使用Faster-Rcnn進行目標檢測
Object Detection發展介紹
Faster rcnn是用來解決計算機視覺(CV)領域中Object Detection的問題的。經典的解決方案是使用: SS(selective search)產生proposal,之後使用像SVM之類的classifier進行分類,得到所有可能的目標.
使用SS的一個重要的弊端就是:特別耗時,而且使用像傳統的SVM之類的淺層分類器,效果不佳。
鑑於神經網路(NN)的強大的feature extraction特徵,可以將目標檢測的任務放到NN上面來做,使用這一思想的目標檢測的代表是:
RCNN Fast-RCNN到Faster-RCNN YOLO
簡單點說就是:
- RCNN 解決的是,“為什麼不用CNN做detection呢?”
- Fast-RCNN 解決的是,“為什麼不一起輸出bounding box和label呢?”
- Faster-RCNN 解決的是,“為什麼還要用selective search呢?”
Faster-Rcnn原理簡介
鑑於之上的分析,想要在時間上有所突破就要在如何更快的產生proposal上做工夫。
Faster使用NN來做region proposal,在Fast-rcnn的基礎上使用共享卷積層的方式。作者提出,卷積後的特徵圖同樣也是可以用來生成 region proposals 的。通過增加兩個卷積層來實現Region Proposal Networks (RPNs)
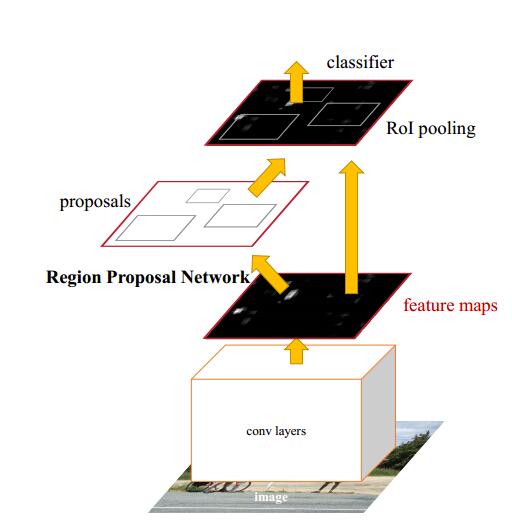
RPN
RPN的作用有以下幾個:
(1) 輸出proposal的位置(座標)和score
(2) 將不同scale和ratio的proposal對映為低維的feature vector
(3) 輸出是否是前景的classification和進行位置的regression
這裡論文提到了一個叫做Anchor的概念,作者給出的定義是:
The k proposals are parameterized relative to k reference boxes, which we call anchors
我的理解是:不同ratio和scale的box集合就是anchor, 對最後一層卷積生成的feature map將其分為n*n的區域,進行不同ratio和scale的取樣.
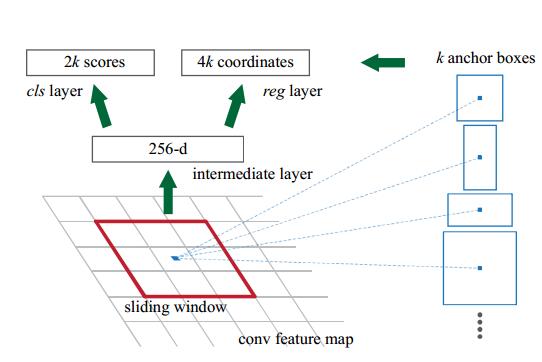
RPN的cls和reg
RPN輸出對於某個proposal,其是屬於前景或者背景的概率(0 or 1),具體的標準論文裡給出的是:
- 和所有的ground-truth的IoU(Intersection-over-union)小於0.3視為negative(背景)
- 和任意的ground-truth的IoU大於0.7視為positive(前景)
- 不屬於以上兩種情況的proposal直接丟掉,不進行訓練使用
對於regression,作用是進行proposal位置的修正:
- 學習k個bounding-box-regressors
- 每個regresso負責一個scale和ratio的proposal,k個regressor之間不共享權值
RPN Training
兩種訓練方式: joint training和alternating training
兩種訓練的方式都是在預先訓練好的model上進行fine-tunning,比如使用VGG16、ZF等,對於新加的layer初始化使用random initiation,使用SGD和BP在caffe上進行訓練
alternating training
首先訓練RPN, 之後使用RPN產生的proposal來訓練Fast-RCNN, 使用被Fast-RCNN tuned的網路初始化RPN,如此交替進行
joint training
首先產生region proposal,之後直接使用產生的proposal訓練Faster-RCNN,對於BP過程,共享的層需要combine RPN loss和Faster-RCNN loss
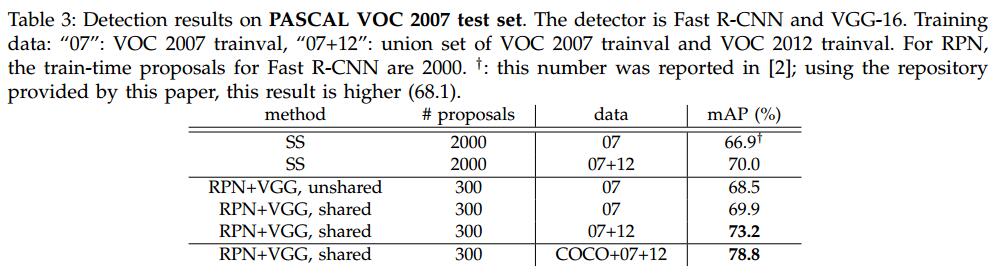
Result
結果自然不用說,肯定是state-of-art,大家自己感受下吧