
協同過濾之 三、基於RBM的推薦演算法
1、RBM用於協同過濾演算法介紹
Ruslan Salakhutdinov首次提出了使用RBM求解Netflix競賽中的協同過濾問題。其首先假設協同過濾系統中共有M個使用者以及N個專案,使用者對於某一個專案的偏好由評分表示(1分—K分,分別表示從不喜歡到喜歡的程度),因此可獲得(稀疏性很高)的使用者—專案評分矩陣。矩陣中在第m行第n列位置上的元素表示使用者m對於專案n的評分值。RuslanSalakhutdinov對傳統的受限玻爾茲曼機做了兩點改變以適合處理協同過濾問題。第一,可見單元使用Softmax神經元;第二,某個使用者可能只對M部電影中的一部分電影進行過評分,而對於沒有評分的記錄使用一種特殊的神經元表示,這種神經元不與任何隱單元連線。其具體結構如下:

從圖中可以看出,Softmax神經元為一個長度為K的向量,並且這個向量每次只有一個分量為1,其餘分量則為0。而評分缺失的Softmax神經元可以同樣視為一個長度為K的向量,只不過其所有的分量始終為0。這樣某使用者的評分可以用的矩陣V來表示,表示矩陣V第k行第i列的元素,表示該使用者對於電影i的評分為k,在給定可見單元狀態,隱單元的啟用概率變為:
(2.7)

同理,在給定隱單元狀態,可見單元狀態的啟用概率變為:
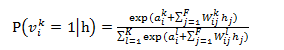
2、推薦階段:以上為基於受限玻爾茲曼機的學習階段,可以獲得整個網路的全部引數。而在其推薦階段的過程如下:
1)輸入為某一個使用者u和某一個專案i,希望的目標輸出是使用者u對使用者i的預測評分;
2)將此使用者u的所有評分作為RBM的softmax單元的輸入;
3)根據式(2.7)計算所有隱單元j 的啟用概率;
4)根據式(2.8)為專案i計算每一個評分k(k=1,…,K)所對應的啟用概率;
5)預測使用者u對專案i的評分,取預測的最大值或者取所有概率的期望。
3、程式碼:
..........敬請原諒,未完待續
4、結果

5、總結
可見採用RBM用來做協同過濾推薦的方法的推薦準確度也不及SlopeOne,但是此處只實現了最原始的模型,沒有試基於條件的rbmCF模型。