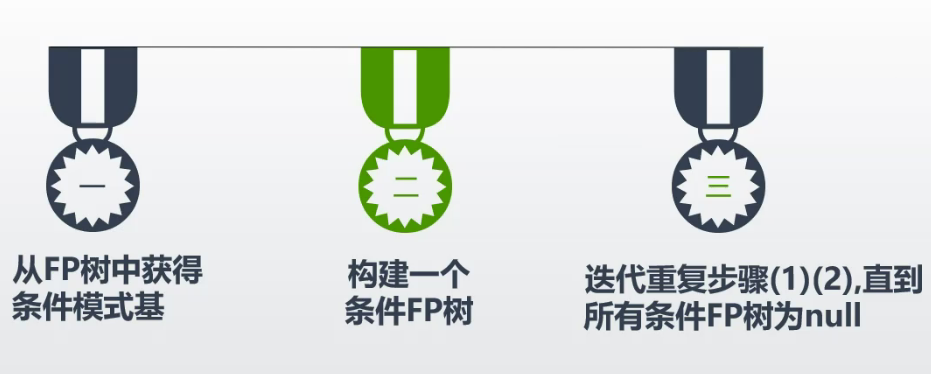
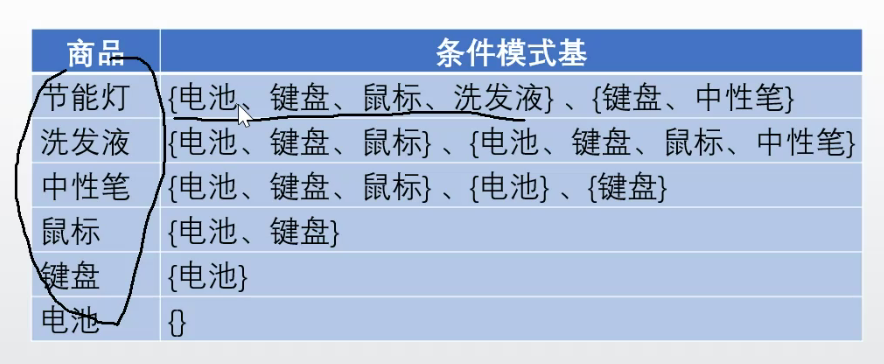

看那個模式基出現過幾次。頻繁度。

看洗髮液的
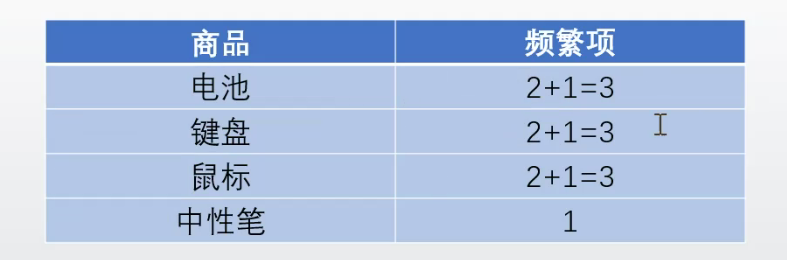
去掉頻繁度小的

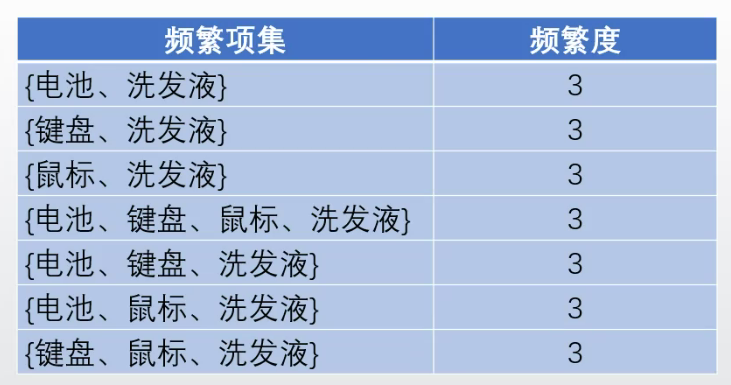
構建洗髮液的條件FP樹。
優缺點:

使用Apriori演算法和FP-growth演算法進行關聯分析 - qwertWZ - 部落格園 https://www.cnblogs.com/qwertWZ/p/4510857.html
相關推薦
基於FP-Growth演算法的關聯性分析——學習筆記
資料探勘 比之前的Ap快,因為只遍歷兩次。 降序 一、構建FP樹 對頻繁項集排序,以構成共用關係。 二、基於FP樹的頻繁項分析 看那個模式基出現過幾次。頻繁度。 看洗髮液的 去掉頻繁
《機器學習實戰》使用Apriori演算法和FP-growth演算法進行關聯分析(Python版)
===================================================================== 《機器學習實戰》系列部落格是博主閱讀《機器學
機器學習之Apriori演算法和FP-growth演算法
1 關聯分析 無監督機器學習方法中的關聯分析問題。關聯分析可以用於回答"哪些商品經常被同時購買?"之類的問題。 2 Apriori演算法 頻繁項集即出現次數多的資料集 支援度就是幾個關聯的資料在資料集中出現的次數佔總資料集的比重。或者說幾個資料關聯出現的概率。 置信度體現了一個數據出現後,另
【機器學習實戰】FP-growth演算法詳解
Here is code 背景 apriori演算法 需要多次掃描資料,I/O 大大降低了時間效率 1. fp-tree資料結構 1> 項頭表 記錄所有的1項頻繁集出現的次數,並降序排列 2> fp tree 根據項頭表,構建fp樹 3>
機器學習實戰——使用FP-growth演算法來發現頻繁集
問題:RuntimeError: dictionary changed size during iteration #問題程式碼 for k in headerTable.keys(): if headerTable[k]< minSup:
資料結構和演算法分析學習筆記——複雜度分析
複雜度分析 本文只是我的個人學習筆記,用於記錄資料結構和演算法的學習總結。 如何得到演算法的執行效率? 事後統計 方式:直接在裝置上執行得到結果 缺點:測試結果受測試環境和測試資料規模影響
