
自己動手實現java資料結構(五)雜湊表
1.雜湊表介紹
前面我們已經介紹了許多型別的資料結構。在想要查詢容器內特定元素時,有序向量使得我們能使用二分查詢法進行精確的查詢((O(logN)對數複雜度,很高效)。
可人類總是不知滿足,依然在尋求一種更高效的特定元素查詢的資料結構,雜湊表/散列表(hash table)就應運而生啦。雜湊表在特定元素的插入,刪除和查詢時都能夠達到O(1)常數的時間複雜度,十分高效。
1.1 雜湊演算法
雜湊演算法的定義:把任意長度的輸入通過雜湊演算法轉換對映為固定長度的輸出,所得到的輸出被稱為雜湊值(hashCode = hash(input))。雜湊對映是一種多對一的關係,即多個不同的輸入有可能對應著一個相同的雜湊值輸出;也意味著,雜湊對映是不可逆,無法還原的。
舉個例子:我們有一個好朋友叫熊大,大家都叫他老熊。可以理解為是一個hash演算法:對於一個人名,我們一般稱呼為"老" + 姓氏(單姓) (hash(熊大) = 老熊)。同時,我們還有一個好朋友叫熊二,我們也叫他老熊(hash(熊二) = 老熊)。當熊大和熊二兩個好朋友同時和我們聚會時,都稱呼他們為老熊就不太合適啦,因為這時出現了hash衝突。老熊這個稱呼同時對應了多個人,多個不同的輸入對應了相同的雜湊值輸出。
java在Object這一最高層物件中實現了hashCode方法,並允許子類重寫更適應自身,衝突概率更低的hashCode方法。
1.2 雜湊表實現的基本思路
雜湊表儲存的是key-value鍵值對
由於採用hash演算法會出現hash衝突,一個數組下標對應了多個元素。常見的解決hash衝突的方法有:開放地址法、重新雜湊法、拉鍊法等等,我們的雜湊表實現採用的是拉鍊法解決hash衝突。
採用拉鍊法的雜湊表將內部陣列的每一個元素視為一個插槽(slot)或者桶(bucket),並將資料存放在鍵值對節點(EntryNode)中。EntryNode除了存放key和value,還維護著一個next節點的引用。為了解決hash衝突,單個插槽內的多個EntryNode構成一個簡單的單向連結串列,插槽指向連結串列的頭部節點,新的資料將會插入當前連結串列的尾部。
key值不同但對映的hash值相同的元素在雜湊表的同一個插槽中以連結串列的形式共存。
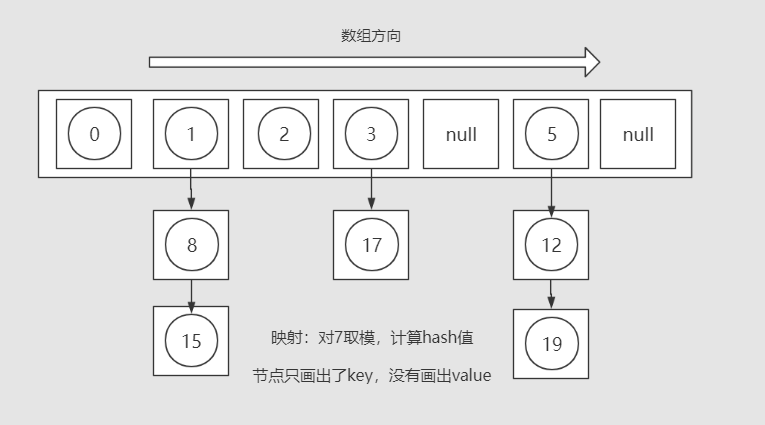
1.3 雜湊表的負載因子(loadFactor):
雜湊表在查詢資料時通過直接計算資料hash值對應的插槽,迅速獲取到key值對應的資料,進行非常高效的資料查詢。
但依然存在一個問題:雖然設計良好的hash函式可以儘可能的降低hash衝突的概率,但hash衝突還是不可避免的。當發生頻繁的雜湊衝突時,對應的插槽內可能會存放較多的元素,導致插槽內的連結串列資料過多。而連結串列的查詢效率是非常低的,在極端情況下,甚至會出現所有元素都對映存放在同一個插槽內,此時的雜湊表退化成了一個連結串列,查詢效率急劇降低。
一般的,雜湊表儲存的資料量一定時,內部陣列的大小和陣列插槽指向的連結串列長度成反比。換句話說,總資料量一定,內部陣列的容量越大(插槽越多),平均下來桶連結串列的長度也就越小,查詢效率越高。
同等資料量下,雜湊表內部陣列容量越大,查詢效率越高,但同時空間佔用也越高,這本質上是一個空間換時間的取捨。
雜湊表允許使用者在初始化時指定負載因子(loadFactor):負載因子代表著儲存的總資料量和內部陣列大小的比值。插入新資料時,判斷雜湊表當前的儲存量和內部陣列的比值是否超過了負載因子。當比值超過了負載因子時,雜湊表認為內部過於擁擠,查詢效率太低,會觸發一次擴容的rehash操作。rehash會對內部陣列擴容,將儲存的元素重新進行hash對映,使得雜湊表始終保持一個合適的查詢效率。
通過指定自定義的負載因子,使用者可以控制雜湊表在空間和時間上取捨的程度,使雜湊表能更有效地適應使用者的使用場景。
指定的負載因子越大,雜湊表越擁擠(負載高,緊湊),查詢效率越低,空間效率越高。
指定的負載因子越小,雜湊表越稀疏(負載小,鬆散),查詢效率越高,空間效率越低。
2.雜湊表ADT介面
和之前介紹的連結串列不同,我們在雜湊表的ADT介面中暴露出了雜湊表內部實現的EntryNode鍵值對節點。通過暴露出去的public方法,使用者在使用雜湊表時,可以獲得內部的鍵值對節點,靈活的訪問其中的key、value資料(但沒有暴露setKey方法,不允許使用者自己設定key值)。
public interface Map <K,V>{ /** * 存入鍵值對 * @param key key值 * @param value value * @return 被覆蓋的的value值 */ V put(K key,V value); /** * 移除鍵值對 * @param key key值 * @return 被刪除的value的值 */ V remove(K key); /** * 獲取key對應的value值 * @param key key值 * @return 對應的value值 */ V get(K key); /** * 是否包含當前key值 * @param key key值 * @return true:包含 false:不包含 */ boolean containsKey(K key); /** * 是否包含當前value值 * @param value value值 * @return true:包含 false:不包含 */ boolean containsValue(V value); /** * 獲得當前map儲存的鍵值對數量 * @return 鍵值對數量 * */ int size(); /** * 當前map是否為空 * @return true:為空 false:不為空 */ boolean isEmpty(); /** * 清空當前map */ void clear(); /** * 獲得迭代器 * @return 迭代器物件 */ Iterator<EntryNode<K,V>> iterator(); /** * 