
qemu 學習(一)————qemu整體流程解讀
學習qemu已經有半個月了,有了一點小想法,在這裡做個小記錄。
首先要說的是一個很經典的流程圖,也許有很多人提到了這個,這裡再次重複一下:
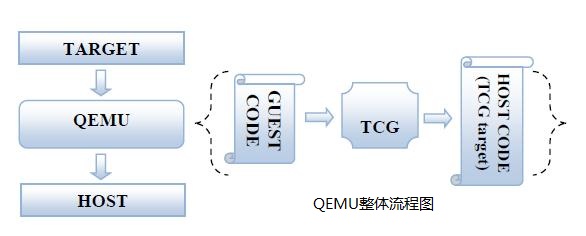
這裡分兩部分:
前端————>把guest code(這裡也稱作target code) 轉換成TCG IR(這裡也稱作TCG-ops,這是一種獨立於具體機器的中間程式碼);
後端————>利用TCG把TCG IR轉換成host上能夠執行的主機程式碼。

vl.c ————>qemu的main函式就存在於此檔案中,虛擬機器是在這裡建立,cpu的執行也是從此處開始的。也可以是說,這裡包含了虛擬機器的初始化過程。特別要說的一點是,main_loop()也存在於此檔案中,虛擬機器的轉換是在這個迴圈中進行呼叫的。
target-xyz/translate.c————>此檔案主要是用於提取guest的程式碼片段,進而轉換成為與架構無關的 TCG IR。需要提出的一點是,轉換過程中的單位元是一個TB,也就是說,一個TB轉換執行結束後,才能輪到下一個TB。
tcg/tcg.c————>此檔案包含了 TCG 的主要程式碼。TCG作為一個後端轉換器,擁有自己的暫存器、操作指令、運算元等。
tcg/xyz/tcg-target.c————>此檔案用來把TCG IR轉換成為host 的code,它會呼叫tcg.c裡面的函式。
cpu-exec.c————>在檔案cpu-exec.c 裡面的函式cpu-exec()會呼叫函式tb_find_fast()在code buffer中查詢下一個TB(注意,這裡的TB指的是已經翻譯成host相關的TB,要與guest所對應的TB加以區分),如果找到了,就會呼叫tcg_qemu_tb_exec()來在host上執行。如果沒有找到,就會呼叫tb_find_slow()來生成host對應的TB,這裡的生成,就是指,由gues的TB經TCG轉化生成能在host執行的TB,最後呼叫tcg_qemu_tb_exec()來在host上執行。
換個思路來說吧,我們可以把qemu分為兩部分,一部分是轉換(就是前面提到的,由guest的TB轉換為host的TB,並且把host的TB放到code buffer中,注意:buffer中的TB會根據需要進行更新),第二部分就是執行,即,最終會用函式tcg_qemu_tb_exec()來執行,在此函式中,會在code buffer中查詢host的tb,然後來執行。轉換和執行的兩個過程是使用中斷進行切換的。
關於幾個重要全域性變數的定義和呼叫:
在 ./translate-all.c:141行,有TCGContext tcg_ctx;——————>在這裡定義了全域性變數tcg_ctx。
在 tcg/tcg.h:473行,有 extern TCGContext tcg_ctx;——————>在這裡引入外部變數tcg_ctx。
在tcg/tcg-op.h中大量引用了變數tcg_ctx,並且,在檔案開始包含了#include "tcg.h"。綜上所述,tcg_ctx可以作為一個外部變數,在所有包含標頭檔案#include "tcg.h的所有檔案中呼叫。
這裡加入一部分博主翻譯內容,以便加深理解(原文來自:Qemu Detailed Study: 7 Chapter):
QEMU的作用就是,提取客戶程式碼,然後轉換成主機程式碼。整個轉換過程由兩部分組成:首先,Target Code的程式碼塊(TB)被轉換成TCG-ops(獨立於機器的中間程式碼),第二步,就是用HOST 架構對應的TCG,把由TB生成的TCG-ops轉換成Host Code。這個的優化過程在這兩個步驟的中間完成。
當前,在QEMU中可以模擬的處理器架構有: Alpha, ARM, Cris,i386, M68K, PPC, Sparc, Mips, MicroBlaze, S390X and SH4。這些架構的處理器對應的/target -xyz/下的code,把TBs轉換成TCG-ops,這裡的xyz就是上面所說的架構名。因此,arm對應的code可以在/target-arm/下面找到。這部分可以被稱為TCG前端。
主機端用/tcg/下的code把TCG-ops生成主機能執行的程式碼,這部分被稱為TCG的後端。
在程式碼執行前,編譯器要把原始碼生成目的碼。為了將一個函式呼叫生成目的碼,編譯器(如gcc)會產生一些特殊的程式碼,這些特殊程式碼應用在函式呼叫前和函式返回前。這些特殊程式碼被稱為 Function Prologue 和 Epilogue。(本人認為,就是函式呼叫前的進棧和出棧處理)。
眾所周知,TCG使用的是動態轉換(Dynamic Translation)技術。所謂動態轉換,就是在需要的時候才轉換code。目的是,把大部分時間花費在執行生成的程式碼上。每次由TB塊生成的code在被執行之前,都會被存在code cache中。大多數的時候,相同的TBs會被多次執行,因此從cache中呼叫是最好的方式,而不重新生成。一旦code cache被填滿了,所有的code cache將被清空。
qemu中target意義的分析:
In qemu, there are two different meanings of target. The first meaning of ‘target’ means the emulated target machine architecture. For example, when emulating mips machine on x86, the
target is mips and host is x86. However, in tcg(tiny code generator), target has a different meaning. It means the generated binary architecture. In the example of emulating mips on x86, in tcg the target means x86 because tcg will generate x86 binary.