計算機演算法設計與分析學習筆記1
基本概念 程式 = 演算法 + 資料結構 演算法描述如何解決一類問題的一種方法,滿足如下性質: -輸入:一類問題的例項 - 輸出:針對例項的解 - 確定性:每條指令無歧義 - 有限性:有限迴圈 程式 不滿足有限性性質, eg. 作業系統為無限
OpenCV學習筆記(二十六)——小試SVM演算法ml OpenCV學習筆記(二十七)——基於級聯分類器的目標檢測objdect OpenCV學習筆記(二十八)——光流法對運動目標跟蹤Video Ope
OpenCV學習筆記(二十六)——小試SVM演算法ml 總感覺自己停留在碼農的初級階段,要想更上一層,就得靜下心來,好好研究一下演算法的東西。OpenCV作為一個計算機視覺的開源庫,肯定不會只停留在數字影象處理的初級階段,我也得加油,深入研究它的演算法庫。就從ml入手
演算法設計與分析學習筆記——最長公共子序列
最長公共子問題待解決問題: 給定兩個序列X和Y,求其一個最長公共的序列Z。 補充解釋:X(m)={x1, x2,,,,,xm},Y(n)={y1, y2,,,,,yn},X和Y可以有共同的元素,Z是這些共同元素的集合,其元素順序在XYZ中都是升序排序的(Z中元素的
關聯分析(一)--FP-Growth演算法
轉自:https://www.cnblogs.com/datahunter/p/3903413.html 關聯分析又稱關聯挖掘,就是在交易資料、關係資料或其他資訊載體中,查詢存在於專案集合或物件集合之間的頻繁模式、關聯、相關性或因果結構。關聯分析的一個典型例子是購物籃分析。通過發現顧客放入購物籃
關聯分析——FP-growth演算法
使用FP-growth演算法來高效發現頻繁項集 FP-growth演算法基於Apriori構建,但採用了高階的資料結構減少掃描次數,大大加快了演算法速度。FP-growth演算法只需要對資料庫進行兩次掃描,而Apriori演算法對於每個潛在的頻繁項集都會掃描資料
基於R語言的Kaggle案例分析學習筆記(五)
藥店銷量預測 本案例大綱: 1、xgboost理論介紹 2、R語言中xgboost相關函式的引數 3、案例背景 4、資料預處理 5、R語言的xgb模型實現程式碼 1、xgboost理論介紹 這部分我直接把一些牛人寫的關於xgb的理論介紹引用過來了,大家可以直
程式碼註釋:機器學習實戰第12章 使用FP-growth演算法來高效發現頻繁項集
