
Flume基本環境搭建以及原理
系統:CentOS6.5
JDK:1.8.0_144
Flume:flume-ng-1.6.0-cdh5.12.0
一、什麼是Flume
flume 作為 cloudera 開發的實時日誌收集系統,受到了業界的認可與廣泛應用。Flume 初始的發行版本目前被統稱為 Flume OG(original generation),屬於 cloudera。但隨著 FLume 功能的擴充套件,Flume OG 程式碼工程臃腫、核心元件設計不合理、核心配置不標準等缺點暴露出來,尤其是在 Flume OG 的最後一個發行版本 0.94.0 中,日誌傳輸不穩定的現象尤為嚴重,為了解決這些問題,2011 年 10 月 22 號,cloudera 完成了 Flume-728,對 Flume 進行了里程碑式的改動:重構核心元件、核心配置以及程式碼架構,重構後的版本統稱為 Flume NG(next generation);改動的另一原因是將 Flume 納入 apache 旗下,cloudera Flume 改名為 Apache Flume。
flume的特點:
flume是一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的系統。支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(比如文字、HDFS、Hbase等)的能力 。
flume的資料流由事件(Event)貫穿始終。事件是Flume的基本資料單位,它攜帶日誌資料(位元組陣列形式)並且攜帶有頭資訊,這些Event由Agent外部的Source生成,當Source捕獲事件後會進行特定的格式化,然後Source會把事件推入(單個或多個)Channel中。你可以把Channel看作是一個緩衝區,它將儲存事件直到Sink處理完該事件。Sink負責持久化日誌或者把事件推向另一個Source。
flume的可靠性 :
當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:end-to-end(收到資料agent首先將event寫到磁碟上,當資料傳送成功後,再刪除;如果資料傳送失敗,可以重新發送。),Store on failure(這也是scribe採用的策略,當資料接收方crash時,將資料寫到本地,待恢復後,繼續傳送),Besteffort(資料傳送到接收方後,不會進行確認)。
flume的可恢復性:
還是靠Channel。推薦使用FileChannel,事件持久化在本地檔案系統裡(效能較差)。
二、Flume工作原理
Flume的資料流由事件(Event)貫穿始終。事件是Flume的基本資料單位,它攜帶日誌資料(位元組陣列形式)並且攜帶有頭資訊,這些Event由Agent外部的Source生成,當Source捕獲事件後會進行特定的格式化,然後Source會把事件推入(單個或多個)Channel中。可以把Channel看作是一個緩衝區,它將儲存事件直到Sink處理完該事件。Sink負責持久化日誌或者把事件推向另一個Source。以下是Flume的一些核心概念:
(1)Events:一個數據單元,帶有一個可選的訊息頭,可以是日誌記錄、avro 物件等。
(2)Agent:JVM中一個獨立的Flume程序,每臺機器執行一個Agent,但一個Agent可以包含多個Source、Channel、Sink元件。
(3)Client:運行於一個獨立執行緒,用於生產資料並將其傳送給Agent。
(4)Source:用來消費傳遞到該元件的Event,從Client收集資料,傳遞給Channel。
(5)Channel:中轉Event的一個臨時儲存,儲存Source元件傳遞過來的Event,其實就是連線 Source 和 Sink ,有點像一個訊息佇列。
(6)Sink:從Channel收集資料,執行在一個獨立執行緒。
Flume以Agent為最小的獨立執行單位,一個Agent就是一個JVM。單Agent由Source、Sink和Channel三大元件構成,如下圖所示:
