
爬蟲的常見陷阱以及Java的爬蟲思路
前言
筆者做的爬蟲側重於對於網頁內容的提取,url 遵守一定概率(比如末尾數字遞增)。
爬蟲的基本思路如下
1. 根據 Url 獲取相應頁面的 Html 程式碼
2. 利用正則匹配或者 Jsoup 等庫解析 Html 程式碼,提取需要的內容
3. 將獲取的內容持久化到資料庫中
4. 處理好中文字元的編碼問題,可以採用多執行緒提高效率
Jsoup 簡介
從 Jsoup 的 Api 可以看出,Element 繼承自 Node。

根據 DOM,HTML 文件中的每個成分都是一個Node。Node 之間有等級關係,父 Node、子 Node、兄弟 Node 等等。
Joup 其實是 Html 解析器,可通過DOM,CSS以及類似於jQuery的操作方法來取出和操作資料。如果不使用 Jsoup 解析,也可以利用正則匹配找出 Html 中需要的內容。
如何獲取 url 呢?有一種方法從文章列表中獲取,比如下面的部落格目錄檢視中,文章的對於的 html程式碼中可以獲取href=”/never_cxb/article/details/50524571”, 標題為Java實現爬蟲給App提供資料(Jsoup 網路爬蟲)。
<h1>
<span class="link_title"><a href="/never_cxb/article/details/50524571">
<font color="red">[置頂]</font>
Java實現爬蟲給App提供資料(Jsoup 網路爬蟲)
</a 
爬蟲基本原理
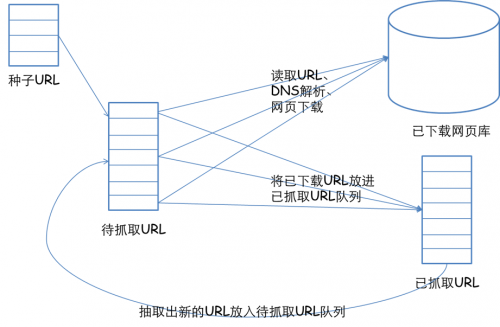
更寬泛意義上的爬蟲側重於如果在大量的 url 中尋找出高質量的資源,如何在有限的時間內訪問更多頁面等等。網路爬蟲的基本工作流程如下:
1.首先選取一部分精心挑選的種子URL;
2.將這些URL放入待抓取URL佇列;
3.從待抓取URL佇列中取出待抓取在URL,解析DNS,並且得到主機的ip,並將URL對應的網頁下載下來,儲存進已下載網頁庫中。此外,將這些URL放進已抓取URL佇列。
4.分析已抓取URL佇列中的URL,分析頁面裡包含的其他URL,並且將URL放入待抓取URL佇列,從而進入下一個迴圈。
有幾個概念,一個是發http請求,一個是正則匹配你感興趣的連結,一個是多執行緒,另外還有兩個佇列。
來源於 該文章 的一張圖
爬蟲難點1 環路
網路爬蟲有時候會陷入迴圈或者環路中,比如從頁面 A,A 連結到頁面 B,B 連結 頁面C,頁面 C 又會連結到頁面 A。這樣就陷入到環路中。
環路影響
- 消耗網路頻寬,無法獲取其他頁面
- 對 Web 伺服器也是負擔,可能擊垮該站點,可能阻止正常使用者訪問該站點
- 即使沒有效能影響,但獲取大量重複頁面也導致資料冗餘
解決方案
1. 簡單限定爬蟲的最大迴圈次數,對於某 web 站點訪問超過一定閾值就跳出,避免無限迴圈
2. 儲存一個已訪問 url 列表,記錄頁面是否被訪問過的技術
- 二叉樹和散列表,快速判定某個 url 是否訪問過
- 存在點陣圖
就是 new int[length],然後把第幾個數置為1,表示已經訪問過了。可不可以再優化,int 是32位,32位可以表示32個數字。HashCode 會存在衝突的情況,兩個 url 對映到同一個存在位上,衝突的後果是某個頁面被忽略(這比死迴圈的惡作用小) - 儲存檢查
一定要即使把已訪問的 url 列表儲存在硬碟上,防止爬蟲崩潰,記憶體裡的資料會丟失 - 叢集 ,分而治之
多臺機器一起爬蟲,可以根據 url 計算 hashcode,然後根據 hashcode 對映到相應機器的 id (第0臺、第1臺、第2臺等等)
難點2 URL別名
有些 url 名稱不一樣,但是指向同一個資源。
該表格來自於 《HTTP 權威指南》
| URl 1 | URL 2 | 什麼時候是別名 |
|---|---|---|
| www.foo.com/bar.html | www.foo.com:80/bar.html | 預設埠是80 |
| www.foo.com/~fred | www.foo.com/%7Ffred | %7F與~相同 |
| www.foo.com/x.html#top | www.foo.com/x.html#middle | %7F與~相同 |
| www.foo.com/index.html | www.foo.com | 預設頁面為 index.html |
| www.foo.com/index.html | 209.123.123/index.html | ip和域名相同 |
難點3 動態虛擬空間
比如日曆程式,它會生成一個指向下一月的連結,真正的使用者是不會不停地請求下個月的連結的。但是不瞭解這內容特性的爬蟲蜘蛛可能會不斷向這些資源發出無窮的請求。
抓取策略
一般策略是深度優先或者廣度優先。有些技術能使得爬蟲蜘蛛有更好的表現
- 廣度優先的爬行,避免深度優先陷入某個站點的環路中,無法訪問其他站點。
- 限制訪問次數,限定一段時間內機器人可以從一個 web 站點獲取的頁面數量
- 內容指紋,根據頁面的內容計算出一個校驗和,但是動態的內容(日期,評論數目)會阻礙重複檢測
- 維護黑名單
- 人工監視,特殊情況發出郵件通知
動態變化,根據當前熱點新聞等等
規劃化 url,把一些轉義字元、ip 與域名之類的統一
- 限制 url 大小,環路可能會使得 url 長度增加,比如/index.html, /folder/index,html, /folder/folder/index.html …
全文索引
全文索引就是一個數據庫,給它一個單詞,它可以立刻提供包含那個單詞的所有文字。建立了索引之後,就不必對文件自身進行掃描了。
比如 文章 A 包含了 Java、學習、程式設計師
文章 B 包含了 Java 、Python、面試、招聘
如果搜尋 Java,可以知道得到 文章 A 和文章 B,而不必對文章 A、B 全文掃描。
複習 Python 爬蟲
自己曾實現了Python 爬蟲,統計學校論壇上男女使用者各佔多少。
我當時做的思路是 get 請求獲取 html 原始碼,對 html 用字串匹配(前後多加一些限定單詞進行正則匹配 比如em>上次發表時間</em>後面跟的是活動時間)。
回過頭來看,可能解析Dom 樹可能更優雅一些。