
Google三大理論(論文)
Google引爆大資料時代的三篇論文
談到Hadoop的起源,就不得不提Google的三駕馬車:Google FS、MapReduce、BigTable。雖然Google沒有公佈這三個產品的原始碼,但是他釋出了這三個產品的詳細設計論文,奠定了風靡全球的大資料演算法的基礎!
一,GFS—-2003
2003年,Google釋出Google File System論文,這是一個可擴充套件的分散式檔案系統,用於大型的、分散式的、對大量資料進行訪問的應用。它運行於廉價的普通硬體上,提供容錯功能。從根本上說:檔案被分割成很多塊,使用冗餘的方式儲存於商用機器叢集上。

GFS由一個master和大量的chunkserver構成。Google設定一個master來儲存目錄和索引資訊,這是為了簡化系統結果,提高效能來考慮的,但是這就會造成主成為單點故障或者瓶頸。為了消除主的單點故障Google把每個chunk設定的很大(64M),這樣,由於程式碼訪問資料的本地性,application端和master的互動會減少,而主要資料流量都是Application和chunkserver之間的訪問。
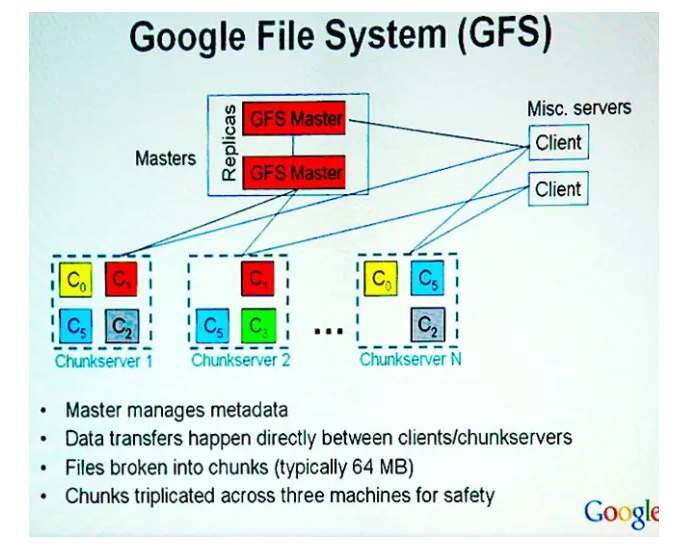
另外,master所有資訊都儲存在記憶體裡,啟動時資訊從chunkserver中獲取。提高了master的效能和吞吐量,也有利於master當掉後,很容易把後備j機器切換成master。客戶端和chunkserver都不對檔案資料單獨做快取,只是用linux檔案系統自己的快取。
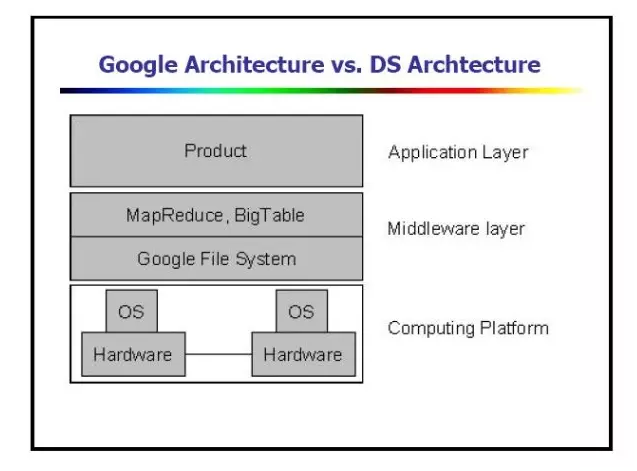
從上圖可以看出,Google的後面兩篇論文——MapReduce 和 BigTable都是以GFS為基礎。三大基礎核心技術構建出了完整的分散式運算架構。
二,MapReduce—-2004
緊隨其後的就是2004年公佈的 MapReduce論文,論文描述了大資料的分散式計算方式,主要思想是將任務分解然後在多臺處理能力較弱的計算節點中同時處理,然後將結果合併從而完成大資料處理。
傳說中,Google使用它計算他們的搜尋索引。而Mikio L. Braun認為其工作模式應該是:Google把所有抓取的頁面都放置於他們的叢集上,然後每天使用MapReduce來重算。

