
吳恩達《深度學習》第四課第三週
卷積神經網路——目標檢測
3.1目標定位
1.分類與定位
分類問題可以有助於定位問題的解決,當識別完圖片型別之後我們可以讓神經網路的輸出增加幾個單元,從而輸出一個邊界框(bounding box),具體而言就是多輸出4個數字(b_x, b_y, b_h, b_w),在這種情況下,輸出將包含:一個分類標籤,四個位置值
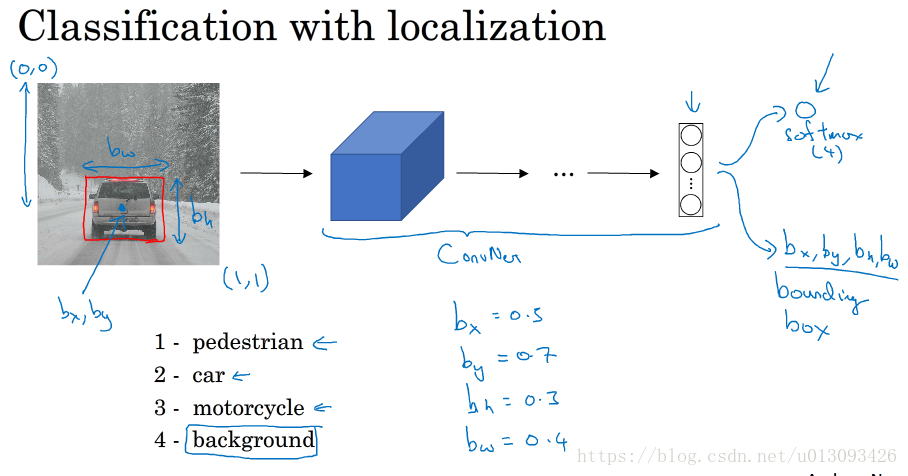
2.定義目標標籤y
假設在分類任務中有4類:pedestrian(行人)、car(車輛)、motorcycle(機車),background(其他) ,這四類中如果輸入影象不是前三類那麼統統算作background,因此在標籤y中需要設定一個引數P_c表徵是否識別出物體,當P_c=1時,y=[P_c, b_x, b_y, b_h, b_w, C1, C2, C3],其中C1, C2, C3分別代表pedestrian(行人)、car(車輛)、motorcycle(機車),三者只有一個可為1,當P_c=0時,則不需要關心y中其他引數,相當於y=[P_c,?,?,?,?,?,?,?]

3.Loss函式L(y_hat, y)

有上圖可知,我們只需考慮P_c=1時的情況,且通常只對邊界框座標應用平方誤差或類似方法。
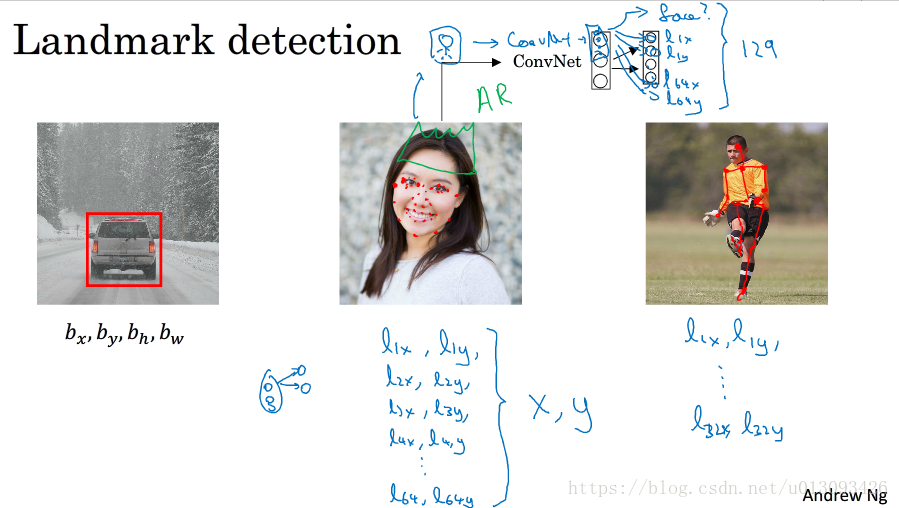
3.2特徵點檢測
1. 特徵點檢測
如3.1中輸出物體邊界框類似,如果我們想提取圖片中的特徵,比如眼睛,那麼我麼需要確定雙眼四個眼角的座標(L_1x, L_1y), (L_2x, L_2y), (L_3x, L_3y), (L_4x, L_4y)。再如識別微笑,我們可能需要提取嘴角的特徵點,也許是64個點或者更多。那麼識別的過程是,將標記好的影象X輸入到CNN中,在softmax層將是一個129個元素的向量,其中第一個元素設為face表徵輸入圖片是否為面部,然後128個元素表徵了64個特徵點的(x,y)值,如下圖:
3.3目標檢測
1.滑動視窗目標檢測
該方法的思路非常直接,即使用某一大小的視窗從輸入影象的左上角開始以某一畫素大小平移滑動,知道影象的右下角,然後再改變視窗大小重複這一過程,每次講視窗擷取的影象作為CNN的輸入進行指定物體的識別,如下圖所示。

