
spark(三):blockManager、broadcast、cache、checkpoint
阿新 • • 發佈:2019-04-23
表示 廣播 心跳 ask fff 1.5 exec edi 所在 blockManager
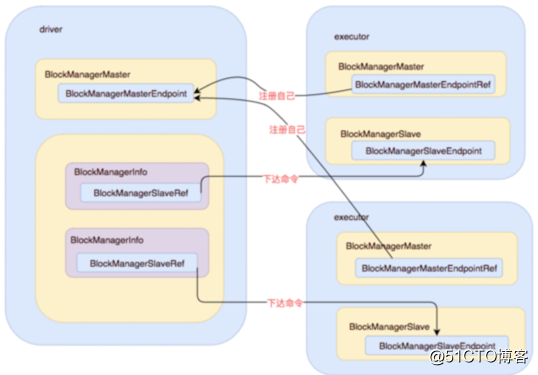
- Driver和executor上分別都會啟動blockManager,其中driver上擁有所有executor上的blockManager的引用;所有executor上的blockManager都持有driver上的blockManager的引用;
- blockManagerSlave會不斷向blockManagerMaster發送心跳,更新block信息等;
- BlockManager對象被創建的時候會創建出MemoryStore和DiskStore對象用以存取block,如果內存中擁有足夠的內存, 就 使用 MemoryStore存儲, 如果 不夠, 就 spill 到 磁盤中, 通過 DiskStore進行存儲。
- DiskStore 有一個DiskBlockManager,DiskBlockManager 主要用來創建並持有邏輯 blocks 與磁盤上的 blocks之間的映射,一個邏輯 block 通過 BlockId 映射到一個磁盤上的文件。 在 DiskStore 中會調用 diskManager.getFile 方法, 如果子文件夾不存在,會進行創建, 文件夾的命名方式為(spark-local-yyyyMMddHHmmss-xxxx, xxxx是一個隨機數), 所有的block都會存儲在所創建的folder裏面。
- MemoryStore 相對於DiskStore需要根據block id hash計算出文件路徑並將block存放到對應的文件裏面,MemoryStore管理block就顯得非常簡單:MemoryStore內部維護了一個hash map來管理所有的block,以block id為key將block存放到hash map中。而從MemoryStore中取得block則非常簡單,只需從hash map中取出block id對應的value即可。
- GET操作 如果 local 中存在就直接返回, 從本地獲取一個Block, 會先判斷如果是 useMemory, 直接從內存中取出, 如果是 useDisk, 會從磁盤中取出返回, 然後根據useMemory判斷是否在內存中緩存一下,方便下次獲取, 如果local 不存在, 從其他節點上獲取, 當然元信息是存在 drive上的,要根據我們上文中提到的 GETlocation 協議獲取 Block 所在節點位置, 然後到其他節點上獲取。
- PUT操作 操作之前會加鎖來避免多線程的問題, 存儲的時候會根據 存儲級別, 調用對應的是 memoryStore 還是 diskStore, 然後在具體存儲器上面調用 存儲接口。 如果有 replication 需求, 會把數據備份到其他的機器上面。
cache、persist、checkpoint
- 如果要對一個RDD進行持久化,只要對這個RDD調用cache()和persist()即可。
- cache()方法表示:使用非序列化的方式將RDD中的數據全部嘗試持久化到內存中。
- persist()方法表示:手動選擇持久化級別,並使用指定的方式進行持久化。默認緩存級別是StorageLevel.MEMORY_ONLY,也就是cache就是這個默認級別的。
- checkpoint是將數據持久化到HDFS或者硬盤。
- rdd.persist(StorageLevel.DISK_ONLY) 與 checkpoint 也有區別。前者雖然可以將 RDD 的 partition 持久化到磁盤,但該 partition 由 blockManager 管理。一旦 driver program 執行結束,也就是 executor 所在進程 CoarseGrainedExecutorBackend stop,blockManager 也會 stop,被 cache 到磁盤上的 RDD 也會被清空(整個 blockManager 使用的 local 文件夾被刪除)。而 checkpoint 將 RDD 持久化到 HDFS 或本地文件夾,如果不被手動 remove 掉( 話說怎麽 remove checkpoint 過的 RDD? ),是一直存在的,也就是說可以被下一個 driver program 使用,而 cached RDD 不能被其他 dirver program 使用。
broadcast、accumulator
- 廣播變量允許程序員將一個只讀的變量緩存在每臺機器上,而不用在任務之間傳遞變量。(註意是一個較大的只讀變量,不能修改)
- Accumulator是spark提供的累加器,顧名思義,該變量只能夠增加。
- 只有driver能獲取到Accumulator的值(使用value方法),Task只能對其做增加操作(使用 +=)
- 使用累加器的過程中只能使用一次action的操作才能保證結果的準確性。如果需要使用多次則使用cache或persist操作切斷依賴。
spark(三):blockManager、broadcast、cache、checkpoint