
Spark(三)————作業提交流程
1、Spark核心API
[SparkContext]
連線到spark叢集,入口點.
[RDD]
它是一個分割槽的集合.
彈性分散式資料集.
不可變的資料分割槽集合.
基本操作(map filter , persist)
分割槽列表 //資料
應用給每個切片的計算函式 //行為
到其他RDD的依賴列表 //依賴關係
(可選)針對kv型別RDD的分割槽類
(可選)首選位置列表
[HadoopRDD]
讀取hadoop上的資料
[MapPartitionsRDD]
針對父RDD的每個分割槽提供了函式構成的新型別RDD.
[PairRDDFunctions]
對偶RDD函式類,可用於KV型別RDD的附加函式,可以通過隱式轉化得到.
[ShuffleRDD]
從Shuffle中計算結果的RDD.
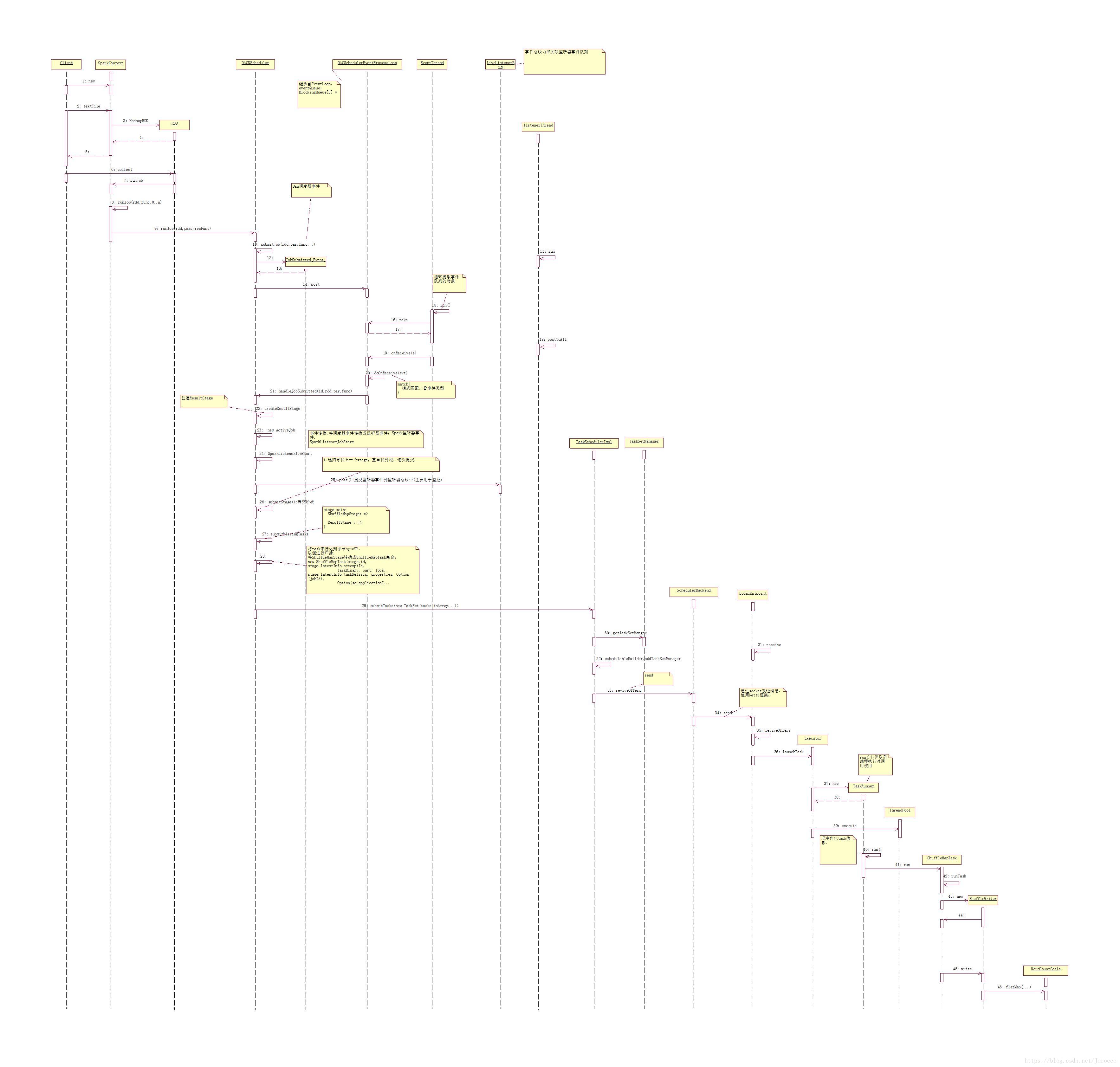
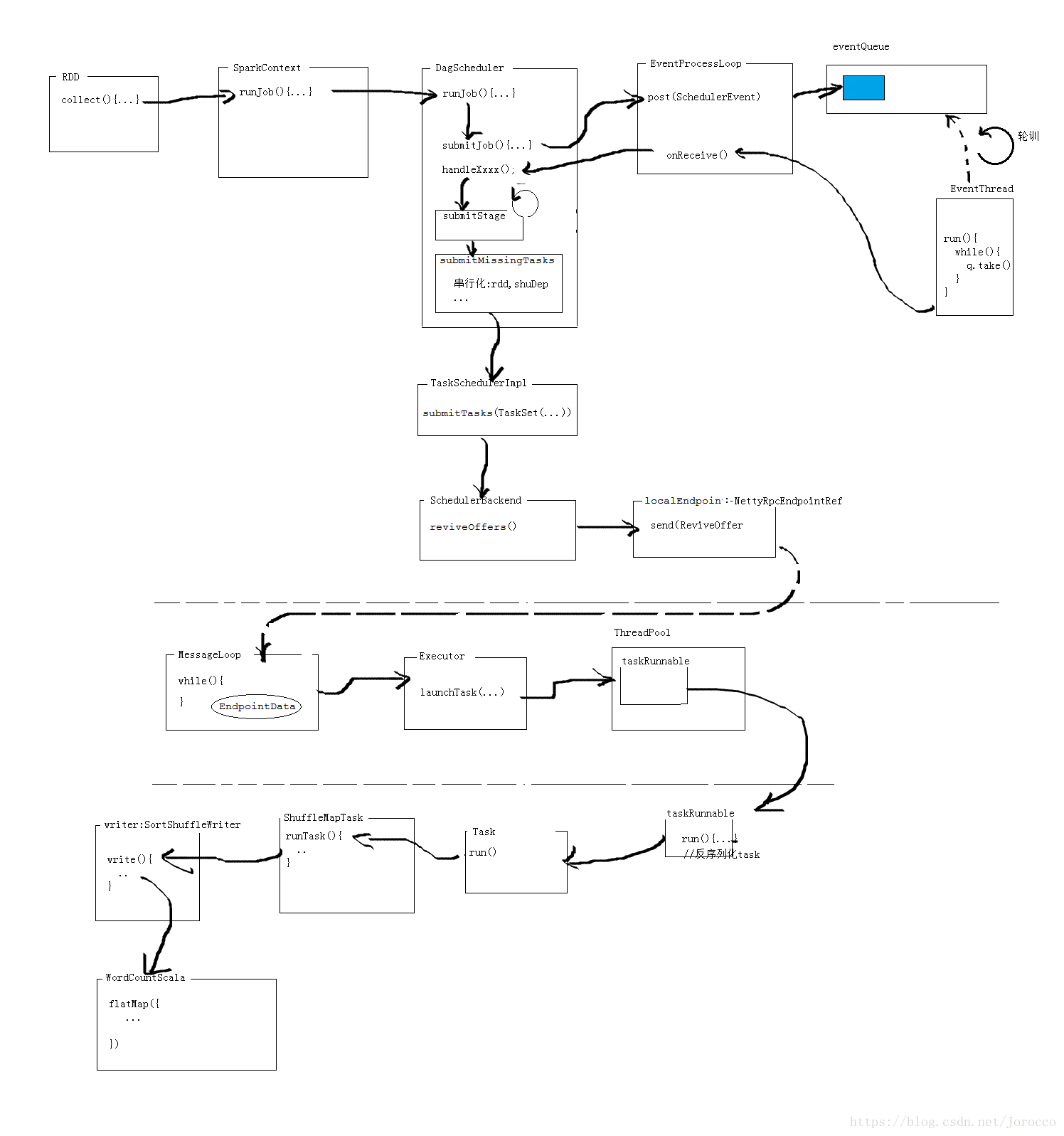
[DAGScheduler]
高階排程器層面,實現按照階段(stage),建立按照shuffle.