2.滑動視窗目標檢測存在的問題
(1)計算代價過高,剪切出了方塊需要卷積神經網路逐個處理
(2)如果增大視窗移動的步頻,可以減少網路的計算量,但是顆粒度太大不利於目標檢測
3.4卷積的滑動視窗實現
1.將全連線層(FC)轉化為卷積層
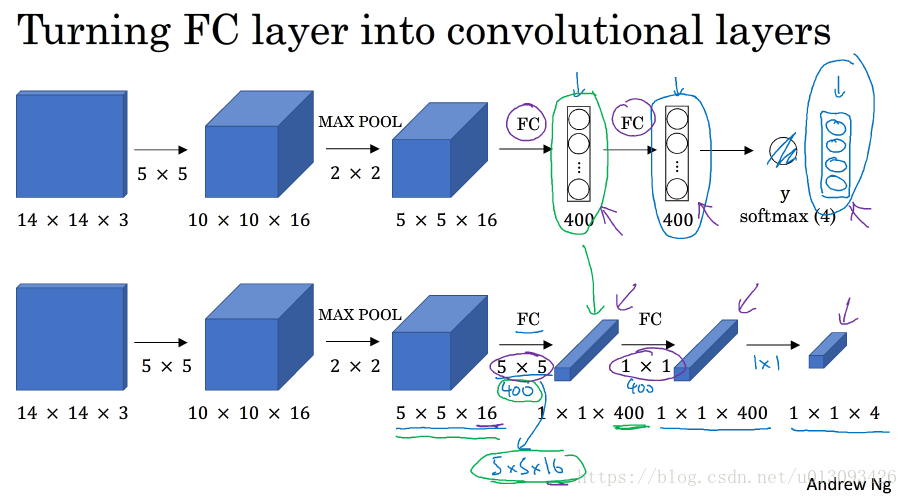
2.滑動視窗的卷積操作
在使用滑動視窗時,選取的各個 視窗元素之間有大量重合的地方,但是如果我們將思路稍加轉變,則可以大大減少重複的資料,見下圖:
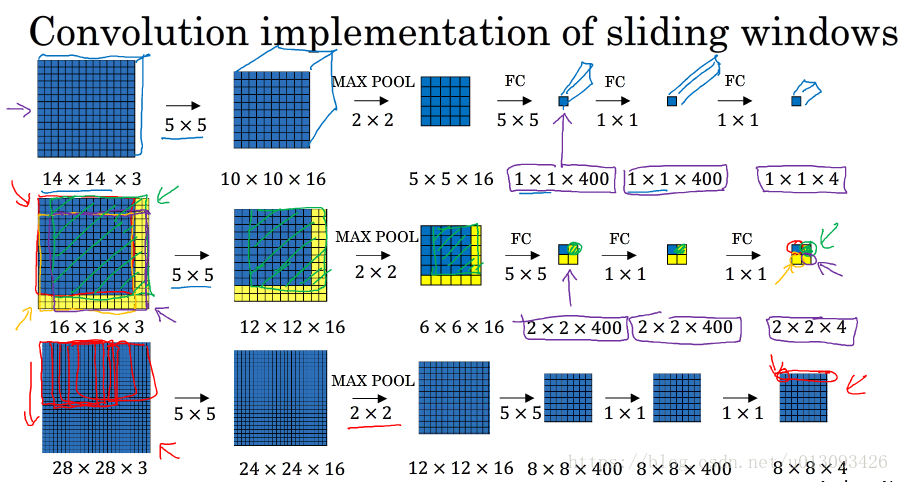
3.缺點:
邊界框的位置可能不夠準確
3.5bounding box預測
1.輸出更精確的邊界框
(1)YOLO演算法
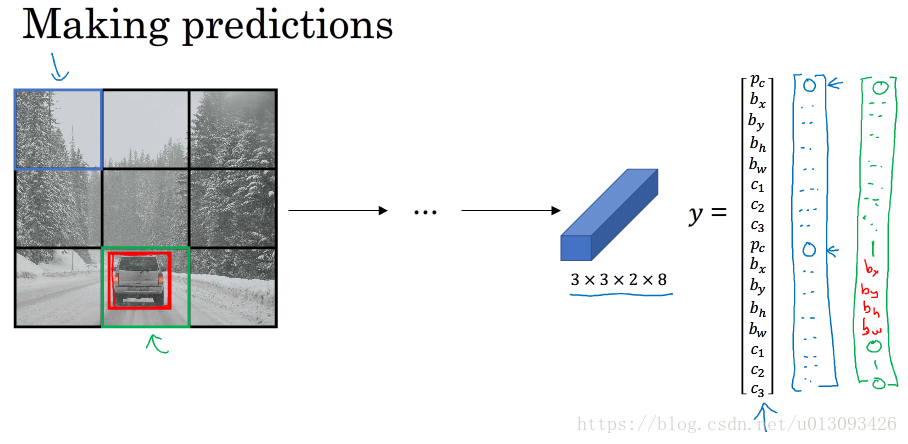