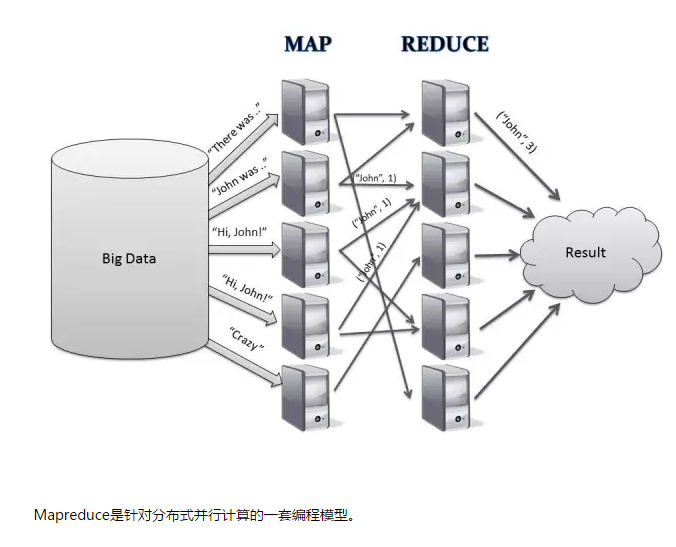
Mapreduce是針對分散式平行計算的一套程式設計模型。
講到平行計算,就不能不談到微軟的Herb Sutter在2005年發表的文章” The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software”,主要意思是通過提高cpu主頻的方式來提高程式的效能很快就要過去了,cpu的設計方向也主要是多核、超執行緒等併發上。但是以前的程式並不能自動的得到多核的好處,只有編寫併發程式,才能真正獲得多核的好處。分散式計算也是一樣。
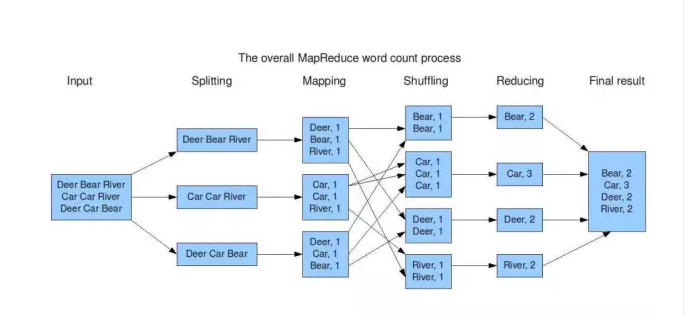
Mapreduce由Map和reduce組成,來自於Lisp,Map是影射,把指令分發到多個worker上去,reduce是規約,把Map的worker計算出來的結果合併。Mapreduce使用GFS儲存資料。
3
BigTable—-2006
Bigtable釋出於2006年,啟發了無數的NoSQL資料庫,比如:Cassandra、HBase等等。Cassandra架構中有一半是模仿Bigtable,包括了資料模型、SSTables以及提前寫日誌(另一半是模仿Amazon的Dynamo資料庫,使用點對點叢集模式)。

BigTable 是建立在 GFS 和 MapReduce 之上的。每個Table都是一個多維的稀疏圖
為了管理巨大的Table,把Table根據行分割,這些分割後的資料統稱為:Tablets。每個Tablets大概有 100-200 MB,每個機器儲存100個左右的 Tablets。底層的架構是:GFS。
由於GFS是一種分散式的檔案系統,採用Tablets的機制後,可以獲得很好的負載均衡。比如:可以把經常響應的表移動到其他空閒機器上,然後快速重建。