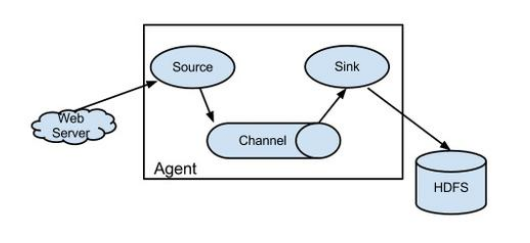
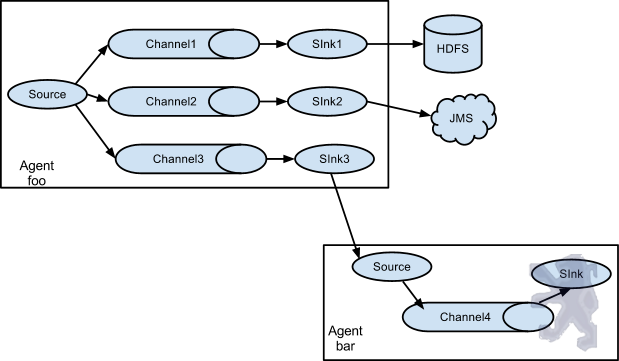
值得注意的是,Flume提供了大量內建的Source、Channel和Sink型別。不同型別的Source、Channel和Sink可以自由組合。組合方式基於使用者設定的配置檔案,非常靈活。比如:Channel可以把事件暫存在記憶體裡,也可以持久化到本地硬碟上;Sink可以把日誌寫入HDFS、HBase、ES甚至是另外一個Source等等。Flume支援使用者建立多級流,也就是說多個Agent可以協同工作,並且支援Fan-in、Fan-out、Contextual Routing、Backup Routes,這也正是NB之處。如圖所示:
圖1
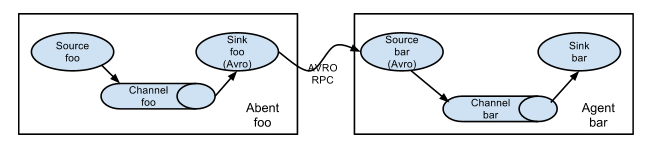
圖2
三、下載安裝
1.需要JDK1.6+
2.下載版本分為CDH和Apache版本,如果是個人機器叢集安裝,建議使用CDH版本,CDH的各元件的版本號要對應
CDH5各元件下載地址:http://archive.cloudera.com/cdh5/cdh/5/
3.將下載的包解壓出來之後就已經完成了50%,剩下的內容就需要修改一些配置檔案
4.設定環境變數
vim ~/.bash_profile
FLUME_HOME="/opt/module/flume" export PATH=$PATH:$FLUME_HOME/bin
source ~/.bash_profile
驗證
/opt/module/flume/bin/flume-ng version

四、修改配置檔案

# 指定Agent的元件名稱 sunny.sources = so1 sunny.channels = ch1 sunny.sinks = si1 # 指定Flume source要監聽的路徑(logs/flume目錄要提前建立好) sunny.sources.so1.type = spooldir sunny.sources.so1.spoolDir = /usr/sunny/logs/flume # 指定Flume sink sunny.sinks.si1.type = logger # 繫結source和sink到channel上 sunny.sinks.si1.channel = ch1 sunny.sources.so1.channels = ch1 # 指定Flume channel sunny.channels.ch1.type = memory sunny.channels.ch1.capacity = 1000 sunny.channels.ch1.transactionCapacity = 100
五、啟動
cd /opt/module/flume/ bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name sunny -Dflume.root.logger=INFO,console
| 引數 | 作用 | 舉例 |
|---|---|---|
| –conf 或 -c | 指定配置資料夾,包含flume-env.sh和log4j的配置檔案 | –conf conf |
| –conf-file 或 -f | 配置檔案地址 | –conf-file conf/flume.conf |
| –name 或 -n | agent名稱 | –name a1 |
| -z | zookeeper連線字串 | -z zkhost:2181,zkhost1:2181 |
| -p | zookeeper中的儲存路徑字首 | -p /flume |
然後另開一個客戶端,新增一個日誌檔案,編輯內容
cd /usr/sunny/logs/flume vim test.log
在開啟的客戶端就可以看到內容

六、其他source
1.Avro
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel that buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
