
hadoop家族知識框架簡介
一、hadoop生態圖:
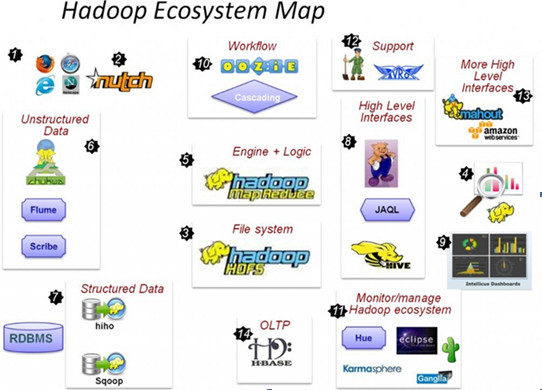
二、hadoop家族子專案:

三、hadoop框架:
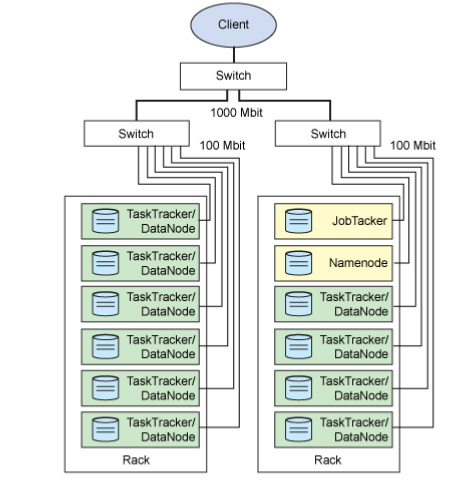
1、Namenode:
1)HDFS的守護程式
2) 紀錄檔案是如何分割成資料塊的,以及這些資料塊被儲存到哪些節點上
3)對記憶體和I/O進行集中管理
4)namenode 是個單點,發生故障將使叢集崩潰
2、Secondary Namenode:
1)監控HDFS狀態的輔助後臺程式
2) 每個叢集都有一個Secondary Namenode
3) 與NameNode進行通訊,定期儲存HDFS元資料快照
4) 當NameNode故障可以作為備用NameNode使用
3、DataNode:
1)每臺從伺服器都執行一個
2) 負責把HDFS資料塊讀寫到本地檔案系統
4、JobTracker:
1)用於處理作業(使用者提交程式碼)的後臺程式
2) 決定有哪些檔案參與處理,然後切割task並分配節點
3) 監控task,重啟失敗的task(在不同的節點)
4)每個叢集只有唯一一個JobTracker,位於Master節點
5、TaskTracker:
1)位於slave節點上,與datanode結合(程式碼與資料一起的原則)
2)管理各自節點上的task(由jobtracker分配)
3)每個節點只有一個tasktracker,但一個tasktracker可以啟動多個JVM,用於並行執行map或reduce任務
4) 與jobtracker互動
6、注:Master與Slave
1)Master:Namenode、Secondary Namenode、Jobtracker。瀏覽器(用於觀看 管理介面),其它Hadoop工具
2)Slave:Tasktracker、Datanode
