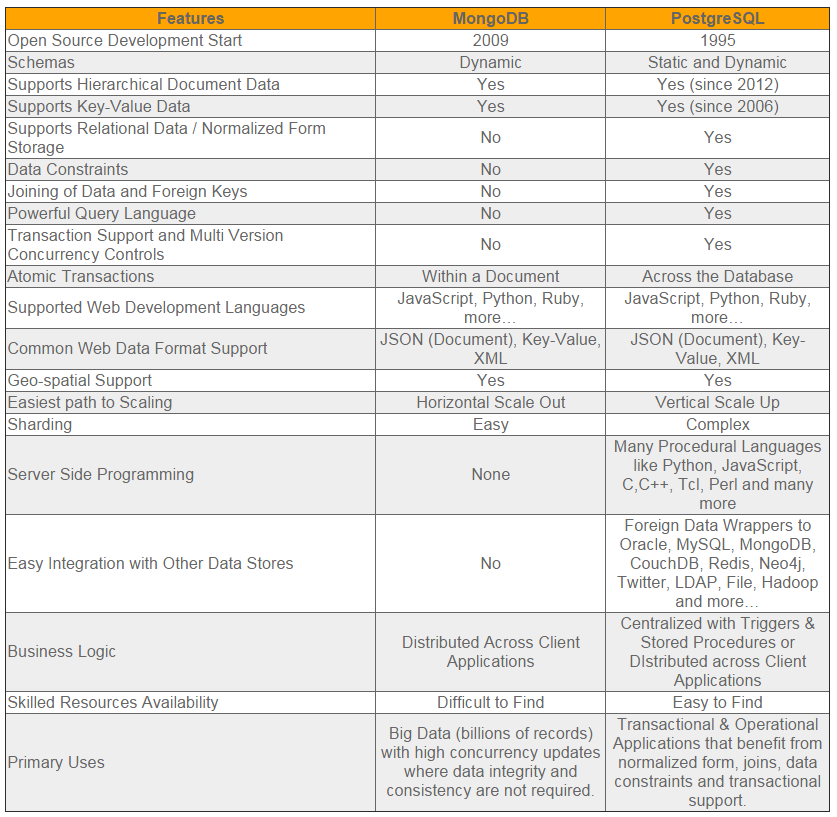
關於PostgreSQL與MongoDB在NoSQL方面的簡單對比
之前我們在和開發團隊所設計框架裡面的MongoDB標準組件PK時,曾經找了一些PG與MongoDB的對比材料。
今天得空又具體看了下,簡單總結一下,供大家借鑑參考:
一、先搞清楚它們支援的資料型別。
PG支援的資料型別叫JSON,從PostgreSQL 9.3版本開始,JSON已經成為內建資料型別,不僅僅是一個擴充套件了。
PG從9.4開始,又推出了新的JSONB的資料型別。
Document Database – JSON
Document database capabilities in Postgres advanced significantly
when support for the JSON data type was introduced in 2012 as part of
Postgres 9.2. JSON (JavaScript Object Notation) is one of the most
popular data-interchange formats on the web. It is supported by
virtually every programming language in use today, and continues to
gain traction. Some NoSQL-only systems, such as MongoDB, use
JSON (or its more limited binary cousin BSON) as their native data
interchange format.
Postgres offers robust support for JSON. Postgres has a JSON data
type, which validates and stores JSON data and provides functions for
extracting elements from JSON values. And, it offers the ability to
easily encode query result sets using JSON. This last piece of
functionality is particularly important, as it means that applications that
prefer to work natively with JSON can easily obtain their data from
Postgres in JSON.
Below are some examples of using JSON data in Postgres:


In addition to the native JSON data type, Postgres v9.3, released in
2013, added a JSON parser and a variety of JSON functions. This
means web application developers don't need translation layers in
the code between the database and the web framework that uses
JSON. JSON-formatted data can be sent directly to the database
where Postgres will not only store the data, but properly validate it
as well. With JSON functions, Postgres can read relational data
from a table and return it to the application as valid JSON formatted
strings. And, the relational data can be returned as JSON for either a single value or an entire record.

