
python爬蟲常見面試題(一)
前言
之所以在這裡寫下python爬蟲常見面試題及解答,一是用作筆記,方便日後回憶;二是給自己一個和大家交流的機會,互相學習、進步,希望不正之處大家能給予指正;三是我也是網際網路寒潮下崗的那批人之一,為了找工作而做準備。
一、題目部分
1、python中常用的資料結構有哪些?請簡要介紹一下。
2、簡要描述python中單引號、雙引號、三引號的區別。
3、如何在一個function裡設定一個全域性的變數。
4、python裡面如何拷貝一個物件?(賦值、淺拷貝、深拷貝的區別)
5、如果custname字串的編碼格式為uft-8,如何將custname的內容轉化為gb18030的字串?
6、請寫出一段python程式碼實現刪除list中的重複元素。
7、這兩個引數是什麼意思?args和 kwargs。
8、
(1)統計如下list單詞及其出現的次數。
a=['apple', 'banana', 'apple', 'tomato', 'orange', 'apple', 'banana', 'watermeton']
(2)給列表中的字典排序:例如有如下list物件:
alist=[{"name":"a", "age":20}, {"name":"b", "age":30}, {"name":"c", "age":25}] 將alist中的元素按照age從小到大排序。
(3)寫出下列程式碼的執行結果
1 a = 1 2 def fun(a): 3 a = 2 4 fun(a) 5 print(a)
1 a = [] 2 def fun(a): 3 a.append(1) 4 fun(a) 5 print(a)
1 class Person: 2 name = 'Lily' 3 4 p1 = Person() 5 p2 = Person() 6 p1.name = 'Bob' 7 print(p1.name) 8 print(p2.name) 9 print(Person.name)
二、解答部分
注:以下答案,均為google後結合自己學所知識回答,可能會有不正確的地方,錯誤之處希望大家幫我指正出來,謝謝。
1、python中常用的資料結構有哪些?請簡要介紹一下。
python中常見的資料結構有:列表(list),字典(dict),元組(tuple),字串(string),集合(set),數字(int或long或float。。。)等。
其中,列表,元祖和字串可以統一歸為序列類,即這三種資料結構中的元素是有序的。比如,他們都有索引(下標)操作,還有切片、相加和長度(len),最大值(max),最小值(min)操作。這是他們的共同點。
補充:python中常見的資料結構可以統稱為容器(container)。序列(如列表和元組)、對映(如字典)以及集合(set)是三類主要的容器。
另外,關於這個問題,面試官很容易引出另一個問題:python中的哪些資料型別是可變的,哪些是不可變的?
首先,可變/不可變是針對該物件所指向的記憶體中的值是否可變來判斷的。如可變型別的資料型別有列表和字典。不可變型別的資料型別有字串,元組,集合,數字。
就舉個最簡單的數字的例子,python中有小整數池的概念,即[-5,256]範圍內的整數,python直譯器對他們做了特殊處理,都放在記憶體中的固定位置,不會因為你的操作二發生變化。
現在:a = 1 ,然後我們又重新對a賦值,a = 2,在重新賦值的過程中,整數1所對應的記憶體地址沒有和數字的大小都沒有發生變化,還在記憶體中的固定位置。整數2也是如此。變化的是a的指標(這裡引用C中的概念)從指向數字1變成數字2。a物件指向的記憶體中的值沒有發生變化,因此數字是不可變型別的資料型別。字串,集合也是同理。
2、簡要描述python中單引號、雙引號、三引號的區別。
首先,單引號和雙引號在使用時基本上沒有什麼區別,唯一需要注意的是:當字串中有單引號時,最好在外面使用雙引號;當有雙引號時,最好在外面使用單引號。
三引號一般不常用,除了用來做註釋之外,還可以用來列印多行字串。特殊用途,是可以列印多行字串。
1 print('''i 2 love 3 you''') #特殊功能,可以直接列印多行內容,而前面兩種情況需要顯示輸入\n才能換行
輸出結果:
1 i 2 love 3 you