3)Master不是唯一的
四、HDFS體系結構
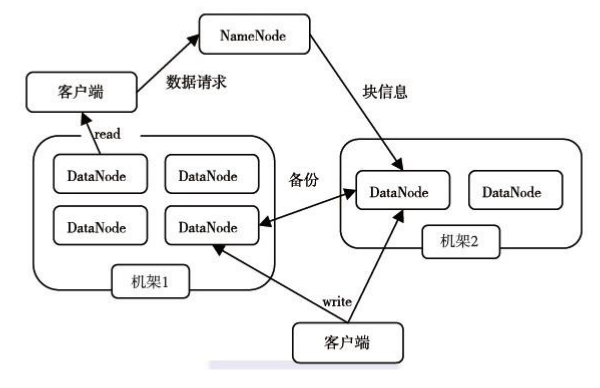
1)客戶端對HDFS讀取資料流程:
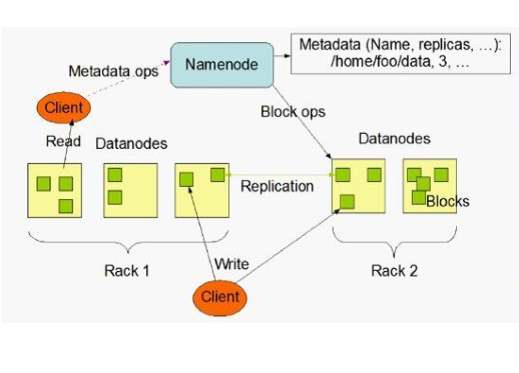
2)客戶端對HDFS寫入資料流程:
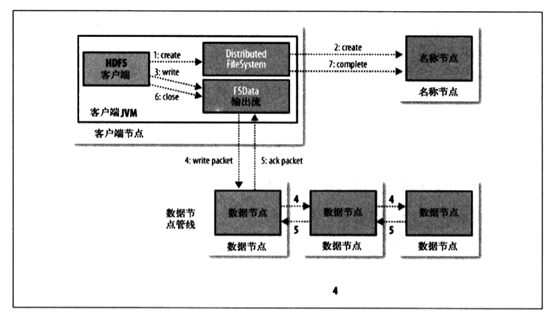
3)HDFS的可靠性有 : 冗餘副本策略、機架策略、 心跳機制、 安全模式、 校驗和 、回收站、 元資料保護、 快照機制
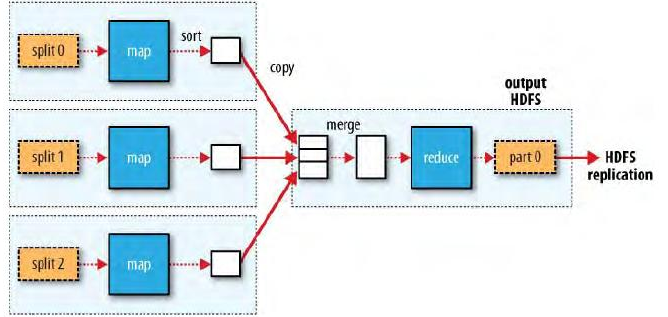
五、Map-Reduce:
六、Pig
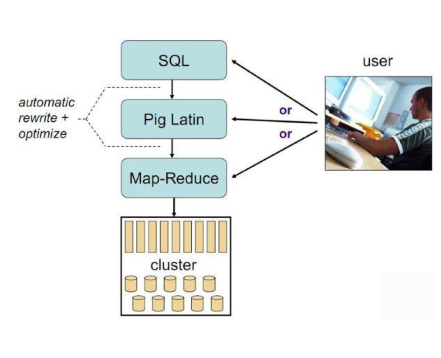
1)Hadoop客戶端
2) 使用類似於SQL的面向資料流的語言Pig Latin
3) Pig Latin可以完成排序,過濾,求和,聚組,關聯等操作,可以支援自定義函式
4) Pig自動把Pig Latin對映為Map-Reduce作業上傳到叢集執行,減少使用者編寫Java程式的苦惱
5)三種執行方式:Grunt shell,指令碼方式,嵌入式
七、Hbase
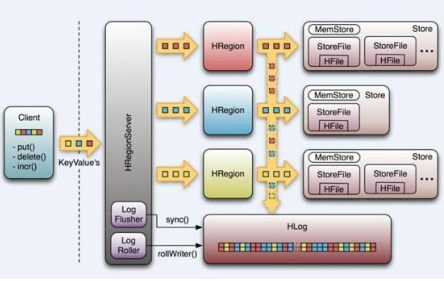
Hbase物理模型:
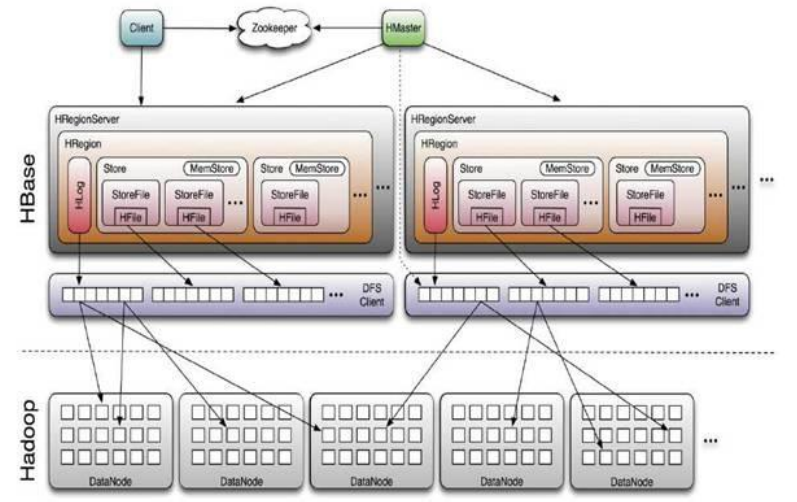
1)Google Bigtable的開源實現
2)列式資料庫
3) 可叢集化
4)可以使用shell、web、api等多種方式訪問
5)適合高讀寫(insert)的場景
6) HQL查詢語言
7) NoSQL的典型代表產品
八、Hive
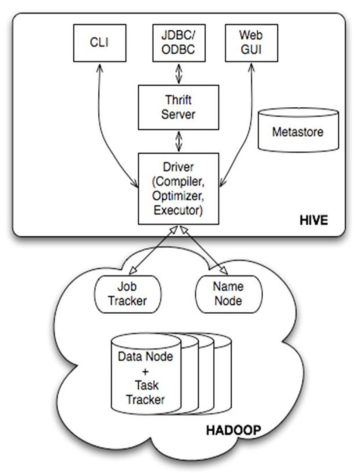
1)資料倉庫工具。可以把Hadoop下的原始結構化資料變成Hive中的表