對每個Job的各階段計算有向無環圖(DAG),並且跟蹤RDD和每個階段的輸出。
找出最小排程執行作業,將Stage物件以TaskSet方式提交給底層的排程器。
底層排程器實現TaskScheduler,進而在cluster上執行job。
TaskSet已經包含了全部的單獨的task,這些Task都能夠基於cluster的資料進行正確執行。
Stage通過在需要shuffle的邊界處將RDD打碎來建立Stage物件。
具有’窄依賴’的RDD操作(比如map /filter)被管道化至一個taskset中,而具有shuffle依賴的操作則包含多個Stage(一個進行輸出,另一個進行輸入),最終,每個stage都有一個針對其他stage的shuffle依賴,可以計算多個操作。
Dag排程器檢測首選位置來執行task,通過基於當前的快取狀態,並傳遞給底層的
task排程器來實現。根據shuffle的輸出是否丟失處理故障問題。不是由stage內因為丟失檔案引發的故障有task排程處理。在取消整個stage之前,task會進行少量次數的重試操作。
為了容錯,同一stage可能會執行多次,稱之為”attemp”,如果task排程器報告了一個故障(該故障是由於上一個stage丟失輸出檔案而導致的)DAG排程就會重新提交丟失的stage。這個通過具有 FetchFailed的CompletionEvent物件或者ExecutorLost進行檢測的。DAG排程器會等待一段時間看其他節點或task是否失敗,然後對丟失的stage重新提交taskset,計算丟失的task。

2、相關術語介紹
[job]
提交給排程的頂層的工作專案,由ActiveJob表示,是Stage集合。
[Stage]
是task的集合,計算job中的中間結果。同一RDD的每個分割槽都會應用相同的計算函式。
在shuffle的邊界處進行隔離(因此引入了隔斷,需要上一個stage完成後,才能得到output結果)有兩種型別的stage:1)ResultStage,用於執行action動作的最終stage。2)ShuffleMapStage,對shuffle進行輸出檔案的寫操作的。如果job重用了同一個rdd的話,stage通常可以跨越多個job實現共享。
並行任務的集合,都會計算同一函式。所有task有著同樣的shuffle依賴,排程器執行的task DAG在shuffle邊界處劃分成不同階段。排程器以拓撲順序執行。
每個stage可以是shuffleMapStage,該階段下輸出是下一個stage的輸入,也可以是resultStage,該階段task直接執行spark action。對於shuffleMapStage,需要跟蹤每個輸出分割槽所在的節點。
每個stage都有FirstJobId,區分於首次提交的id。
[ShuffleMapStage]
產生輸出資料,在每次shuffle之前發生。內部含有shuffleDep欄位,有相關欄位記錄產生多少輸出以及多少輸出可用。
DAGScheduler.submitMapStage()方法可以單獨提交submitMapStage()。
[ResultStage]
該階段在RDD的一些分割槽中應用函式來計算Action的結果。有些stage並不會在所有分割槽上執行。例如first(),lookup();
[Task]
單獨的工作單元,每個傳送給一臺主機。作業是階段的集合,階段是任務的集合。
[Cache tracking]
Dag排程器找出哪些RDD被快取,避免不必要的重複計算,同時,也會記住哪些shuffleMap已經輸出了結果,避免map端shuffle的重複處理。
[Preferred locations]
dag排程器根據rdd中的首選位置屬性計算task在哪裡執行。
[Cleanup]
執行的job如果完成就會清楚資料結構避免記憶體洩漏,主要是針對耗時應用。
[ActiveJob]
在Dag排程器中執行job。作業分為兩種型別:
1)result job,計算ResultStage來執行action.
