
線性表資料結構解讀(五)雜湊表結構-HashMap
前面的部落格中,我給大家分析過陣列和連結串列兩種線性表資料結構。陣列儲存區間連續,查詢方便,但是插入和刪除效率低下;連結串列儲存區間離散,插入刪除方便,但是查詢困難。大家肯定會問,有沒有一種結構,既能做到查詢便捷,又能做到插入刪除方便呢?答案就是我們今天要跟大家說的主角:雜湊表。
我們先來看一下雜湊表的百度定義
散列表(Hash table,也叫雜湊表),是根據關鍵碼值(Keyvalue)而直接進行訪問的資料結構。也就是說,它通過把關鍵碼值對映到表中一個位置來訪問記錄,以加快查詢的速度。這個對映函式叫做雜湊函式,存放記錄的陣列叫做散列表。
給定表M,存在函式f(key),對任意給定的關鍵字值key,代入函式後若能得到包含該關鍵字的記錄在表中的地址,則稱表M為雜湊(Hash)表,函式f(key)為雜湊(Hash)函式。
下圖是一個經典的雜湊表實現方式圖,來自百度百科。
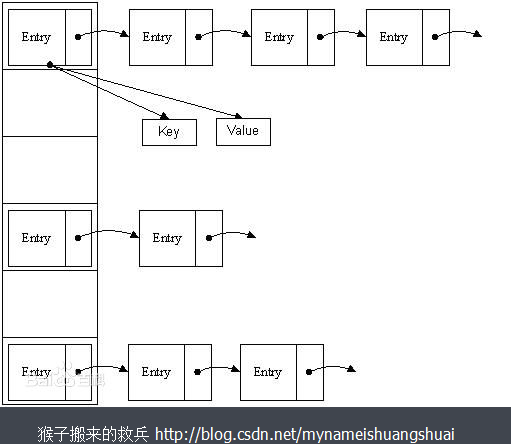
再看一張圖
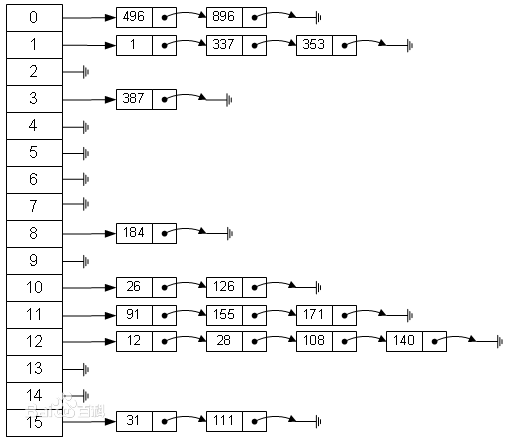
這張圖更明顯的告訴我們雜湊表採用的是一種“拉鍊法”實現的,關於拉鍊法,大家可以自行百度腦補。左邊是陣列,右邊是連結串列,感覺十分像用陣列把連結串列串起來,在一個長度為16的陣列中,每個元素儲存的是一個連結串列的頭結點。接下來我們一起來分析一下HashMap的原始碼實現。
HashMap的繼承關係

通過HashMap的繼承關係,我們可以得知HashMap繼承自抽象類AbstractMap,該Map又實現了Map介面,我們下來看一下Map介面包含哪些方法。
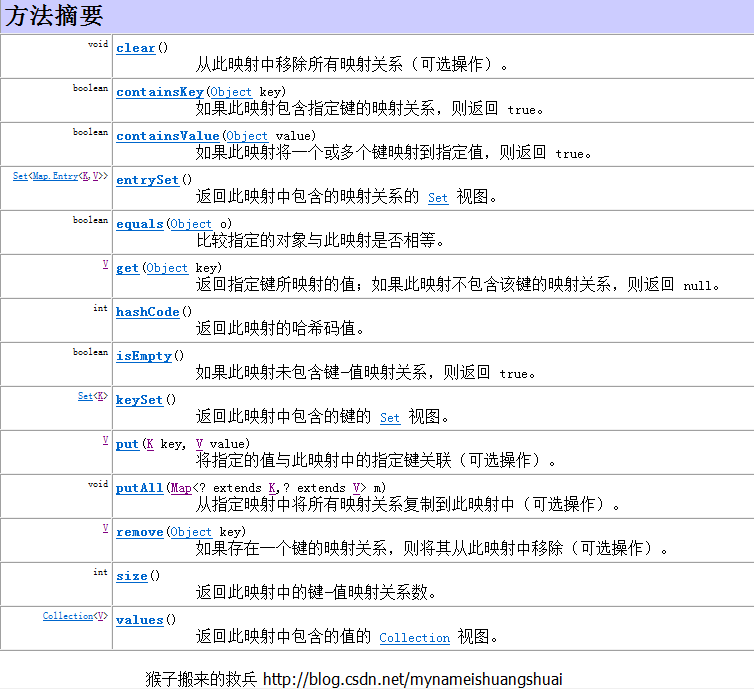
可以看出包含了我們常用的HashMap中的一些方法,接著我們來看HashMap的父類AbstractMap。
public abstract class AbstractMap<K, V> implements Map<K, V> {
// 用懶載入的方式定義了Set集合型別的鍵,表明HashMap鍵是不能重複的
Set<K> keySet;
// 用懶載入的方式定義了Collection集合型別的值,表明HashMap值是可以重複的
Collection<V> valuesCollection;
……
}這裡重點要看明白一開始定義的鍵和值,鍵是不能重複的,值可以重複。
然後定義了兩個靜態的實體類
// 維護鍵和值的 Entry 繼續下面實現了介面Map中的方法:clear、put、get、equals、size、hashCode等等。
HashMap原始碼解析
現在我們開始分析HashMap的原始碼,走起┏ (゜ω゜)=☞
元素定義
private static final int MINIMUM_CAPACITY = 4;// HashMap最小容量為4
private static final int MAXIMUM_CAPACITY = 1 << 30;// HashMap最大容量1073741824,往右移除2,往左移是乘2
// 實體陣列
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];// 一個空的鍵值對實體陣列最小容量是2
static final float DEFAULT_LOAD_FACTOR = .75F;// 預設的容量擴充套件因子是0.75
transient HashMapEntry<K, V>[] table;// 鍵值對的陣列
transient HashMapEntry<K, V> entryForNullKey;// 沒有鍵的鍵值對
transient int size;// 非空元素長度
transient int modCount;// 計數器
private transient int threshold;// 容量因子的極限
// Views - lazily initialized 父類繼承下來的
private transient Set<K> keySet;
private transient Set<Entry<K, V>> entrySet;
private transient Collection<V> values;構造方法
/**
* Constructs a new empty {@code HashMap} instance.