2) 支援一種與SQL幾乎完全相同的語言HiveQL。除了不支援更新、索引和事務,幾乎SQL的其它特徵都能支援
3) 可以看成是從SQL到Map-Reduce的對映器
4) 提供shell、JDBC/ODBC、Thrift、Web等介面
九、Zookeeper
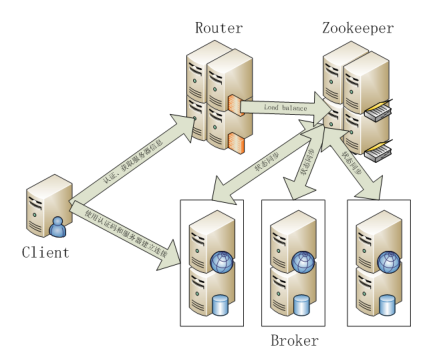
1)Google Chubby的開源實現
2)用於協調分散式系統上的各種服務。例如確認訊息是否準確到達,防止單點失效,處理負載均衡等
3) 應用場景:Hbase,實現Namenode自動切換
4) 工作原理:領導者,跟隨者以及選舉過程
十、Sqoop
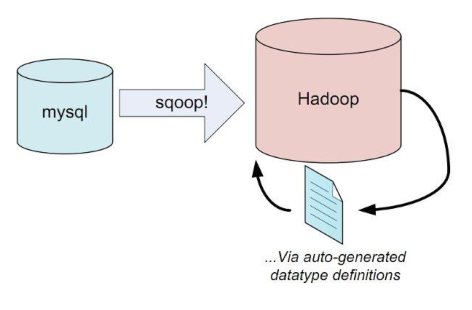
1)用於在Hadoop和關係型資料庫之間交換資料
2)通過JDBC介面連入關係型資料庫
十一、Avro

1)資料序列化工具,由Hadoop的創始人Doug Cutting主持開發
2)用於支援大批量資料交換的應用。支援二進位制序列化方式,可以便捷,快速地處理大量資料
3)動態語言友好,Avro提供的機制使動態語言可以方便地處理 Avro資料。
4) Thrift介面
十二、Chukwa

1)架構在Hadoop之上的資料採集與分析框架
2) 主要進行日誌採集和分析
3) 通過安裝在收集節點的“代理”採集最原始的日誌資料
4) 代理將資料發給收集器
5) 收集器定時將資料寫入Hadoop叢集
6) 指定定時啟動的Map-Reduce作業隊資料進行加工處理和分析
7) Hadoop基礎管理中心(HICC)最終展示資料
十三、Cassandra
1)NoSQL,分散式的Key-Value型資料庫,由Facebook貢獻
2) 與Hbase類似,也是借鑑Google Bigtable的思想體系
3)只有順序寫,沒有隨機寫的設計,滿足高負荷情形的效能需求