鍵值對節點 內部類 * */ class EntryNode<K,V>{ final K key; V value; EntryNode<K,V> next; EntryNode(K key, V value) { this.key = key; this.value = value; } boolean keyIsEquals(K key){ if(this.key == key){ return true; } if(key == null){ //:::如果走到這步,this.key不等於null,不匹配 return false; }else{ return key.equals(this.key); } } EntryNode<K, V> getNext() { return next; } void setNext(EntryNode<K, V> next) { this.next = next; } public K getKey() { return key; } public V getValue() { return value; } public void setValue(V value) { this.value = value; } @Override public String toString() { return key + "=" + value; } } }
3.雜湊表實現細節
3.1 雜湊表基本屬性:
public class HashMap<K,V> implements Map<K,V>{ /** * 內部陣列 * */ private EntryNode<K,V>[] elements; /** * 當前雜湊表的大小 * */ private int size; /** * 負載因子 * */ private float loadFactor; /** * 預設的雜湊表容量 * */ private final static int DEFAULT_CAPACITY = 16; /** * 擴容翻倍的基數 * */ private final static int REHASH_BASE = 2; /** * 預設的負載因子 * */ private final static float DEFAULT_LOAD_FACTOR = 0.75f; //========================================構造方法=================================================== /** * 預設構造方法 * */ @SuppressWarnings("unchecked") public HashMap() { this.size = 0; this.loadFactor = DEFAULT_LOAD_FACTOR; elements = new EntryNode[DEFAULT_CAPACITY]; } /** * 指定初始容量的構造方法 * @param capacity 指定的初始容量 * */ @SuppressWarnings("unchecked") public HashMap(int capacity) { this.size = 0; this.loadFactor = DEFAULT_LOAD_FACTOR; elements = new EntryNode[capacity]; } /** * 指定初始容量和負載因子的構造方法 * @param capacity 指定的初始容量 * @param loadFactor 指定的負載因子 * */ @SuppressWarnings("unchecked") public HashMap(int capacity,int loadFactor) { this.size = 0; this.loadFactor = loadFactor; elements = new EntryNode[capacity]; } }
3.2 通過hash值獲取對應插槽下標:
獲取hash的方法僅和資料自身有關,不受到雜湊表儲存資料量的影響。
因此getIndex方法的時間複雜度為O(1)。
/** * 通過key的hashCode獲得對應的內部陣列下標 * @param key 傳入的鍵值key * @return 對應的內部陣列下標 * */ private int getIndex(K key){ return getIndex(key,this.elements); } /** * 通過key的hashCode獲得對應的內部陣列插槽slot下標 * @param key 傳入的鍵值key * @param elements 內部陣列 * @return 對應的內部陣列下標 * */ private int getIndex(K key,EntryNode<K,V>[] elements){ if(key == null){ //::: null 預設儲存在第0個桶內 return 0; }else{ int hashCode = key.hashCode(); //:::通過 高位和低位的異或運算,獲得最終的hash對映,減少碰撞的機率 int finalHashCode = hashCode ^ (hashCode >>> 16); return (elements.length-1) & finalHashCode; } }
3.3 連結串列查詢方法:
當出現hash衝突時,會在對應插槽處生成一個單鏈表。我們需要提供一個方便的單鏈表查詢方法,將增刪改查介面的部分公用邏輯抽象出來,簡化程式碼的複雜度。
值得注意的是:在判斷Key值是否相等時使用的是EntryNode.keyIsEquals方法,內部最終是通過equals方法進行比較的。也就是說,判斷key值是否相等和其它資料結構一樣,依然是由equals方法決定的。hashCode方法的作用僅僅是使我們能夠更快的定位到所對映的插槽處,加快查詢效率。