2)map-state job,為shuffleMapState結算計算輸出結果以供下游stage使用。主要使用finalStage欄位進行型別劃分。
job只跟蹤客戶端提交的”leaf” stage,通過呼叫Dag排程器的submitjob或者submitMapStage()方法實現。
job型別引發之前stage的執行,而且多個job可以共享之前的stage。這些依賴關係由DAG排程器內部管理。
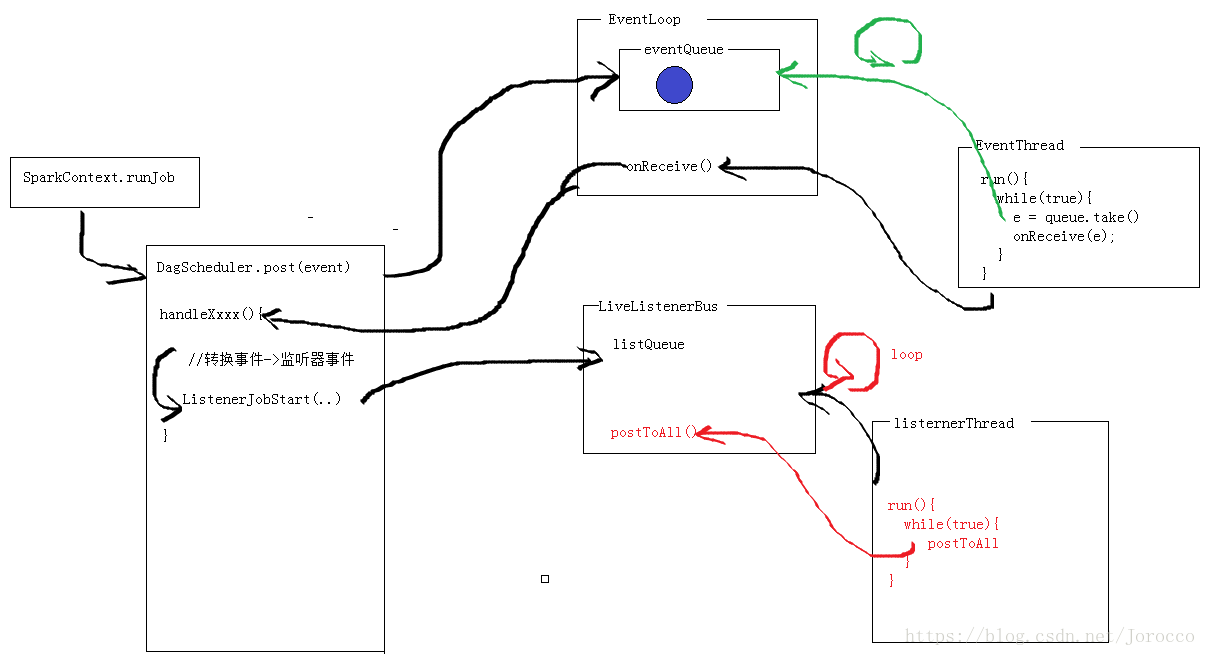
[LiveListenerBus]
監聽器匯流排,存放Spark監聽器事件的佇列,用於監控。非同步傳輸spark監聽事件到監聽器事件集合中。
[EventLoop]
從caller接受事件,在單獨的事件執行緒中處理所有事件,該類的唯一子類是DAGSchedulerEventProcessLoop。
[OutputCommitCoordinator]
輸出提交協調器.決定提交的輸出是否進入hdfs。
[TaskScheduler]
底層的排程器,唯一實現TaskSchedulerImpl。可插拔,同Dag排程器接受task,傳送給cluster,執行任務,失敗重試,返回事件給DAG排程器。
[TaskSchedulerImpl]
TaskScheduler排程器的唯一實現,通過BackendScheduler(後臺排程器)實現各種型別叢集的任務排程。
[SchedulerBackend]
可插拔的後臺排程系統,本地排程,mesos排程,。。。
在任務排程器下方,實現有三種:
1.LocalSchedulerBackend
本地後臺排程器
啟動task.