YOLO是一個卷積實現,運算速度非常高,基本可以進行實時識別。在實現過程中,YOLO演算法將輸入影象分成nxn個小圖,然後使用一個卷積網路對這n^2個影象進行識別,最後輸出為nxnx8,因為y = [P_c, b_x, b_y, b_w, b_h, C1, C2, C3].T
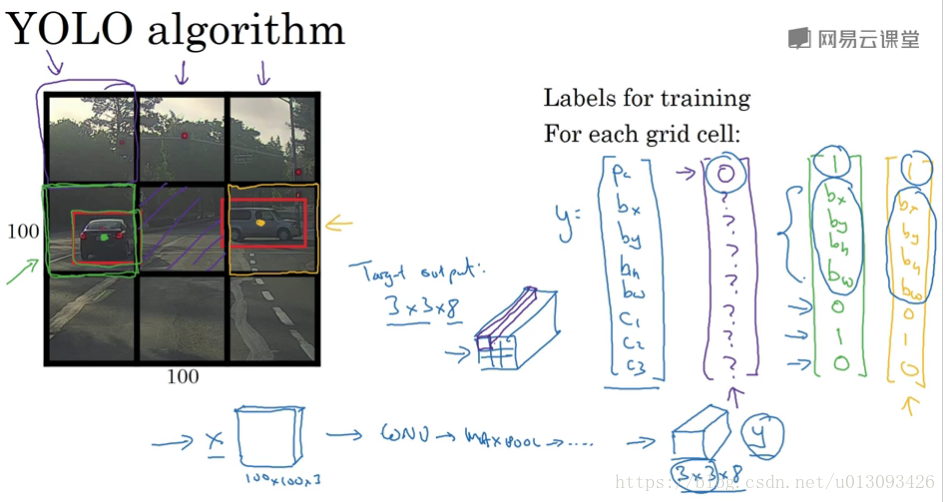
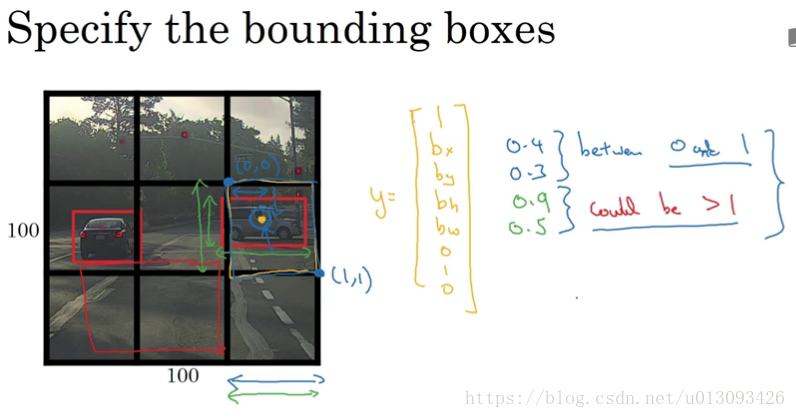
在確定 b_x, b_y, b_w, b_h的原則如下:b_x, b_y的確定以該目標所在單元格為準,其值小於1;b_w, b_h按照與單元格比例,其值可大於1.
3.6交併比(intersection over unit:IOU)
1.作用:評估目標定位演算法的優劣, 計算目標實際邊框與檢測出的邊框的交集和並集之比。一般計算機檢測出的IoU>=0.5,即可認為識別正確,當然0.5是人為約定的,如果想讓結果更嚴格可以設定為0.6/0.7

