
大道至簡——RISC-V架構之魂(中)
本文為《RISC-V CPU設計》專欄和《RISC-V嵌入式軟體開發》專欄系列文章之一。
注:本文節選自“矽農亞歷山大”所著國內第一本系統介紹CPU與RISC-V設計的中文書籍《手把手教你設計CPU:RISC-V處理器篇》(預計將於2018年3~4月上市)。
“大道至簡——RISC-V架構之魂”——分成上中下三篇,本文是中篇。關注文末公眾號後可查詢上中下三篇的內容。
2.3 規整的指令編碼
在流水線中能夠儘早儘快的讀取通用暫存器組,往往是處理器流水線設計的期望之一,這樣可以提高處理器效能和優化時序。這個看似簡單的道理在很多現存的商用RISC架構中都難以實現,因為經過多年反覆修改不斷新增新指令後,其指令編碼中的暫存器索引位置變得非常的凌亂,給譯碼器造成了負擔。
得益於後發優勢和總結了多年來處理器發展的教訓,RISC-V的指令集編碼非常的規整,指令所需的通用暫存器的索引(Index)都被放在固定的位置,如圖2所示。因此指令譯碼器(Instruction Decoder)可以非常便捷的譯碼出暫存器索引然後讀取通用暫存器組(Register File,Regfile)。
圖2 RV32I規整的指令編碼格式

2.4 簡潔的儲存器訪問指令
與所有的RISC處理器架構一樣,RISC-V架構使用專用的儲存器讀(Load)指令和儲存器寫(Store)指令訪問儲存器(Memory),其他的普通指令無法訪問儲存器,這種架構是RISC架構的常用的一個基本策略,這種策略使得處理器核的硬體設計變得簡單。
儲存器訪問的基本單位是位元組(Byte)。RISC-V的儲存器讀和儲存器寫指令支援一個位元組(8位),半字(16位),單字(32位)為單位的儲存器讀寫操作,如果是64位架構還可以支援一個雙字(64位)為單位的儲存器讀寫操作。
RISC-V架構的儲存器訪問指令還有如下顯著特點:
-
為了提高儲存器讀寫的效能,RISC-V架構推薦使用地址對齊的儲存器讀寫操作,但是地址非對齊的儲存器操作RISC-V架構也支援,處理器可以選擇用硬體來支援,也可以選擇用軟體來支援。
-
由於現在的主流應用是小端格式(Little-Endian),RISC-V架構僅支援小端格式。有關小端格式和大端格式的定義和區別,本文在此不做過多介紹,若對此不甚瞭解的初學者可以自行查閱學習。
-
很多的RISC處理器都支援地址自增或者自減模式,這種自增或者自減的模式雖然能夠提高處理器訪問連續儲存器地址區間的效能,但是也增加了設計處理器的難度。RISC-V架構的儲存器讀和儲存器寫指令不支援地址自增自減的模式。
-
RISC-V架構採用鬆散儲存器模型(Relaxed Memory Model),鬆散儲存器模型對於訪問不同地址的儲存器讀寫指令的執行順序不作要求,除非使用明確的儲存器屏障(Fence)指令加以遮蔽。
這些選擇都清楚地反映了RISC-V架構力圖簡化基本指令集,從而簡化硬體設計的哲學。RISC-V架構如此定義非常合理,能夠達到能屈能伸的效果。譬如:對於低功耗的簡單CPU,可以使用非常簡單的硬體電路即可完成設計;而對於追求高效能的超標量處理器則可以通過複雜設計的動態硬體排程能力來提高效能。
2.5 高效的分支跳轉指令
RISC-V架構有兩條無條件跳轉指令(Unconditional Jump),jal與jalr指令。跳轉連結(Jump and Link)指令jal可用於進行子程式呼叫,同時將子程式返回地址存在連結暫存器(Link Register:由某一個通用整數暫存器擔任)中。跳轉連結暫存器(Jump and Link-Register)指令jalr指令能夠用於子程式返回指令,通過將jal指令(跳轉進入子程式)儲存的連結暫存器用於jalr指令的基地址暫存器,則可以從子程式返回。