JSONB – Binary JSON
Postgres 9.4 introduces JSONB, a second JSON type with a binary
storage format. There are some significant differences between
JSONB in Postgres and BSON, which is used by one of the largest
document-only database providers. JSONB uses an internal
storage format that is not exposed to clients; JSONB values are
sent and received using the JSON text representation. BSON
stands for Binary JSON, but in fact not all JSON values can be
represented using BSON. For example, BSON cannot represent an
integer or floating-point number with more than 64 bits of precision,
whereas JSONB can represent arbitrary JSON values. Users of
BSON-based solutions should be aware of this limitation to avoid
data loss.

引用Francs的blog:jsonb 的出現帶來了更多的函式, 更多的索引建立方式, 更多的操作符和更高的效能。
關於PG的JSON和JSONB的具體介紹和測試,參考Francs的blog:
http://francs3.blog.163.com/blog/static/40576727201452293027868/
http://francs3.blog.163.com/blog/static/40576727201442264738357/
MongoDB支援的資料型別叫BSON
其實BSON就是JSON的一個擴充套件,BSON是一種類json的一種二進位制形式的儲存格式,簡稱Binary JSON,它和JSON一樣,支援內嵌的文件物件和陣列物件,但是BSON有JSON沒有的一些資料型別,如Date和BinData型別。
二者的區別參考:
http://www.tuicool.com/articles/iUNbyi
BSON是由10gen開發的一個數據格式,目前主要用於MongoDB中,是MongoDB的資料儲存格式。BSON基於JSON格式,選擇JSON進行改造的原因主要是JSON的通用性及JSON的schemaless的特性。
BSON主要會實現以下三點目標:
1.更快的遍歷速度
對JSON格式來說,太大的JSON結構會導致資料遍歷非常慢。在JSON中,要跳過一個文件進行資料讀取,需要對此文件進行掃描才行,需要進行麻煩的資料結構匹配,比如括號的匹配,而BSON對JSON的一大改進就是,它會將JSON的每一個元素的長度存在元素的頭部,這樣你只需要讀取到元素長度就能直接seek到指定的點上進行讀取了。
2.操作更簡易
對JSON來說,資料儲存是無型別的,比如你要修改基本一個值,從9到10,由於從一個字元變成了兩個,所以可能其後面的所有內容都需要往後移一位才可以。而使用BSON,你可以指定這個列為數字列,那麼無論數字從9長到10還是100,我們都只是在儲存數字的那一位上進行修改,不會導致資料總長變大。當然,在MongoDB中,如果數字從整形增大到長整型,還是會導致資料總長變大的。
3.增加了額外的資料型別
JSON是一個很方便的資料交換格式,但是其型別比較有限。BSON在其基礎上增加了“byte array”資料型別。這使得二進位制的儲存不再需要先base64轉換後再存成JSON。大大減少了計算開銷和資料大小。
當然,在有的時候,BSON相對JSON來說也並沒有空間上的優勢,比如對{“field”:7},在JSON的儲存上7只使用了一個位元組,而如果用BSON,那就是至少4個位元組(32位)
二、PG和MongoDB在讀寫方面的測試對比:
PG的商業版EnterpriseDB公司在2014.9月釋出了一份針對MongoDB v2.6 to Postgres v9.4 beta的對比報告(如果其對比MongoDB 3.0版本可能測試結果會有差別), 簡單翻譯其測試報告結果如下:
5000萬文件型資料查詢、載入、插入時:
1, 大量資料的載入,PG比MongoDB快2.1倍
2, 同樣的資料量,MongoDB的佔用空間是PG的1.33倍。
3, Insert操作MongoDB比PG慢3倍
4, Select操作MongoDB比PG慢2.5倍。