3.7非極大值抑制
1.思路:對於同一個目標的不同檢測結果,只保留概率最大的而抑制其他檢測結果。

3.8Anchor boxes
1.作用:在一個格子包含多個物體時(即這些物體的中心點在同一個格子中),可以進行多個目標的檢測。

由於人和車的中心在同一個格子中,這時輸出y將無法使用y=[P_c, b_x, b_y, b_h, b_w, C1, C2, C3]表示。這時我們要使用anchor boxes演算法優化。
2.步驟:
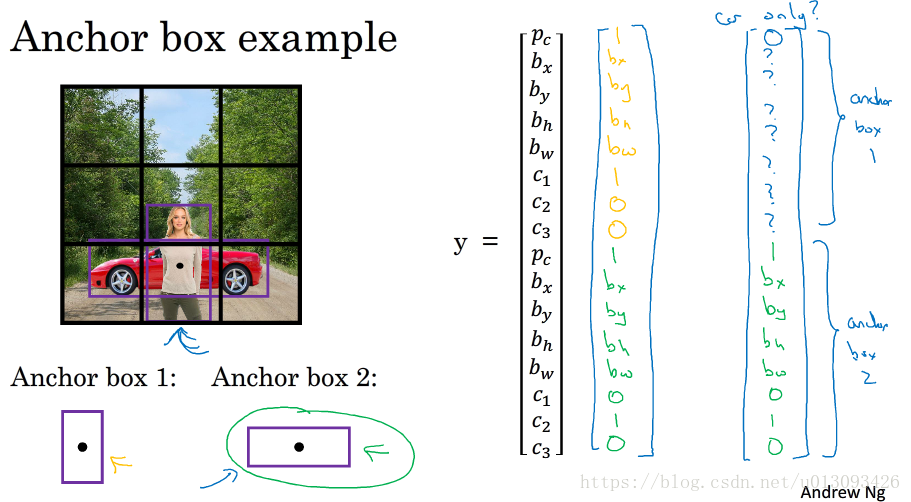
(1)預先定義兩個不同形狀的anchor1和anchor2(通常情況下可能需要更多,為了簡化此處只使用兩個)

(2)然後把預測結果和這兩個anchor box關聯起來,此時輸出y的形式為:
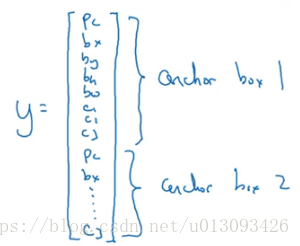
(3)因為行人的形狀與anchor1相似,因此使用anchor1的那組資料來編碼表示行人的邊界框;車子同理
3.特殊情況
(1)由於我們只設置了兩個anchor box因此當格子裡有三個物體時演算法不能很好的處理,
(2)另一種處理不好的情況是,兩個物體有相似的anchor 形狀
3.9 YOLO演算法
1.訓練,最終輸出的shape由識別的型別數量和anchor box數量共同決定
2.預測,對於P_c=0時的處理,可將其後資料當做噪音處理
3.對輸出使用非最大值抑制

3.10RPN網路
1.區域方案:R-CNN詳解(帶區域的卷積神經網路)
用以解決使用滑動視窗檢測時出現的在沒有任何物件的區域浪費時間的問題, 該演算法嘗試選出一些區域,在這些區域中應用卷積網路分類器是有意義的,從而使滑動視窗檢測不再對每一個視窗應用,而是隻針對選出的區域進行檢測。選擇的方法是對影象執行“影象分割演算法”
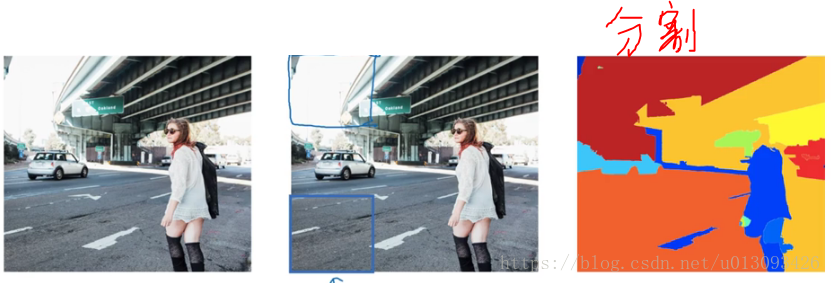
在分割演算法處理後的影象中找出一些“色塊”,比如圖中的藍色或綠色色塊,然後選出這些色塊跑一次分類器。

這樣需要分類器處理的位置會相對減少很多,可以減少執行時間, 而且還有的好處是,這種演算法中我們不侷限於視窗選擇出的正方形區域,我們還可以檢測出高瘦不等的區域,這樣更有利於我們識別人物這樣的分類。
2.快速 RCNN
R-CNN:輸出標籤和邊界框,在此R-CNN不會直接信任輸入的邊界框,它會自己輸出一個bounding box(b_x, b_y, b_h,b_w)這樣的邊界框比單純使用影象分割演算法給出的邊界框更精確些,但R-CNN的缺點是太慢了
Fast RCNN:用卷積代替滑動視窗,該演算法加快的滑動視窗的過程,但是整體的速度還是不理想
Faster RCNN:使用卷積神經網路代替傳統的分割法來選擇色塊,不過相比於YOLO還是稍慢(因為YOLO只需要一步檢測,而Faster RCNN要分兩個:選定區域,分類識別)