RISC-V架構有6條帶條件跳轉指令(Conditional Branch),這種帶條件的跳轉指令跟普通的運算指令一樣直接使用2個整數運算元,然後對其進行比較,如果比較的條件滿足時,則進行跳轉。因此,此類指令將比較與跳轉兩個操作放到了一條指令裡完成。
作為比較,很多的其他RISC架構的處理器需要使用兩條獨立的指令。第一條指令先使用比較指令,比較的結果被儲存到狀態暫存器之中;第二條指令使用跳轉指令,判斷前一條指令儲存在狀態暫存器當中的比較結果為真時則進行跳轉。相比而言RISC-V的這種帶條件跳轉指令不僅減少了指令的條數,同時硬體設計上更加簡單。
對於沒有配備硬體分支預測器的低端CPU,為了保證其效能,RISC-V的架構明確要求其採用預設的靜態分支預測機制,即:如果是向後跳轉的條件跳轉指令,則預測為“跳”;如果是向前跳轉的條件跳轉指令,則預測為“不跳”,並且RISC-V架構要求編譯器也按照這種預設的靜態分支預測機制來編譯生成彙編程式碼,從而讓低端的CPU也能得到不錯的效能。
為了使硬體設計儘量簡單,RISC-V架構特地定義了所有的帶條件跳轉指令跳轉目標的偏移量(相對於當前指令的地址)都是有符號數,並且其符號位被編碼在固定的位置。因此,這種靜態預測機制在硬體上非常容易實現,硬體譯碼器可以輕鬆的找到這個固定的位置,並判斷其是0還是1來判斷其是正數還是負數,如果是負數則表示跳轉的目標地址為當前地址減去偏移量,也就是向後跳轉,則預測為“跳”。當然對於配備有硬體分支預測器的高階CPU,則可以採用高階的動態分支預測機制來保證效能。
2.6 簡潔的子程式呼叫
為了理解此節,需先對一般RISC架構中程式呼叫子函式的過程予以介紹,其過程如下:
-
進入子函式之後需要用儲存器寫(Store)指令來將當前的上下文(通用暫存器等的值)儲存到系統儲存器的堆疊區內,這個過程通常稱為“儲存現場”。
-
在退出子程式之時,需要用儲存器讀(Load)指令來將之前儲存的上下文(通用暫存器等的值)從系統儲存器的堆疊區讀出來,這個過程通常稱為“恢復現場”。
“儲存現場”和“恢復現場”的過程通常由編譯器編譯生成的指令來完成,使用高層語言(譬如C或者C++)開發的開發者對此可以不用太關心。高層語言的程式中直接寫上一個子函式呼叫即可,但是這個底層發生的“儲存現場”和“恢復現場”的過程卻是實實在在地發生著(可以從編譯出的組合語言裡面看到那些“儲存現場”和“恢復現場”的彙編指令),並且還需要消耗若干的CPU執行時間。
為了加速這個“儲存現場”和“恢復現場”的過程,有的RISC架構發明了一次寫多個暫存器到儲存器中(Store Multiple),或者一次從儲存器中讀多個暫存器出來(Load Multiple)的指令,此類指令的好處是一條指令就可以完成很多事情,從而減少彙編指令的程式碼量,節省程式碼的空間大小。但是此種“Load Multiple”和“Store Multiple”的弊端是會讓CPU的硬體設計變得複雜,增加硬體的開銷,也可能損傷時序使得CPU的主頻無法提高,筆者在曾經設計此類處理器時便深受其苦。
RISC-V架構則放棄使用這種“Load Multiple”和“Store Multiple”指令。並解釋,如果有的場合比較介意這種“儲存現場”和“恢復現場”的指令條數,那麼可以使用公用的程式庫(專門用於儲存和恢復現場)來進行,這樣就可以省掉在每個子函式呼叫的過程中都放置數目不等的“儲存現場”和“恢復現場”的指令。