*/
@SuppressWarnings("unchecked")
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}
/**
* 指定初始容量的構造方法
*/
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}
/**
* 指定初始容量和擴充套件因子的構造方法
*/
public HashMap(int capacity, float loadFactor) {
this(capacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("Load factor: " + loadFactor);
}
/*
* Note that this implementation ignores loadFactor; it always uses
* a load factor of 3/4. This simplifies the code and generally
* improves performance.
*/
}
/**
* 構造一個對映關係與指定 Map 相同的新 HashMap。所建立的 HashMap 具有預設載入因子 (0.75) 和足 以容納指定 Map 中對映關係的初始容量。
*/
public HashMap(Map<? extends K, ? extends V> map) {
this(capacityForInitSize(map.size()));
constructorPutAll(map);
}put方法
/**
* Maps the specified key to the specified value.
* @param key the key.
* @param value the value.
* @return the value of any previous mapping with the specified key or
* {@code null} if there was no such mapping.
*/
@Override
public V put(K key, V value) {
if (key == null) {// HashMap的key是可以為空的,如果為空,放一個NullKey
return putValueForNullKey(value);
}
// 定義一個int型的hash,將key的hashCode計算後再次得到Hash值賦予它,即二次雜湊
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;// 儲存鍵值對的陣列
// index是下標,tab陣列長度-1即陣列下標最大值,接著做&運算得到下標最大的長度,避免溢位
int index = hash & (tab.length - 1);
// 遍歷索引下面的整個連結串列,tab[index]整個連結串列的頭結點,如果index索引處的Entry不為 null,通過迴圈不斷遍歷e元素的下一個元素
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
// 如果指定key與需要放入的key兩個鍵相同,進行覆蓋,新的覆蓋老的
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// 如果index索引處的Entry為null,表明此處還沒有 Entry
modCount++;// 計數器++
if (size++ > threshold) {// 尺寸++大於容量因子的極限,則擴容
tab = doubleCapacity();// 容量擴大兩倍,HashMap容量最小是4,然後兩倍兩倍的擴容
index = hash & (tab.length - 1);// 重新計算一遍
}
addNewEntry(key, value, hash, index);// 把新的鍵值對新增進來
return null;
}Hash相同,Key不一定相同,如果Key相同,Hash值一定相同。
總結put方法的基本過程如下:
(1)對key的hashcode進行二次hash計算,獲取應該儲存到陣列中的index。
(2)判斷index所指向的陣列元素是否為空,如果為空則直接插入。
(3)如果不為空,則依次查詢e中next所指定的元素,判讀key是否相等,如果相等,則替換舊的值,並返回值。
(4)跳出迴圈,判斷容量是否超出,如果超出進行擴容
(5)執行addNewEntry()新增方法;
get方法
/**
* Returns the value of the mapping with the specified key.
* @param key the key.
* @return the value of the mapping with the specified key, or {@code null}
* if no mapping for the specified key is found.
*/
public V get(Object key) {
if (key == null) {// 如果key為空,把entryForNullKey賦值給e
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
// 根據key的hashCode值計算它的hash碼
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
// 直接取出tab陣列中指定索引處的值
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
//拿到每一個鍵值對中的key
K eKey = e.key;
// 去比較,如果兩個key相等 或者 記憶體地址相等並且兩個雜湊值相等,則找到並返回值
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}remove方法
/**
* Removes the mapping with the specified key from this map.
* @param key the key of the mapping to remove.
* @return the value of the removed mapping or {@code null} if no mapping
* for the specified key was found.
*/
@Override public V remove(Object key) {
if (key == null) {// 如果key等於空,則移除空鍵值對
return removeNullKey();
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
// 遍歷全部結點
for (HashMapEntry<K, V> e = tab[index], prev = null;
e != null; prev = e, e = e.next) {
// 找到結點,如果Hash相等,並且key相等,找到了我們要移除的結點
if (e.hash == hash && key.equals(e.key)) {
if (prev == null) {// 遍歷到最後結束時找到要刪除的結點
tab[index] = e.next;// 頭結點從第二個結點開始算起
} else {// 在中間任意地方找到了我們要刪除的元素
prev.next = e.next;// 這裡使用了連結串列刪除元素的套路
}
modCount++;
size--;
postRemove(e);
return e.value;
}
}
return null;
}