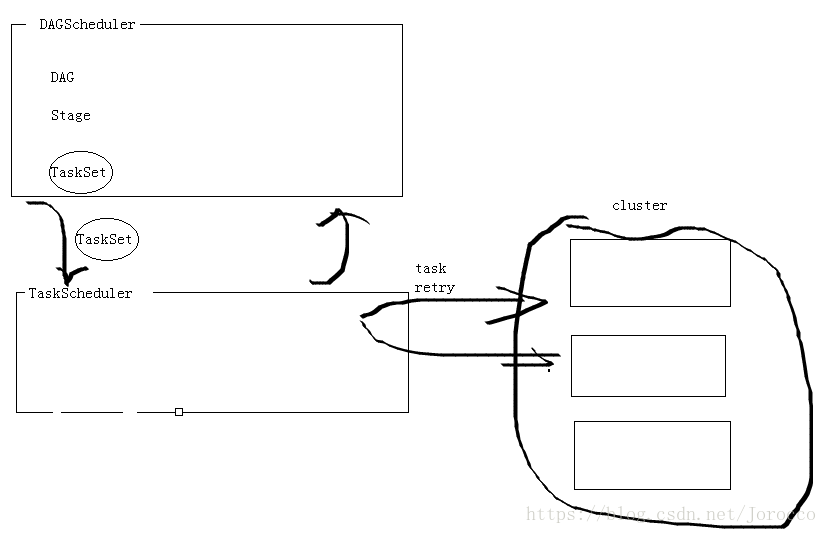
2.StandaloneSchedulerBackend
獨立後臺排程器
3.CoarseGrainedSchedulerBackend
粗粒度後臺排程器
[Executor]
spark程式執行者,通過執行緒池執行任務。
3、Dependency:依賴
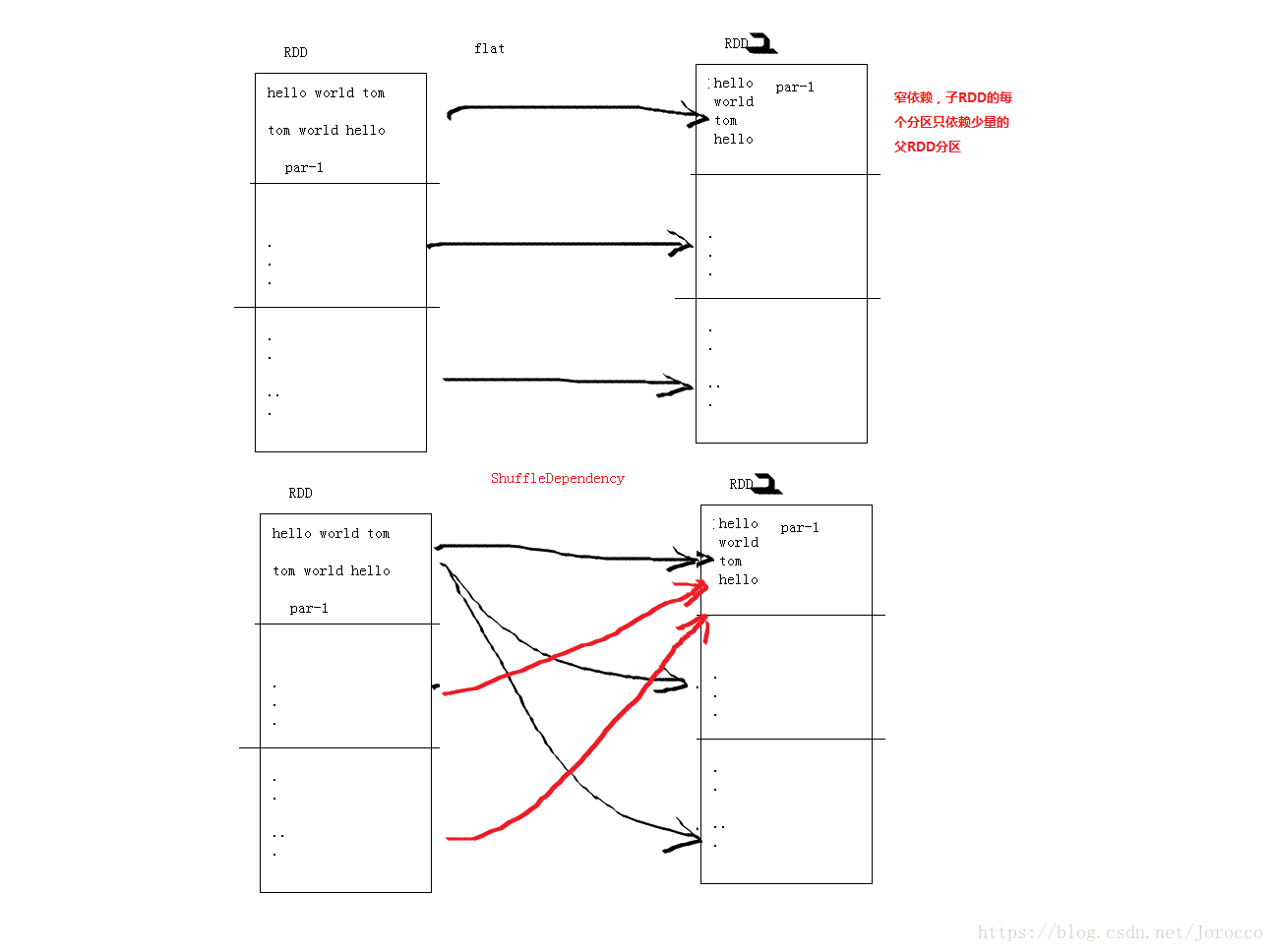
NarrowDependency(窄依賴): 子RDD的每個分割槽依賴於父RDD的少量分割槽。
|
/ \
---
|---- OneToOneDependency //父子RDD之間的分割槽存在一對一關係。
|---- RangeDependency //父RDD的一個分割槽範圍和子RDD存在一對一關係。
ShuffleDependency //依賴,在shuffle階段輸出時的一種依賴。
PruneDependency //在PartitionPruningRDD和其父RDD之間的依賴
//子RDD包含了父RDD的分割槽子集。4、建立Spark上下文
[本地模式,通過執行緒模擬]
本地後臺排程器
spark local[3] //3執行緒,模擬cluster叢集
spark local[*] //匹配cpu個數,
spark local[3,2] //3:3個執行緒,2最多重試次數。[相當於偽分散式]
StandaloneSchedulerBackend
spark local-cluster[N, cores, memory] //模擬spark叢集。[完全分散式]
StandaloneSchedulerBackend
spark spark://s201:7077 //連線到spark叢集上.
maxFailures