此選擇再次印證了RISC-V追求硬體簡單的哲學,因為放棄“Load Multiple”和“Store Multiple”指令可以大幅簡化CPU的硬體設計,對於低功耗小面積的CPU可以選擇非常簡單的電路進行實現,而高效能超標量處理器由於硬體動態排程能力很強,可以有強大的分支預測電路保證CPU能夠快速的跳轉執行,從而可以選擇使用公用的程式庫(專門用於儲存和恢復現場)的方式減少程式碼量,但是同時達到高效能。
2.7 無條件碼執行
很多早期的RISC架構發明了帶條件碼的指令,譬如在指令編碼的頭幾位表示的是條件碼(Conditional Code),只有該條件碼對應的條件為真時,該指令才被真正執行。
這種將條件碼編碼到指令中的形式可以使得編譯器將短小的迴圈編譯成帶條件碼的指令,而不用編譯成分支跳轉指令。這樣便減少了分支跳轉的出現,一方面減少了指令的數目;另一方面也避免了分支跳轉帶來的效能損失。然而,這種“條件碼”指令的弊端同樣會使得CPU的硬體設計變得複雜,增加硬體的開銷,也可能損傷時序使得CPU的主頻無法提高,筆者在曾經設計此類處理器時便深受其苦。
RISC-V架構則放棄使用這種帶“條件碼”指令的方式,對於任何的條件判斷都使用普通的帶條件分支跳轉指令。此選擇再次印證了RISC-V追求硬體簡單的哲學,因為放棄帶“條件碼”指令的方式可以大幅簡化CPU的硬體設計,對於低功耗小面積的CPU可以選擇非常簡單的電路進行實現,而高效能超標量處理器由於硬體動態排程能力很強,可以有強大的分支預測電路保證CPU能夠快速的跳轉執行達到高效能。
2.8 無分支延遲槽
很多早期的RISC架構均使用了“分支延遲槽(Delay Slot)”,最具有代表性的便是MIPS架構,在很多經典的計算機體系結構教材中,均使用MIPS對分支延遲槽進行過介紹。分支延遲槽就是指在每一條分支指令後面緊跟的一條或者若干條指令不受分支跳轉的影響,不管分支是否跳轉,這後面的幾條指令都一定會被執行。
早期的RISC架構很多采用了分支延遲槽誕生的原因主要是因為當時的處理器流水線比較簡單,沒有使用高階的硬體動態分支預測器,所以使用分支延遲槽能夠取得可觀的效能效果。然而,這種分支延遲槽使得CPU的硬體設計變得極為的彆扭,CPU設計人員對此往往苦不堪言。
RISC-V架構則放棄了分支延遲槽,再次印證了RISC-V力圖簡化硬體的哲學,因為現代的高效能處理器的分支預測演算法精度已經非常高,可以有強大的分支預測電路保證CPU能夠準確的預測跳轉執行達到高效能。而對於低功耗小面積的CPU,由於無需支援分支延遲槽,硬體得到極大簡化,也能進一步減少功耗和提高時序。
2.9 無零開銷硬體迴圈
很多RISC架構還支援零開銷硬體迴圈(Zero Overhead Hardware Loop)指令,其思想是通過硬體的直接參與,通過設定某些迴圈次數暫存器(Loop Count),然後可以讓程式自動地進行迴圈,每一次迴圈則Loop Count自動減1,這樣持續迴圈直到Loop Count的值變成0,則退出迴圈。
之所以提出發明這種硬體協助的零開銷迴圈是因為在軟體程式碼中的for 迴圈(for i=0; i<N; i++)極為常見,而這種軟體程式碼通過編譯器編譯之後,往往會編譯成若干條加法指令和條件分支跳轉指令,從而達到迴圈的效果。一方面這些加法和條件跳轉指令佔據了指令的條數;另外一方面條件分支跳轉如存在著分支預測的效能問題。而硬體協助的零開銷迴圈,則將這些工作由硬體直接完成,省掉了這些加法和條件跳轉指令,減少了指令條數且提高了效能。
然有得必有失,此類零開銷硬體迴圈指令大幅地增加了硬體設計的複雜度。因此,零開銷迴圈指令與RISC-V架構簡化硬體的哲學是完全相反的,在RISC-V架構中自然沒有使用此類零開銷硬體迴圈指令。
2.10 簡潔的運算指令
在本章第2.1節中曾經提到RISC-V架構使用模組化的方式組織不同的指令子集,最基本的整數指令子集(I字母表示)支援的運算包括加法、減法、移位、按位邏輯操作和比較操作。這些基本的運算操作能夠通過組合或者函式庫的方式完成更多的複雜操作(譬如乘除法和浮點操作),從而能夠完成大多數的軟體操作。
整數乘除法指令子集(M字母表示)支援的運算包括,有符號或者無符號的乘法和除法操作。乘法操作能夠支援兩個32位的整數相乘得到一個64位的結果;除法操作能夠支援兩個32位的整數相除得到一個32位的商與32位的餘數。
單精度浮點指令子集(F字母表示)與雙精度浮點指令子集(D字母表示)支援的運算包括浮點加減法,乘除法,乘累加,開平方根和比較等操作,同時提供整數與浮點,單精度與雙精度浮點彼此之間的格式轉換操作。
很多RISC架構的處理器在運算指令產生錯誤之時,譬如上溢(Overflow)、下溢(Underflow)、非規格化浮點數(Subnormal)和除零(Divide by Zero),都會產生軟體異常。RISC-V架構的一個特殊之處是對任何的運算指令錯誤(包括整數與浮點指令)均不產生異常,而是產生某個特殊的預設值,同時,設定某些狀態暫存器的狀態位。RISC-V架構推薦軟體通過其他方法來找到這些錯誤。再次清楚地反映了RISC-V架構力圖簡化基本的指令集,從而簡化硬體設計的哲學。
2.11 優雅的壓縮指令子集
基本的RISC-V基本整數指令子集(字母I表示 )規定的指令長度均為等長的32位,這種等長指令定義使得僅支援整數指令子集的基本RISC-V CPU非常容易設計。但是等長的32位編碼指令也會造成程式碼體積(Code Size)相對較大的問題。
為了滿足某些對於程式碼體積要求較高的場景(譬如嵌入式領域),RISC-V定義了一種可選的壓縮(Compressed)指令子集,由字母C表示,也可以由RVC表示。RISC-V具有後發優勢,從一開始便規劃了壓縮指令,預留了足夠的編碼空間,16位長指令與普通的32位長指令可以無縫自由地交織在一起,處理器也沒有定義額外的狀態。
RISC-V壓縮指令的另外一個特別之處是,16位指令的壓縮策略是將一部分普通最常用的的32位指令中的資訊進行壓縮重排得到(譬如假設一條指令使用了兩個同樣的運算元索引,則可以省去其中一個索引的編碼空間),因此每一條16位長的指令都能一一找到其對應的原始32位指令。因此,程式編譯成為壓縮指令僅在彙編器階段就可以完成,極大的簡化了編譯器工具鏈的負擔。
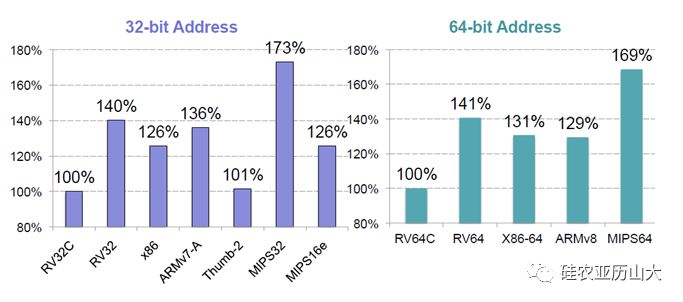
RISC-V架構的研究者進行了詳細的程式碼體積分析,如圖3所示,通過分析結果可以看出,RV32C的程式碼體積相比RV32的程式碼體積減少了百分之四十,並且與ARM,MIPS和x86等架構相比都有不錯的表現。
圖3 各指令集架構的程式碼密度比較(資料越小越好)
“大道至簡——RISC-V架構之魂”——分成上中下三篇,本文是中篇。關注文末公眾號後可查詢上中下三篇的內容。
更多資訊
感興趣的讀者可以通過下面二維碼關注公眾號“矽農亞歷山大”,瞭解Verilog、IC設計、CPU、RISC-V和人工智慧AI相關的更多設計技巧和經驗分享,注意:由於乾貨太多,請自備茶水。