寫在開頭的話:在學習《機器學習實戰》的過程中發現書中很多程式碼並沒有註釋,這對新入門的同學是一個挑戰,特此貼出我對程式碼做出的註釋,僅供參考,歡迎指正。 #coding:gbk #作用:FP樹中節點的類定義 #輸入:無 #輸出:無 class treeNode:
算法導論17:攤還分析學習筆記
分析 大小 multi 算法 tip prim pri 但是 最大 在攤還分析中,通過求數據結構的一系列的操作的平均時間,來評價操作的代價。這樣,即使這些操作中的某個單一操作的代價很高,也可以證明平均代價很低。攤還分析不涉及概率,它可以保證最壞情況下每個操作的平均性能。
【數據分析學習筆記】用戶行為分析模型
密度 登錄用戶 精細化分析 做出 新版 分享圖片 結合 評價 指定 一、行為事件分析 1.什麽是行為事件分析 企業追蹤或記錄的用戶行為或業務過程,如用戶註冊、瀏覽產品詳情頁、成功投資、提現等,通過研究與事件發生關聯的所有因素來挖掘用戶行為事件背後的原因、交互影響等。 2.行
算法分析 - 學習筆記
算法設計 ron -a ase log 參考 尋找最大數 輸入 基本 這篇博文主要會講述基礎的算法分析,對於算法分析主要是針對算法運行時間進行分析。 幾個需要註意的讀法:Omega(Ω),Theta(Θ)和大O符號。 一、算法分析 - 最壞情況分析法 算法分析其實主要針對兩
數據分析學習筆記2-----pandas
ear 序列 解釋 它的 轉換 嵌套 class 不同的 而不是 要使用pandas,你首先就得熟悉它的兩個主要數據結構:Series和DataFrame。 1.Series Series是一種類似於一維數組的對象,它由一組數據(各種NumPy數據類型)以及一組與之相關的數
數據分析學習筆記4-----處理缺失數據
浮點 clas taf 方法 fill ilo light .data highlight 處理缺失數據 對於數值數據,pandas使用浮點值NaN(Not a Number)表示缺失數據。我們稱其為哨兵值。 濾除缺失數據 過濾掉缺失數據的辦法有很多種。你可以通過panda
資料分析學習筆記part_4
資料分析 Lesson 4 : 統計學 描述性統計學 - 第一部分 資料型別 數值型別 數值資料採用允許我們執行數學運算(例如計算狗的數量)的數值。 分類資料 分類資料用於標記一個群體或一組條目(例如狗的品種 —— 牧羊
資料分析學習筆記part_1
資料分析 Lesson 1 : SQL初探 SQL和移動平均值 SQL簡介 實體關係圖(ERD) 是檢視資料庫中資料的常用方式。下面是我們將用於 Parch & Posey 資料庫的 ERD。包括:1. 表的名稱 2. 每個表中的列 3. 表配合工作的方式。如下圖所