最多失敗次數:
1 //0和1等價,只執行一次。
2 //如果失敗,最多執行兩次.5、RDD持久化
跨操作進行RDD的記憶體式儲存。
持久化RDD時,節點上的每個分割槽都會儲存操作在記憶體中,以備在其他操作中進行重用。
快取技術是迭代式計算和互動式查詢的重要工具。使用persist()和cache()進行rdd的持久化。cache()是persist()一種。action第一次計算時會發生persist()。
spark的cache是容錯的,如果rdd的任何一個分割槽丟失了,都可以通過最初建立rdd的進行重新計算(RDD儲存的是程,不是資料)。
persist可以使用不同的儲存級別進行持久化。
MEMORY_ONLY //只在記憶體
MEMORY_AND_DISK
MEMORY_ONLY_SER //記憶體儲存(序列化)
MEMORY_AND_DISK_SER
DISK_ONLY //硬碟
MEMORY_ONLY_2 //帶有副本,2個
MEMORY_AND_DISK_2 //快速容錯。
OFF_HEAP
rdd.unpersist(); //刪除持久化資料資料傳遞: map(),filter()高階函式中訪問的物件被序列化到各個節點。每個節點都有一份拷貝。變數值並不會回傳到driver程式。
共享變數
spark通過廣播變數和累加器實現共享變數。
[廣播變數]
//建立廣播變數
val bc1 = sc.broadcast(Array(1,2,3))
bc1.value
[累加器]
val ac1 = sc.longaccumulator("ac1")
ac1.value
sc.parell..(1 to 10).map(_ * 2).map(e=>{ac1.add(1) ; e}).reduce(_+_)
ac1.value //10