詳細可以參閱:
當然,EnterpriseDB的測試報告有商業宣傳意味,而且據國內資料庫同仁skykiker的blog的模擬測試的結果,可以看得出EnterpriseDB是有水分的。參考《 為什麼PostgreSQL比MongoDB還快? 》:
http://blog.chinaunix.net/uid-20726500-id-4960138.html
但是, EDB的這份報告裡面的下面這段話與我們之前對開發的說法是一致的,也簡單翻譯了一下,這個我個人理解其實也是企業內複雜應用環境下面,選擇使用PG對比MongoDB的核心優勢,大家可以對開發這樣去灌輸這些理念:
對於應用開發的自由性:
PG的最新版本引領了一個新的開發靈活性的領域, 超過了原來只使用NoSQL帶來的開發自由性。對於像MongoDB這樣在針對性優勢而細分出來的市場中的使用一直在增長,因為開發人員需要從傳統的關係型資料庫的結構化資料中解放出來,他們需要快速交付並且處理新的資料型別。他們選擇強大但是有限制的解決方案可以快速滿足需求,讓他們不用在做任何變動的時候等待DBA。
但是,很多企業發現成功的應用經常需要結構化的資料來落地(down the road這句話我認為用得很好),這種資料對企業更加有價值。PG給到開發人員新的有力的解決方案,從非結構化資料開始著手,當需求變化或增多時,可以將結構化和非結構化的資料在同一個資料庫裡面進行有機結合,而且是在一個具有ACID特性的環境。
原文如下:
Developer Freedom
With the newest version, PostgreSQL has ushered in a new era of developer flexibility exceeding the freedom they discovered with NoSQL-only solutions. The use of niche solutions, like MongoDB, increased because developers needed freedom from the structured data model required by relational databases. They needed to move quickly and work with new data types. They choose powerful but limited solutions that addressed immediate needs, that let them make changes without having to wait for a DBA.
However, many organizations have discovered that successful applications often require structure down the road, as data becomes more valuable across the organization. Postgres gives developers broad new powers to start out unstructured, and then when the need arises, combine unstructured and structured data using the same database engine and within an ACID-compliant environment.
- See more at: http://www.enterprisedb.com/postgres-plus-edb-blog/marc-linster/postgres-outperforms-mongodb-and-ushers-new-developer-reality#sthash.wPT3crV7.dpuf
對於我們DBA面對的開發人員來講,即使把大量關係型資料同步到hadoop來進行運算、分析,但是最終產出分析報表,還是要回到關係型資料庫來做精細化的加工處理。從rdbms -> hadoop -> rdbms可以看到要經過hadoop中轉一道,一方面存在資料同步時效(時間和效率)的問題,另一方面提供實時查詢功能不足,另外可能還需要hive的開發技能。而如果使用PG例如Greenplumb時,直接全部都可以在一個PG叢集裡面完成,上述問題都迎刃而解。
上面這段話是我現在經常用來向開發推銷GP的一種說辭。
以下是2個PG對於關係型資料和非關係型資料整合操作的例子:
1,Combining ANSI SQL Queries and JSON Queries
One of Postgres’ key strengths is the easy integration of conventional
SQL statements, for ANSI SQL tables and records, with JSON and
HSTORE references pointing documents and key-value pairs. Because
JSON and HSTORE are extensions of the underlying Postgres model,
the queries use the same syntax, run in the same ACID transactional
environment, and rely on the same query planner, optimizer and
indexing technologies as conventional SQL-only queries.
這真是一個大殺器,可以將傳統SQL語言和JSON查詢語言聯合一起實現對結構化和非結構化資料的訪問!

2,Bridging Between ANSI SQL and JSON
Postgres provides a number of functions to bridge between JSON and
ANSI SQL. This is an important capability when applications and data
models mature, and designers start to recognize emerging data
structures and relationships.
Postgres can create a bridge between ANSI SQL and JSON, for
example by making a ANSI SQL table look like a JSON data set. This
capability allows developers and DBAs to start with an unstructured
data set, and as the project progresses, adjust the balance between
structured and unstructured data.

更多PG支援的NoSQL的特性和場景, 參考: