
python爬蟲常見面試題(二)
前言
之所以在這裡寫下python爬蟲常見面試題及解答,一是用作筆記,方便日後回憶;二是給自己一個和大家交流的機會,互相學習、進步,希望不正之處大家能給予指正;三是我也是網際網路寒潮下崗的那批人之一,為了找工作而做準備。
一、題目部分
1、scrapy框架專題部分(很多面試都會涉及到這部分)
(1)請簡要介紹下scrapy框架。
(2)為什麼要使用scrapy框架?scrapy框架有哪些優點?
(3)scrapy框架有哪幾個元件/模組?簡單說一下工作流程。
(4)scrapy如何實現分散式抓取?
2、其他常見問題。
(1)爬蟲使用多執行緒好?還是多程序好?為什麼?
(2)http和https的區別?
(3)資料結構之堆,棧和佇列的理解和實現。
二、解答部分
1、scrapy框架專題部分
(1)請簡要介紹下scrapy框架。
scrapy 是一個快速(fast)、高層次(high-level)的基於 python 的 web 爬蟲構架,用於抓取web站點並從頁面中提取結構化的資料。scrapy 使用了 Twisted非同步網路庫來處理網路通訊。
(2)為什麼要使用scrapy框架?scrapy框架有哪些優點?
- 它更容易構建大規模的抓取專案
- 它非同步處理請求,速度非常快
- 它可以使用自動調節機制自動調整爬行速度
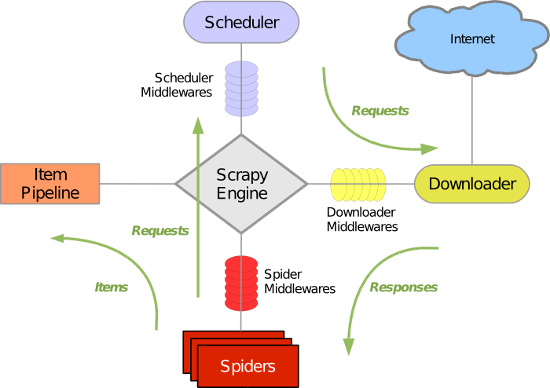
(3)scrapy框架有哪幾個元件/模組?簡單說一下工作流程。
Scrapy Engine: 這是引擎,負責Spiders、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等等!(像不像人的身體?)
Scheduler(排程器): 它負責接受引擎傳送過來的requests請求,並按照一定的方式進行整理排列,入隊、並等待Scrapy Engine(引擎)來請求時,交給引擎。
Downloader(下載器):負責下載Scrapy Engine(引擎)傳送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spiders來處理,
Spiders:它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器),
Item Pipeline:它負責處理Spiders中獲取到的Item,並進行處理,比如去重,持久化儲存(存資料庫,寫入檔案,總之就是儲存資料用的)
Downloader Middlewares(下載中介軟體):你可以當作是一個可以自定義擴充套件下載功能的元件
Spider Middlewares(Spider中介軟體):你可以理解為是一個可以自定擴充套件和操作引擎和Spiders中間‘通訊‘的功能元件(比如進入Spiders的Responses;和從Spiders出去的Requests)
整體架構如下圖:
工作流程:
資料在整個Scrapy的流向:
程式執行的時候,
引擎:Hi!Spider, 你要處理哪一個網站?
Spiders:我要處理23wx.com
引擎:你把第一個需要的處理的URL給我吧。
Spiders:給你第一個URL是XXXXXXX.com
引擎:Hi!排程器,我這有request你幫我排序入隊一下。
排程器:好的,正在處理你等一下。
引擎:Hi!排程器,把你處理好的request給我,
排程器:給你,這是我處理好的request
引擎:Hi!下載器,你按照下載中介軟體的設定幫我下載一下這個request
下載器:好的!給你,這是下載好的東西。(如果失敗:不好意思,這個request下載失敗,然後引擎告訴排程器,這個request下載失敗了,你記錄一下,我們待會兒再下載。)
引擎:Hi!Spiders,這是下載好的東西,並且已經按照Spider中介軟體處理過了,你處理一下(注意!這兒responses預設是交給def parse這個函式處理的)
Spiders:(處理完畢資料之後對於需要跟進的URL),Hi!引擎,這是我需要跟進的URL,將它的responses交給函式 def xxxx(self, responses)處理。還有這是我獲取到的Item。
引擎:Hi !Item Pipeline 我這兒有個item你幫我處理一下!排程器!這是我需要的URL你幫我處理下。然後從第四步開始迴圈,直到獲取到你需要的資訊,
注意!只有當排程器中不存在任何request了,整個程式才會停止,(也就是說,對於下載失敗的URL,Scrapy會重新下載。)
以上就是Scrapy整個流程了。
(4)scrapy如何實現分散式抓取?