而單引號和雙引號如果想要實現上面的效果,需要加上換行符。
1 print('i\nlove\nyou')
3、如何在一個function裡設定一個全域性的變數。
先說概念,全域性變數是指定義在函式外部的變數。全域性變數的作用域為全域性。
區域性變數是指定義在函式內部的變數。區域性變數的作用域為函式內,除了函式就無效了。
這裡舉個例子,如果把函式比作國家,那麼全域性就是全球,全域性變數好比是阿拉伯數字,每個國家都認識。
所以,根據定義可以知道,在函式內部是無法定義一個全域性變數的,只能做到修改已經定義的全域性變數。
4、python裡面如何拷貝一個物件?(賦值、淺拷貝、深拷貝的區別)
在python中如何拷貝一個物件是需要根據具體的需求來定的。
(1)賦值:其實就是物件的引用。相當於C的指標,修改了其中一個物件,另一個跟著改變。注意對於不可變物件而言,如果修改了其中一個物件,就相當於修改它的指標指向,另一個物件是不會跟著變化的。
1 a = ['1', '2'] # a是一個可變物件 2 b = a 3 a = a.pop() 4 print(b) # 修改了a,b也跟著變
輸出結果:
1 ['1']
當a為不可變物件時:
1 a = 1 2 b = a 3 a = 2 4 print('b = {}'.format(b))
輸出結果:
1 b = 1
(2)淺拷貝:拷貝父物件,但是不會拷貝父物件的子物件。(具體的方法有:b = copy.copy(a),切片如b = a[1:4])
1 a = {1: [1, 2, 3]} 2 b = a.copy() 3 print(a, b) 4 a[1].append(4) 5 print(a, b)
輸出結果為:
{1: [1, 2, 3]} {1: [1, 2, 3]}
{1: [1, 2, 3, 4]} {1: [1, 2, 3, 4]}
當a為不可變物件時:
1 import copy 2 a = 'TEST_STRING' 3 b = copy.copy(a) 4 print(a, b) 5 a = a.lower() 6 print(a, b)
輸出結果:
1 TEST_STRING TEST_STRING 2 test_string TEST_STRING
(3)深拷貝:完全拷貝了父物件和子物件(具體的方法有:b = copy.deepcopy(a))
1 import copy 2 a = {1: [1, 2, 3]} 3 b = copy.deepcopy(a) 4 print(a, b) 5 a[1].append(4) 6 print(a, b)
輸出結果:
1 {1: [1, 2, 3]} {1: [1, 2, 3]} 2 {1: [1, 2, 3, 4]} {1: [1, 2, 3]}
當a為不可變物件時:
1 import copy 2 a = 'TEST_STRING' 3 b = copy.deepcopy(a) 4 print(a, b) 5 a = a.lower() 6 print(a, b)
輸出結果:
1 TEST_STRING TEST_STRING 2 test_string TEST_STRING
下面是圖解:
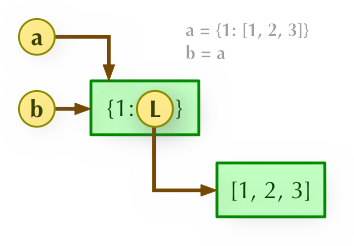
1、b = a: 賦值引用,a 和 b 都指向同一個物件。
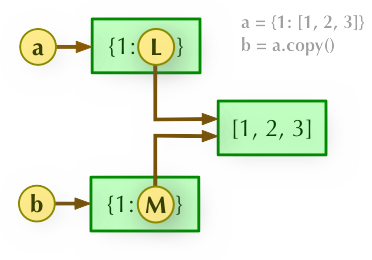
2、b = a.copy(): 淺拷貝, a 和 b 是一個獨立的物件,但他們的子物件還是指向統一物件(是引用)。
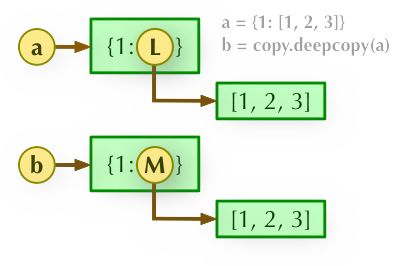
3、b = copy.deepcopy(a): 深度拷貝, a 和 b 完全拷貝了父物件及其子物件,兩者是完全獨立的。
總結:
(1)當物件為不可變型別時,不論是賦值,淺拷貝還是深拷貝,那麼改變其中一個值時,另一個都是不會跟著變化的。
(2)當物件為可變物件時,如果是賦值和淺拷貝,那麼改變其中任意一個值,那麼另一個會跟著發生變化的;如果是深拷貝,是不會跟著發生改變的。
啊,這一題答案真的是好長啊,累到掉渣!歇會兒。。。
5、如果custname字串的編碼格式為uft-8,如何將custname的內容轉化為gb18030的字串?
