
Python爬蟲:Selenium+ BeautifulSoup 爬取JS渲染的動態內容(雪球網新聞)
阿新 • • 發佈:2019-01-04
爬取目標:下圖中紅色方框部分的文章內容。(需要點選每篇文章的連結才能獲得文章內容)
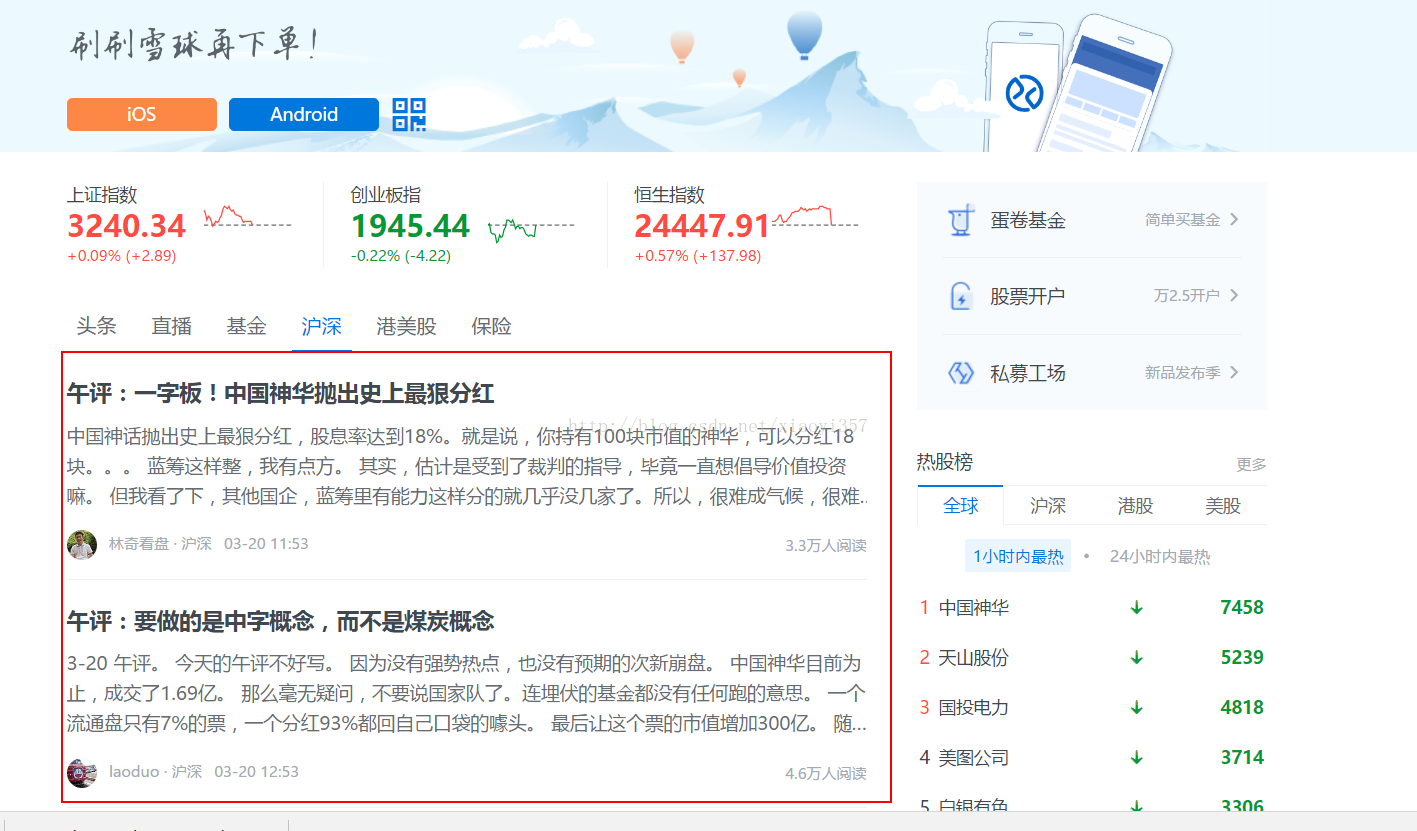
注:該文章僅介紹爬蟲爬取新聞這一部分,爬蟲語言為Python。
乍一看,爬蟲的實現思路很簡單:
(2)通過第一步所獲得的各篇文章的URL,抓取文章內容。
但是發現簡單使用urllib2.urlopen()並不能獲得紅框部分的資料,原因是該部分資料是通過JS動態載入的。
最終發現可以採用Selenium框架來抓取動態資料。Selenium原本是Web測試工具,在Python爬蟲中,可以使用它來模擬真實瀏覽器對URL進行訪問,Selenium支援的瀏覽器包括Firefox、Chrome、Opera、Edge、IE 等 。在此我使用的是Firefox瀏覽器。
Python爬蟲指令碼如下,可以參考註釋來理解程式碼:
# coding=utf-8 import time import Queue import pymongo import urllib2 import threading from bs4 import BeautifulSoup from BeautifulSoup import * from selenium import webdriver from selenium.webdriver.common.by import By # 連線本地MongoDB資料庫 client = pymongo.MongoClient() # 資料庫名為shsz_news db = client.shsz_news # collection名為news collection = db.news # 文章儲存資料結構為:標題 作者 文章釋出時間 閱讀量 文章內容 # title author timestamp read content class Article: title = "" url = "" author = "" timestamp = "" read = 0 content = "" def __init__(self, title, url, author, timestamp, read, content): self.title = title self.url = url self.author = author self.timestamp = timestamp self.read = read self.content = content # 引數為:點選多少次"載入更多" # 返回值為文章的url列表,資料總條數為:50 + 15 * num def get_article_url(num): browser = webdriver.Firefox() browser.maximize_window() browser.get('http://xueqiu.com/#/cn') time.sleep(1) # 將螢幕上滑4次,之後會出現“載入更多”按鈕——此時有50篇文章 for i in range(1, 5): browser.execute_script('window.scrollTo(0, document.body.scrollHeight)') time.sleep(1) # 點選num次“載入更多”——每次點選會載入15篇新聞 for i in range(num): # 找到載入更多按鈕,點選 browser.find_element(By.LINK_TEXT, "載入更多").click() time.sleep(1) soup = BeautifulSoup(browser.page_source) # 解析html,獲取文章列表 article_queue = parse_html(soup) browser.close() return article_queue # 解析html,返回Article的佇列 def parse_html(soup): article_queue = Queue.Queue() article_divs = soup.findAll('div', {'class': 'home__timeline__item'}) if article_divs is not None: for article_div in article_divs: # 獲取文章url url = dict(article_div.h3.a.attrs)['href'] article_url = 'https://xueqiu.com' + url # 獲取文章標題 article_title = article_div.h3.a.string # 獲取文章作者 article_author = article_div.find('a', {'class': 'user-name'}).string # 獲取文章釋出時間 article_timestamp = article_div.find('span', {'class': 'timestamp'}).string # 獲取文章閱讀量 article_read = article_div.find('div', {'class': 'read'}).string # 構造article物件,新增到article_queue佇列中 article = Article(url=article_url, title=article_title, author=article_author, timestamp=article_timestamp, read=article_read, content='') article_queue.put(article) return article_queue # 獲取文章內容的執行緒 class GetContentThread(threading.Thread): def __init__(self, article_queue): threading.Thread.__init__(self) self.url_queue = article_queue def run(self): count = 0; while 1: try: count += 1 # 列印每個執行緒的處理進度... if count % 100 == 0: print count article = self.url_queue.get() # 獲取文章url article_url = article.url request = urllib2.Request(article_url) request.add_header('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6') response = urllib2.urlopen(request, timeout=10) chunk = response.read() soup = BeautifulSoup(chunk) # 將文章內容解析出來 content = soup.find('div', {'class': 'detail'}) # 需要使用str()函式,否則無法儲存到mongoDB中 article.content = str(content) try: # 將article資訊寫入mongoDB資料庫 collection.save(article.__dict__) except Exception, e: # 該方法提示q.join()是否停止阻塞 self.url_queue.task_done() # 將該文章重新放入佇列 self.url_queue.put(article) print "Save into MongoDB error!Let's make a comeback " # 該方法提示q.join()是否停止阻塞 self.url_queue.task_done() except Exception, e: # 該方法提示q.join()是否停止阻塞 self.url_queue.task_done() print 'get content wrong! ', e, '\n' # 出現異常,將異常資訊寫入檔案 file1 = open('get_content_wrong.txt', 'a') file1.write(str(article.title) + '\n') file1.write(str(article.url) + '\n') file1.write(str(e) + '\n') file1.close() if '404' in str(e): print 'URL 404 Not Found:', article.url # 如果錯誤資訊中包含 'HTTP' or 'URL' or 'url' ,將該地址重新加入佇列,以便稍後重新嘗試訪問 elif 'HTTP' or 'URL' or 'url' in str(e): self.url_queue.put(article) print "Let's make a comeback " continue def main(): # 獲得所有的文章,並將它們放入佇列中 article_queue = get_article_url(150) # 建立10個執行緒,獲取所有文章的具體內容,並寫入mongoDB資料庫 for i in range(10): gct = GetContentThread(article_queue) gct.setDaemon(True) gct.start() # 等待佇列中的所有任務完成 article_queue.join() main()