思考一下,為什麼要求在重寫equals方法的同時,也應該重寫hashCode方法?
/** * 獲得目標節點的前一個節點 * @param currentNode 當前桶連結串列節點 * @param key 對應的key * @return 返回當前桶連結串列中"匹配key的目標節點"的"前一個節點" * 注意:當桶連結串列中不存在匹配節點時,返回桶連結串列的最後一個節點 * */ private EntryNode<K,V> getTargetPreviousEntryNode(EntryNode<K,V> currentNode,K key){ //:::不匹配 EntryNode<K,V> nextNode = currentNode.next; //:::遍歷當前桶後面的所有節點 while(nextNode != null){ //:::如果下一個節點的key匹配 if(nextNode.keyIsEquals(key)){ return currentNode; }else{ //:::不斷指向下一個節點 currentNode = nextNode; nextNode = nextNode.next; } } //:::到達了桶連結串列的末尾,返回最後一個節點 return currentNode; }
3.4 增刪改查介面:
雜湊表的增刪改查介面都是通過hash值直接計算出對應的插槽下標(getIndex方法),然後遍歷插槽內的桶連結串列進行進一步的精確查詢(getTargetPreviousEntryNode方法)。在負載因子位於正常範圍內時(一般小於1),桶連結串列的平均長度非常短,可以認為單個桶連結串列的遍歷查詢時間複雜度為(O(1))。
因此雜湊表的增刪改查介面的時間複雜度都是O(1)。
@Override public V put(K key, V value) { if(needReHash()){ reHash(); } //:::獲得對應的內部陣列下標 int index = getIndex(key); //:::獲得對應桶內的第一個節點 EntryNode<K,V> firstEntryNode = this.elements[index]; //:::如果當前桶內不存在任何節點 if(firstEntryNode == null){ //:::建立一個新的節點 this.elements[index] = new EntryNode<>(key,value); //:::建立了新節點,size加1 this.size++; return null; } if(firstEntryNode.keyIsEquals(key)){ //:::當前第一個節點的key與之匹配 V oldValue = firstEntryNode.value; firstEntryNode.value = value; return oldValue; }else{ //:::不匹配 //:::獲得匹配的目標節點的前一個節點 EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key); //:::獲得匹配的目標節點 EntryNode<K,V> targetNode = targetPreviousNode.next; if(targetNode != null){ //:::更新value的值 V oldValue = targetNode.value; targetNode.value = value; return oldValue; }else{ //:::在桶連結串列的末尾 新增一個節點 targetPreviousNode.next = new EntryNode<>(key,value); //:::建立了新節點,size加1 this.size++; return null; } } } @Override public V remove(K key) { //:::獲得對應的內部陣列下標 int index = getIndex(key); //:::獲得對應桶內的第一個節點 EntryNode<K,V> firstEntryNode = this.elements[index]; //:::如果當前桶內不存在任何節點 if(firstEntryNode == null){ return null; } if(firstEntryNode.keyIsEquals(key)){ //:::當前第一個節點的key與之匹配 //:::將桶連結串列的第一個節點指向後一個節點(相容next為null的情況) this.elements[index] = firstEntryNode.next; //:::移除了一個節點 size減一 this.size--; //:::返回之前的value值 return firstEntryNode.value; }else{ //:::不匹配 //:::獲得匹配的目標節點的前一個節點 EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key); //:::獲得匹配的目標節點 EntryNode<K,V> targetNode = targetPreviousNode.next; if(targetNode != null){ //:::將"前一個節點的next" 指向 "目標節點的next" ---> 相當於將目標節點從桶連結串列移除 targetPreviousNode.next = targetNode.next; //:::移除了一個節點 size減一 this.size--; return targetNode.value; }else{ //:::如果目標節點為空,說明key並不存在於雜湊表中 return null; } } } @Override public V get(K key) { //:::獲得對應的內部陣列下標 int index = getIndex(key); //:::獲得對應桶內的第一個節點 EntryNode<K,V> firstEntryNode = this.elements[index]; //:::如果當前桶內不存在任何節點 if(firstEntryNode == null){ return null; } if(firstEntryNode.keyIsEquals(key)){ //:::當前第一個節點的key與之匹配 return firstEntryNode.value; }else{ //:::獲得匹配的目標節點的前一個節點 EntryNode<K,V> targetPreviousNode = getTargetPreviousEntryNode(firstEntryNode,key); //:::獲得匹配的目標節點 EntryNode<K,V> targetNode = targetPreviousNode.next; if(targetNode != null){ return targetNode.value; }else{ //:::如果目標節點為空,說明key並不存在於雜湊表中 return null; } } }
3.5 擴容rehash操作:
前面提到,當插入資料時發現雜湊表過於擁擠,超過了負載因子指定的值時,會觸發一次rehash擴容操作。
擴容時,我們的內部陣列擴容了2倍,所以對於每一個插槽內的元素在rehash時存在兩種可能:
1.依然對映到當前下標插槽處
2.對映到高位下標處(當前下標 + 擴容前內部陣列長度大小)
注意觀察0,4,8三個元素節點,在擴容前(對4取模)都位於下標0插槽;擴容後,陣列容量翻倍(對8取模),存在兩種情況,0,8兩個元素雜湊值依然對映在下標0插槽(低位插槽),而元素4則被對映到了下標4插槽(高位插槽)(當前下標(0) + 擴容前內部陣列長度大小(4))。
通過遍歷每個插槽,將內部元素按順序進行rehash,得到擴容兩倍後的雜湊表(資料保留了之前的順序,即先插入的節點依然位於桶連結串列靠前的位置)。
和向量擴容一樣,雖然rehash操作的時間複雜度為O(n)。但是由於只在插入時偶爾的被觸發,總體上看,rehash操作的時間複雜度為O(1)。
雜湊表擴容前:
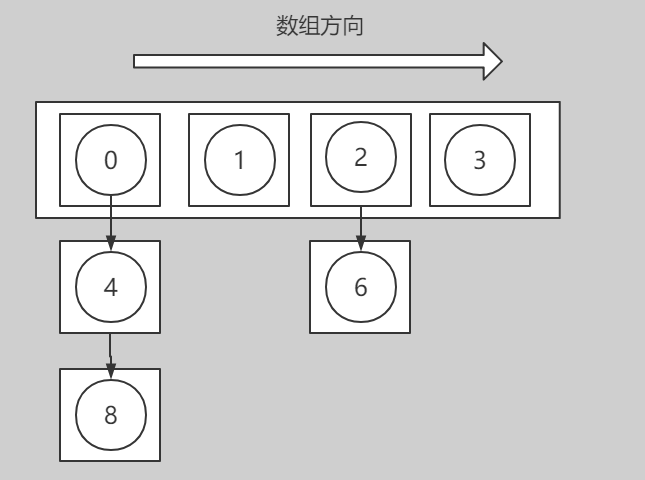
雜湊表擴容後:

/** * 雜湊表擴容 * */ @SuppressWarnings("unchecked") private void reHash(){ //:::擴容兩倍 EntryNode<K,V>[] newElements = new EntryNode[this.elements.length * REHASH_BASE]; //:::遍歷所有的插槽 for (int i=0; i<this.elements.length; i++) { //:::為單個插槽內的元素 rehash reHashSlot(i,newElements); } //:::內部陣列 ---> 擴容之後的新陣列 this.elements = newElements; } /** * 單個插槽內的資料進行rehash * */ private void reHashSlot(int index,EntryNode<K, V>[] newElements){ //:::獲得當前插槽第一個元素 EntryNode<K, V> currentEntryNode = this.elements[index]; if(currentEntryNode == null){ //:::當前插槽為空,直接返回 return; } //:::低位桶連結串列 頭部節點、尾部節點 EntryNode<K, V> lowListHead = null; EntryNode<K, V> lowListTail = null; //:::高位桶連結串列 頭部節點、尾部節點 EntryNode<K, V> highListHead = null; EntryNode<K, V> highListTail = null; while(currentEntryNode != null){ //:::獲得當前節點 在新陣列中對映的插槽下標 int entryNodeIndex = getIndex(currentEntryNode.key,newElements); //:::是否和當前插槽下標相等 if(entryNodeIndex == index){ //:::和當前插槽下標相等 if(lowListHead == null){ //:::初始化低位連結串列 lowListHead = currentEntryNode; lowListTail = currentEntryNode; }else{ //:::在低位連結串列尾部拓展新的節點 lowListTail.next = currentEntryNode; lowListTail = lowListTail.next; } }else{ //:::和當前插槽下標不相等 if(highListHead == null){ //:::初始化高位連結串列 highListHead = currentEntryNode; highListTail = currentEntryNode; }else{ //:::在高位連結串列尾部拓展新的節點 highListTail.next = currentEntryNode; highListTail = highListTail.next; } } //:::指向當前插槽的下一個節點 currentEntryNode = currentEntryNode.next; } //:::新擴容elements(index)插槽 存放lowList newElements[index] = lowListHead; //:::lowList末尾截斷 if(lowListTail != null){ lowListTail.next = null; } //:::新擴容elements(index + this.elements.length)插槽 存放highList newElements[index + this.elements.length] = highListHead; //:::highList末尾截斷 if(highListTail != null){ highListTail.next = null; } } /** * 判斷是否需要 擴容 * */ private boolean needReHash(){ return ((this.size / this.elements.length) > this.loadFactor); }