先將custname編碼格式轉換為unicode,在轉換為gb18030。即custname.decode('utf-8').encode('gb18030')。
注意:unicode編碼是一種二進位制編碼,是轉換編碼的中間橋樑。比如需要將utf-8轉換為gbk,那麼就需要先轉換為unicode(decode),再轉為gbk(encode)。

6、請寫出一段python程式碼實現刪除list中的重複元素。
兩種方法:
(1)利用字典的fromkeys來自動過濾重複值
(2)利用集合set的特性,元素是非重複的
方法一:
1 a = [1, 2, 3, 4, 5, 2, 3] 2 3 def fun1(a): 4 a = list(set(a)) 5 print(a) 6 7 fun1(a)
方法二:
1 a = [1, 2, 3, 4, 5, 2, 3] 2 3 def fun1(a): 4 b = {} 5 b = b.fromkeys(a) 6 c = list(b.keys()) 7 print(c) 8 9 c = fun1(a)
7、這兩個引數是什麼意思?args和 kwargs。
首先,我想說的是*args和**kwargs並不是必須這樣寫,只有前面的*和**才是必須的。你可以寫成*var和**vars。而寫成*args和**kwargs只是約定俗稱的一個命名規定。
*args和**kwargs主要用於函式定義,你可以將不定量的引數傳遞給一個函式。其中,*args 是用來發送一個非鍵值對的可變數量的引數列表給一個函式;**kwargs 允許你將不定長度的鍵值對, 作為引數傳遞給一個函式。 如果你想要在一個函式裡處理帶名字的引數, 你應該使用**kwargs。
1 def import_args(test, *args): 2 print('param1', test) 3 for item in args: 4 print('other param', item) 5 6 7 import_args('123', 'hello', '2019')
這裡傳遞了3個引數,按位置傳參,'123'為test傳參,'hello'和'2019'為*args傳參,這裡傳了2個引數。
注意,看下面的*args的另一種用法:用來解壓資料。
1 def import_args(test, *args): 2 print('param1', test) 3 for item in args: 4 print('other param', item) 5 6 7 args = ['hello', '2019'] 8 import_args('123', *args)
輸出結果:
1 param1 123 2 other param hello 3 other param 2019
這段程式碼和上面的效果是一樣的,但是這裡第8行的*args和第1行的*args可是不一樣的。第一行是表示函式可以接受不定數量的非鍵值對的引數,用來傳參使用的。第八行是用來解壓列表
['hello', '2019']的每一項資料的,用來解壓引數的。這是*args的兩種用法,也可說是*的兩種用法,因為args是可變的。
接下來說說**kwargs。
1 def import_kwargs(test, **kwargs): 2 print('param1', test) 3 for key, value in kwargs.items(): 4 print(key, value) 5 6 7 d = {'name': 'jack', 'age': 26} 8 import_kwargs('123', **d)
**kwargs用來傳遞帶鍵值對的引數,而**也是用來解壓字典容器內的引數。
輸出結果:
1 param1 123 2 name jack 3 age 26
總結:*args和**kwargs都是用於函式中傳遞引數的,*args傳遞的是非鍵值對的引數,**kwargs傳遞的是帶鍵值對的引數,如果還有普通引數需要傳遞,那麼應該先傳遞普通的引數。
8、
(1)統計如下list單詞及其出現的次數。
a=['apple', 'banana', 'apple', 'tomato', 'orange', 'apple', 'banana', 'watermeton']
方法一:
利用字典。
1 a = ['apple', 'banana', 'apple', 'tomato', 'orange', 'apple', 'banana', 'watermeton'] 2 dic = {} 3 for key in a: 4 dic[key] = dic.get(key, 0) + 1 5 print(dic)
輸出結果:
1 {'apple': 3, 'banana': 2, 'tomato': 1, 'orange': 1, 'watermeton': 1}
方法二:
利用python的collections包。
1 from collections import Counter 2 3 a = ['apple', 'banana', 'apple', 'tomato', 'orange', 'apple', 'banana', 'watermeton'] 4 d = Counter(a) 5 print(d)
輸出結果:
1 Counter({'apple': 3, 'banana': 2, 'tomato': 1, 'orange': 1, 'watermeton': 1}) # 是一個類似字典的結構
(2)給列表中的字典排序:例如有如下list物件:
alist=[{"name":"a", "age":20}, {"name":"b", "age":30}, {"name":"c", "age":25}] 將alist中的元素按照age從小到大排序。
利用list的內建函式,list.sort()來進行排序。
1 alist = [{"name": "a", "age": 20}, {"name": "b", "age": 30}, {"name": "c", "age": 25}] 2 alist.sort(key=lambda x: x['age']) 3 print(alist)
這是一種效率很高的排序方法。
輸出結果:
1 [{'name': 'a', 'age': 20}, {'name': 'c', 'age': 25}, {'name': 'b', 'age': 30}]
(3)寫出下列程式碼的執行結果
第一段程式碼的執行結果為:1
分析,在函式外面定義了一個全域性變數a為1,在函式內部定義了一個區域性變數a為2。區域性變數在離開函式後就失效了。
所以,結果為全域性變數的a的值。如果在a=2之前加上global a,宣告為全域性變數,那麼結果為2。
第二段程式碼的執行結果為:[1]
這是因為,將a傳入到function中,這相當於對a進行賦值引用。由於a是可變型別的,所以在函式內部修改a的時候,外部的全域性變數a也跟著變化。
第三段程式碼的執行結果為:
1 Bob 2 Lily 3 Lily
以上。