可以藉助scrapy_redis類庫來實現。
在分散式爬取時,會有master機器和slave機器,其中,master為核心伺服器,slave為具體的爬蟲伺服器。
我們在master伺服器上搭建一個redis資料庫,並將要抓取的url存放到redis資料庫中,所有的slave爬蟲伺服器在抓取的時候從redis資料庫中去連結,由於scrapy_redis自身的佇列機制,slave獲取的url不會相互衝突,然後抓取的結果最後都儲存到資料庫中。master的redis資料庫中還會將抓取過的url的指紋儲存起來,用來去重。相關程式碼在dupefilter.py檔案中的request_seen()方法中可以找到。
去重問題:
dupefilter.py 裡面的原始碼:
def request_seen(self, request):
fp = request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return not added
去重是把 request 的 fingerprint 存在 redis 上,來實現的。
2、其他常見問題。
(1)爬蟲使用多執行緒好?還是多程序好?為什麼?
對於IO密集型程式碼(檔案處理,網路爬蟲),多執行緒能夠有效提升效率(單執行緒下有IO操作會進行IO等待,會造成不必要的時間等待,而開啟多執行緒後,A執行緒等待時,會自動切換到執行緒B,可以不浪費CPU的資源,從而提升程式執行效率)。
在實際的採集過程中,既考慮網速和相應的問題,也需要考慮自身機器硬體的情況,來設定多程序或者多執行緒。
(2)http和https的區別?
A. http是超文字傳輸協議,資訊是明文傳輸,https則是具有安全性的ssl加密傳輸協議。
B. http適合於對傳輸速度、安全性要求不是很高,且需要快速開發的應用。如web應用,小的手機遊戲等等。而https適用於任何場景。
(3)資料結構之堆,棧和佇列的理解和實現。
棧(stacks):棧的特點是後進先出。只能通過訪問一端來實現資料的儲存和檢索的線性資料結構。
佇列(queue):佇列的特點是先進先出。元素的增加只能在一端,元素的刪除只能在另一端。增加的一端稱為隊尾,刪除的一端稱為隊首。
棧:
1 stack = [1, 2, 3] 2 stack.append(4) 3 stack.append(5) 4 print(stack) 5 stack.pop() 6 stack.pop() 7 print(stack)
輸出結果:
1 [1, 2, 3, 4, 5] 2 [1, 2, 3]
佇列:
1 from collections import deque 2 3 queue = deque(['Eric', 'John', 'Michael']) 4 queue.append('Terry') 5 queue.append('Graham') 6 print(queue) 7 queue.popleft() 8 print(queue)
輸出結果:
1 deque(['Eric', 'John', 'Michael', 'Terry', 'Graham']) 2 deque(['John', 'Michael', 'Terry', 'Graham'])
這裡還會有一個常見的問題,棧溢位的常見情況及解決方案。
什麼是棧溢位?
因為棧一般預設為1-2m,一旦出現死迴圈或者是大量的遞迴呼叫,在不斷的壓棧過程中,造成棧容量超過1m而導致溢位。
棧溢位的幾種情況?
1、區域性陣列過大。當函式內部陣列過大時,有可能導致堆疊溢位。
2、遞迴呼叫層次太多。遞迴函式在執行時會執行壓棧操作,當壓棧次數太多時,也會導致堆疊溢位。
解決方法:
1、用棧把遞迴轉換成非遞迴。
2、增大棧空間。