
Trie樹詞頻統計例項
阿新 • • 發佈:2019-01-04
Trie樹簡介
Trie樹,也叫字首字典樹,是一種較常用的資料結構。常用於詞頻統計,
字串的快速查詢,最長字首匹配等問題以及相關變種問題。
資料結構表現形式如下圖所示:
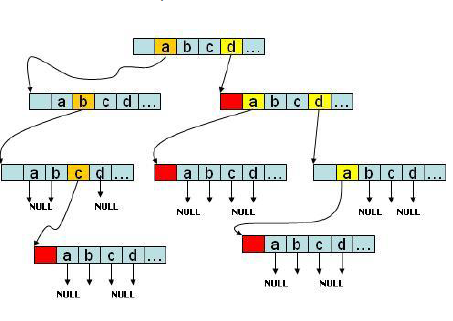
Trie樹的根為空節點,不存放資料。每個節點包含了一個指標陣列,陣列大小通常為26,即儲存26個英文字母(如果要區分大小則陣列大小為52,如果要包括數字,則要加上0-9,陣列大小為62)。
可以想象它是一棵分支很龐大的樹,會佔用不少記憶體空間;不過它的樹高不會唱過最長的字串長度,所以查詢十分快捷。典型的用空間換取時間。
全英聖經詞頻統計
全英聖經TXT檔案大小有4m,若要對它進行詞頻統計等相關操作,可以有許多方法解決。
我覺得可以用如下方式:
- pthon字典資料結構解決
- 在linux下利用sed & awk 文字處理程式解決
- C++ STL map解決
- Trie樹解決
前三種實現比較簡單快捷,不過通過自己封裝Trie樹可以練習一下資料結構!感受一下資料結構帶來的效率提升,何樂而不為。
下面則是我的具體實現,如有紕漏,敬請指正!
1)自定義標頭檔案
WordHash用來記錄不重複的單詞及其出現次數
TrieTree類封裝得不太好,偷懶把很多屬性如行數,單詞總數等都放在public域
#ifndef _WORD_COUNT_H
#define _WORD_COUNT_H
#include<stdio.h> 具體類成員函式cpp檔案
1)字典樹建構函式
#include<iostream>
#include "word_count.h"
using namespace std;
//字典樹建構函式
TrieTree::TrieTree() {
root = new TrieNode();
//詞頻統計表,記錄單詞和出現次數
word_index = 0;
lines_count = 0;
all_words_count = 0;
distinct_words_count = 0;
words_count_table = new WordHash[30000];
}2)讀取文字中的單詞,逐個插入到字典樹中,建立字典樹。
(僅實現了能夠處理全為小寫字母的文字,本人先將聖經檔案做了一些簡單處理)
//建立字典樹,將單詞插入字典樹
void TrieTree::insert(const char *word) {
TrieNode *location = root; //遍歷字典樹的指標
const char *pword = word;
//插入單詞
while( *word ) {
if ( location->next_char[ *word - 'a' ] == NULL ) {
TrieNode *temp = new TrieNode();
location->next_char[ *word - 'a' ] = temp;
}
location = location->next_char[ *word - 'a' ];
word++;
}
location->count++;
location->is_word = true; //到達單詞末尾
if ( location->count ==1 ) {
strcpy(this->words_count_table[word_index++].word,pword);
distinct_words_count++;
}
}3)按單詞查詢字典樹,獲取其出現次數
//查詢字典樹中的某個單詞
bool TrieTree::search(const char *word) {
TrieNode *location = root;
//將要查詢的單詞沒到末尾字母,且字典樹遍歷指標非空
while ( *word && location ) {
location = location->next_char[ *word - 'a' ];
word++;
}
this->words_count_table[word_index++].show_times = location->count;
//在字典樹中找到單詞,並將其詞頻記錄到詞頻統計表中
return (location != NULL && location->is_word);
}4)刪除字典樹
//刪除字典樹,遞迴法刪除每個節點
void TrieTree::deleteTrieTree(TrieNode *root) {
int i;
for( i=0;i<child_num;i++ ) {
if ( root->next_char[i] != NULL ) {
deleteTrieTree(root->next_char[i]);
}
}
delete root;
}5)WordStatics類相關成員函式定義
void WordStatics::set_open_filename(string input_path) {
this->open_filename = input_path;
}
string& WordStatics::get_open_filename() {
return this->open_filename;
}
void WordStatics::open_file(string filename) {
set_open_filename(filename);
cout<<"檔案詞頻統計中...請稍後"<<endl;
fstream fout;
fout.open(get_open_filename().c_str());
const char *pstr;
while (!fout.eof() ) { //將檔案單詞讀取到vector中
string line,word;
getline(fout,line);
dictionary_tree.lines_count++;
istringstream is(line);
while ( is >> word ) {
pstr = word.c_str();
dictionary_tree.all_words_count++;
words.push_back(word);
}
}
//建立字典樹
vector<string>::iterator it;
for ( it=words.begin();it != words.end();it++ ) {
if ( isalpha(it[0][0]) ) {
dictionary_tree.insert( (*it).c_str() );
}
}
}void WordStatics::getResult() {
cout<<"文字總行數:"<<dictionary_tree.lines_count<<endl;
cout<<"所有單詞的總數 : "<<dictionary_tree.all_words_count-1<<endl;
cout<<"不重複單詞的總數 : "<<dictionary_tree.distinct_words_count<<endl;
//在樹中查詢不重複單詞的出現次數
dictionary_tree.setZero_wordindex();
for(int i=0;i<dictionary_tree.distinct_words_count;i++) {
dictionary_tree.search(dictionary_tree.words_count_table[i].word);
result_table.push_back(dictionary_tree.words_count_table[i]);
}
}6)對統計結果進行排序,依照使用者輸入輸出前N詞頻的單詞
bool compare(const WordHash& lhs,const WordHash& rhs) {
return lhs.show_times > rhs.show_times ;
}
void WordStatics::getTopX(int x) {
sort(result_table.begin(),result_table.end(),compare);
cout<<"文字中出現頻率最高的前5個單詞:"<<endl;
for( int i = 0; i<x; i++) {
cout<<result_table[i].word<<": "<<result_table[i].show_times<<endl;
}
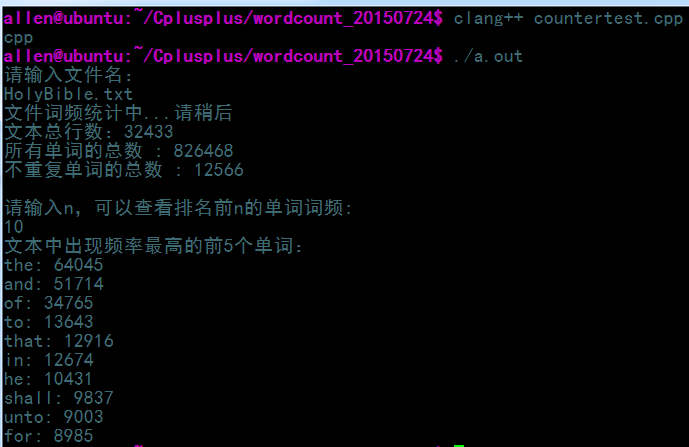
}執行結果:
僅供參考,記錄自己的學習歷程。
還有許多地方不太合理,需要改進,慢慢提升自己的程式設計能力!