3.6 其它介面實現:
@Override public boolean containsKey(K key) { V value = get(key); return (value != null); } @Override public boolean containsValue(V value) { //:::遍歷全部桶連結串列 for (EntryNode<K, V> element : this.elements) { //:::獲得當前桶連結串列第一個節點 EntryNode<K, V> entryNode = element; //:::遍歷當前桶連結串列 while (entryNode != null) { //:::如果value匹配 if (entryNode.value.equals(value)) { //:::返回true return true; } else { //:::不匹配,指向下一個節點 entryNode = entryNode.next; } } } //:::所有的節點都遍歷了,沒有匹配的value return false; } @Override public int size() { return this.size; } @Override public boolean isEmpty() { return (this.size == 0); } @Override public void clear() { //:::遍歷內部陣列,將所有桶連結串列全部清空 for(int i=0; i<this.elements.length; i++){ this.elements[i] = null; } //:::size設定為0 this.size = 0; } @Override public Iterator<EntryNode<K,V>> iterator() { return new Itr(); } @Override public String toString() { Iterator<EntryNode<K,V>> iterator = this.iterator(); //:::空容器 if(!iterator.hasNext()){ return "[]"; } //:::容器起始使用"[" StringBuilder s = new StringBuilder("["); //:::反覆迭代 while(true){ //:::獲得迭代的當前元素 EntryNode<K,V> data = iterator.next(); //:::判斷當前元素是否是最後一個元素 if(!iterator.hasNext()){ //:::是最後一個元素,用"]"收尾 s.append(data).append("]"); //:::返回 拼接完畢的字串 return s.toString(); }else{ //:::不是最後一個元素 //:::使用", "分割,拼接到後面 s.append(data).append(", "); } } }
4.雜湊表迭代器
1. 由於雜湊表中資料分佈不是連續的,所以在迭代器的初始化過程中必須先跳轉到第一個非空資料節點,以避免無效的迭代。
2. 當迭代器的下標到達當前插槽連結串列的末尾時,迭代器下標需要跳轉到靠後插槽的第一個非空資料節點。
/** * 雜湊表 迭代器實現 */ private class Itr implements Iterator<EntryNode<K,V>> { /** * 迭代器 當前節點 * */ private EntryNode<K,V> currentNode; /** * 迭代器 下一個節點 * */ private EntryNode<K,V> nextNode; /** * 迭代器 當前內部陣列的下標 * */ private int currentIndex; /** * 預設構造方法 * */ private Itr(){ //:::如果當前雜湊表為空,直接返回 if(HashMap.this.isEmpty()){ return; } //:::在構造方法中,將迭代器下標移動到第一個有效的節點上 //:::遍歷內部陣列,找到第一個不為空的陣列插槽slot for(int i=0; i<HashMap.this.elements.length; i++){ //:::設定當前index this.currentIndex = i; EntryNode<K,V> firstEntryNode = HashMap.this.elements[i]; //:::找到了第一個不為空的插槽slot if(firstEntryNode != null){ //:::nextNode = 當前插槽第一個節點 this.nextNode = firstEntryNode; //:::構造方法立即結束 return; } } } @Override public boolean hasNext() { return (this.nextNode != null); } @Override public EntryNode<K,V> next() { this.currentNode = this.nextNode; //:::暫存需要返回的節點 EntryNode<K,V> needReturn = this.nextNode; //:::nextNode指向自己的next this.nextNode = this.nextNode.next; //:::判斷當前nextNode是否為null if(this.nextNode == null){ //:::說明當前所在的桶連結串列已經遍歷完畢 //:::尋找下一個非空的插槽 for(int i=this.currentIndex+1; i<HashMap.this.elements.length; i++){ //:::設定當前index this.currentIndex = i; EntryNode<K,V> firstEntryNode = HashMap.this.elements[i]; //:::找到了後續不為空的插槽slot if(firstEntryNode != null){ //:::nextNode = 當前插槽第一個節點 this.nextNode = firstEntryNode; //:::跳出迴圈 break; } } } return needReturn; } @Override public void remove() { if(this.currentNode == null){ throw new IteratorStateErrorException("迭代器狀態異常: 可能在一次迭代中進行了多次remove操作"); } //:::獲得需要被移除的節點的key K currentKey = this.currentNode.key; //:::將其從雜湊表中移除 HashMap.this.remove(currentKey); //:::currentNode設定為null,防止反覆呼叫remove方法 this.currentNode = null; } }
5.雜湊表效能
5.1 空間效率:
雜湊表的空間效率很大程度上取決於負載因子。通常,為了保證雜湊表查詢的高效性,負載因子都設定的比較小(小於1),因而可能會出現許多空的插槽,浪費空間。
總體而言,雜湊表的空間效率低於向量和連結串列。
5.2 時間效率:
一般的,雜湊表增刪改查介面的時間複雜度都是O(1)。但是出現較多的hash衝突時,衝突範圍內的key的增刪改查效率較低,時間效率會有一定的波動。
總體而言,雜湊表的時間效率高於向量和連結串列。
雜湊表的時間效率很高,可天下沒有免費的午餐,據統計,雜湊表的空間利用率通常情況下還不到50%。
雜湊表是一個使用空間來換取時間的資料結構,對查詢效能有較高要求的場合,可以考慮使用雜湊表。
6.雜湊表總結
6.1 當前版本缺陷
至此,我們已經實現了一個基礎的雜湊表,但還存在許多明顯缺陷:
1.當hash衝突比較頻繁時,查詢效率急劇降低。
jdk在1.8版本的雜湊表實現(java.util.HashMap)中,對這一場景進行了優化。當內部桶連結串列的節點個數超過一定數量(預設為8)時,會將插槽中的桶連結串列轉換成一個紅黑樹(查詢效率為O(logN))。
2.不支援多執行緒
在多執行緒的環境,併發的訪問一個雜湊表會導致諸如:擴容時內部節點死迴圈、丟失插入資料等異常情況。
6.2 查詢特定元素的方法
我們目前查詢特定元素有幾種不同的方法:
1.順序查詢
在無序向量或者連結串列中,查詢一個特定元素是通過從頭到尾遍歷容器內元素的方式實現的,執行速度正比於資料量的大小,順序查詢的時間複雜度為O(n),效率較低。
2.二分查詢
在有序向量以及後面要介紹的二叉搜尋樹中,由於容器內部的元素是有序的,因此可以通過二分查詢比較的方式查詢特定的元素,二分查詢的時間複雜度為O(logN),效率較高。
3.雜湊查詢
在雜湊表中,通過直接計算出資料hash值對應的插槽(slot)(時間複雜度O(1)),查找出對應的資料,雜湊查詢的時間複雜度為O(1),效率極高。
特定元素的查詢方式和排序演算法的關係
1.順序查詢對應氣泡排序、選擇排序等,效率較低,時間複雜度(O(n²))。
2.二分查詢對應快速排序、歸併排序等,效率較高,時間複雜度(O(nLogn))。
3.雜湊查詢對應基排序,效率極高,時間複雜度(O(n))。
在大牛劉未鵬的部落格中有更為詳細的說明,http://mindhacks.cn/2008/06/13/why-is-quicksort-so-quick。
6.3 完整程式碼
雜湊表ADT介面:


1 public interface Map <K,V>{ 2 /** 3 * 存入鍵值對 4 * @param key key值 5 * @param value value 6 * @return 被覆蓋的的value值 7 */ 8 V put(K key,V value); 9 10 /** 11 * 移除鍵值對 12 * @param key key值 13 * @return 被刪除的value的值 14 */ 15 V remove(K key); 16 17 /** 18 * 獲取key對應的value值 19 * @param key key值 20 * @return 對應的value值 21 */ 22 V get(K key); 23 24 /** 25 * 是否包含當前key值 26 * @param key key值 27 * @return true:包含 false:不包含 28 */ 29 boolean containsKey(K key); 30 31 /** 32 * 是否包含當前value值 33 * @param value value值 34 * @return true:包含 false:不包含 35 */ 36 boolean containsValue(V value); 37 38 /** 39 * 獲得當前map儲存的鍵值對數量 40 * @return 鍵值對數量 41 * */ 42 int size(); 43 44 /** 45 * 當前map是否為空 46 * @return true:為空 false:不為空 47 */ 48 boolean isEmpty(); 49 50 /** 51 * 清空當前map 52 */ 53 void clear(); 54 55 /** 56 * 獲得迭代器 57 * @return 迭代器物件 58 */ 59 Iterator<EntryNode<K,V>> iterator(); 60 61 /** 62 * 鍵值對節點 內部類 63 * */ 64 class EntryNode<K,V>{ 65 final K key; 66 V value; 67 EntryNode<K,V> next; 68 69 EntryNode(K key, V value) { 70 this.key = key; 71 this.value = value; 72 } 73 74 boolean keyIsEquals(K key){ 75 if(this.key == key){ 76 return true; 77 } 78 79 if(key == null){ 80 //:::如果走到這步,this.key不等於null,不匹配 81 return false; 82 }else{ 83 return key.equals(this.key); 84 } 85 } 86 87 EntryNode<K, V> getNext() { 88 return next; 89 } 90 91 void setNext(EntryNode<K, V> next) { 92 this.next = next; 93 } 94 95 public K getKey() { 96 return key; 97 } 98 99 public V getValue() { 100 return value; 101 } 102 103 public void setValue(V value) { 104 this.value = value; 105 } 106 107 @Override 108 public String toString() { 109 return key + "=" + value; 110 } 111 } 112 }View Code
雜湊表實現:
1 public class HashMap<K,V> implements Map<K,V>{ 2 3 //===========================================成員屬性================================================ 4 /** 5 * 內部陣列 6 * */ 7 private EntryNode<K,V>[] elements; 8 9 /** 10 * 當前雜湊表的大小 11 * */ 12 private int size; 13 14 /** 15 * 負載因子 16 * */ 17 private float loadFactor; 18 19 /** 20 * 預設的雜湊表容量 21 * */ 22 private final static int DEFAULT_CAPACITY = 16; 23 24 /** 25 * 擴容翻倍的基數 兩倍 26 * */ 27 private final static int REHASH_BASE = 2; 28 29 /** 30 * 預設的負載因子 31 * */ 32 private final static float DEFAULT_LOAD_FACTOR = 0.75f; 33 34 //========================================構造方法=================================================== 35 /** 36 * 預設構造方法 37 * */ 38 @SuppressWarnings("unchecked") 39 public HashMap() { 40 this.size = 0; 41 this.loadFactor = DEFAULT_LOAD_FACTOR; 42 elements = new EntryNode[DEFAULT_CAPACITY]; 43 } 44 45 /** 46 * 指定初始容量的構造方法 47 * @param capacity 指定的初始容量 48 * */ 49 @SuppressWarnings("unchecked") 50 public HashMap(int capacity) { 51 this.size = 0; 52 this.loadFactor = DEFAULT_LOAD_FACTOR; 53 elements = new EntryNode[capacity]; 54 } 55 56 /** 57 * 指定初始容量和負載因子的構造方法 58 * @param capacity 指定的初始容量 59 * @param loadFactor 指定的負載因子 60 * */ 61 @SuppressWarnings("unchecked") 62 public HashMap(int capacity,int loadFactor) { 63 this.size = 0; 64 this.loadFactor = loadFactor; 65 elements = new EntryNode[capacity]; 66 } 67 68 //==========================================內部輔助方法============================================= 69 /** 70 * 通過key的hashCode獲得對應的內部陣列下標 71 * @param key 傳入的鍵值key 72 * @return 對應的內部陣列下標 73 * */ 74 private int getIndex(K key){ 75 return getIndex(key,this.elements); 76 } 77 78 /** 79 * 通過key的hashCode獲得對應的內部陣列插槽slot下標 80 * @param key 傳入的鍵值key 81 * @param elements 內部陣列 82 * @return 對應的內部陣列下標 83 * */ 84 private int getIndex(K key,EntryNode<K,V>[] elements){ 85 if(key == null){ 86 //::: null 預設儲存在第0個桶內 87 return 0; 88 }else{ 89 int hashCode = key.hashCode(); 90 91 //:::通過 高位和低位的異或運算,獲得最終的hash對映,減少碰撞的機率 92 int finalHashCode = hashCode ^ (hashCode >>> 16); 93 return (elements.length-1) & finalHashCode; 94 } 95 } 96 97 /** 98 * 獲得目標節點的前一個節點 99 * @param currentNode 當前桶連結串列節點 100 * @param key 對應的key 101 * @return 返回當前桶連結串列中"匹配key的目標節點"的"前一個節點" 102 * 注意:當桶連結串列中不存在匹配節點時,返回桶連結串列的最後一個節點 103 * */ 104 private EntryNode<K,V> getTargetPreviousEntryNode(EntryNode<K,V> currentNode,K key){ 105 //:::不匹配 106 EntryNode<K,V> nextNode = currentNode.next; 107 //:::遍歷當前桶後面的所有節點 108 while(nextNode != null){ 109 //:::如果下一個節點的key匹配 110 if(nextNode.keyIsEquals(key)){ 111 return currentNode; 112 }else{ 113 //:::不斷指向下一個節點 114 currentNode = nextNode; 115 nextNode = nextNode.next; 116 } 117 } 118 119 //:::到達了桶連結串列的末尾,返回最後一個節點 120 return currentNode; 121 } 122 123 /** 124 * 雜湊表擴容 125 * */ 126 @SuppressWarnings("unchecked") 127 private void reHash(){ 128 //:::擴容兩倍 129 EntryNode<K,V>[] newElements = new EntryNode[this.elements.length * REHASH_BASE]; 130 131 //:::遍歷所有的插槽 132 for (int i=0; i<this.elements.length; i++) { 133 //:::為單個插槽內的元素 rehash 134 reHashSlot(i,newElements); 135 } 136 137 //:::內部陣列 ---> 擴容之後的新陣列 138 this.elements = newElements; 139 } 140 141 /** 142 * 單個插槽內的資料進行rehash 143 * */ 144 private void reHashSlot(int index,EntryNode<K, V>[] newElements){ 145 //:::獲得當前插槽第一個元素 146 EntryNode<K, V> currentEntryNode = this.elements[index]; 147 if(currentEntryNode == null){ 148 //:::當前插槽為空,直接返回 149 return; 150 } 151 152 //:::低位桶連結串列 頭部節點、尾部節點 153 EntryNode<K, V> lowListHead = null; 154 EntryNode<K, V> lowListTail = null; 155 //:::高位桶連結串列 頭部節點、尾部節點 156 EntryNode<K, V> highListHead = null; 157 EntryNode<K, V> highListTail = null; 158 159 while(currentEntryNode != null){ 160 //:::獲得當前節點 在新陣列中對映的插槽下標 161 int entryNodeIndex = getIndex(currentEntryNode.key,newElements); 162 //:::是否和當前插槽下標相等 163 if(entryNodeIndex == index){ 164 //:::和當前插槽下標相等 165 if(lowListHead == null){ 166 //:::初始化低位連結串列 167 lowListHead = currentEntryNode; 168 lowListTail = currentEntryNode; 169 }else{ 170 //:::在低位連結串列尾部拓展新的節點 171 lowListTail.next = currentEntryNode; 172 lowListTail = lowListTail.next; 173 } 174 }else{ 175 //:::和當前插槽下標不相等 176 if(highListHead == null){ 177 //:::初始化高位連結串列 178 highListHead = currentEntryNode; 179 highListTail = currentEntryNode; 180 }else{ 181 //:::在高位連結串列尾部拓展新的節點 182 highListTail.next = currentEntryNode; 183 highListTail = highListTail.next; 184 } 185 }