// 執行FlumeAgent,監聽本機的44444埠 $ flume-ng agent -c conf -f example/netcat.conf -n a1 -Dflume.root.logger=INFO,console
// 開啟另一終端,通過telnet登入localhost的44444,輸入測試資料 $ telnet localhost 44444
2.Spool
Spool用於監測配置的目錄下新增的檔案,並將檔案中的資料讀取出來。需要注意兩點:拷貝到spool目錄下的檔案不可以再開啟編輯、spool目錄下不可包含相應的子目錄。具體示例如下:
// 建立兩個Flume配置檔案 $ cd app/cdh/flume-1.6.0-cdh5.7.1 $ cp conf/flume-conf.properties.template example/spool1.conf $ cp conf/flume-conf.properties.template example/spool2.conf
// 配置spool1.conf用於監控目錄avro_data的檔案,將檔案內容傳送到本地60000埠 $ vim example/spool1.conf # Namethe components local1.sources= r1 local1.sinks= k1 local1.channels= c1 # Source local1.sources.r1.type= spooldir local1.sources.r1.spoolDir= /home/hadoop/avro_data # Sink local1.sinks.k1.type= avro local1.sinks.k1.hostname= localhost local1.sinks.k1.port= 60000 #Channel local1.channels.c1.type= memory # Bindthe source and sink to the channel local1.sources.r1.channels= c1 local1.sinks.k1.channel= c1
// 配置spool2.conf用於從本地60000埠獲取資料並寫入HDFS # Namethe components a1.sources= r1 a1.sinks= k1 a1.channels= c1 # Source a1.sources.r1.type= avro a1.sources.r1.channels= c1 a1.sources.r1.bind= localhost a1.sources.r1.port= 60000 # Sink a1.sinks.k1.type= hdfs a1.sinks.k1.hdfs.path= hdfs://localhost:9000/user/wcbdd/flumeData a1.sinks.k1.rollInterval= 0 a1.sinks.k1.hdfs.writeFormat= Text a1.sinks.k1.hdfs.fileType= DataStream # Channel a1.channels.c1.type= memory a1.channels.c1.capacity= 10000 # Bind the source and sink to the channel a1.sources.r1.channels= c1 a1.sinks.k1.channel= c1
// 分別開啟兩個終端,執行如下命令啟動兩個Flume Agent $ flume-ng agent -c conf -f example/spool2.conf -n a1 $ flume-ng agent -c conf -f example/spool1.conf -n local1
// 檢視本地檔案系統中需要監控的avro_data目錄內容 $ cd avro_data $ cat avro_data.txt
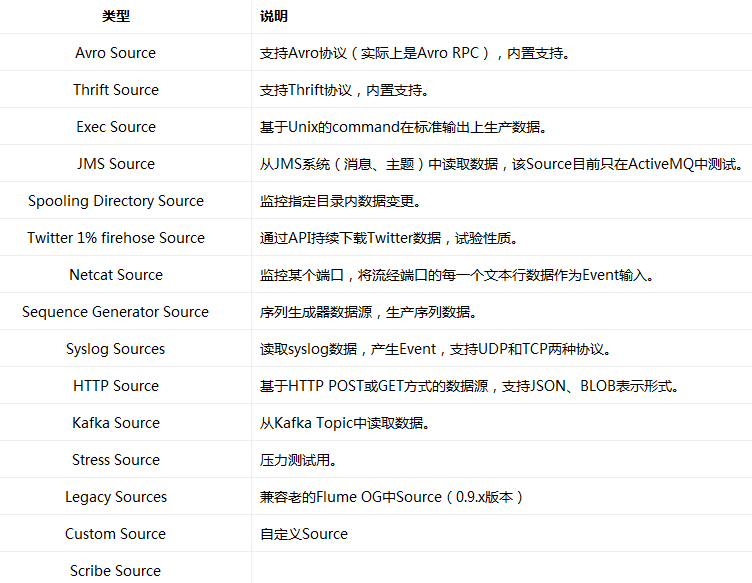
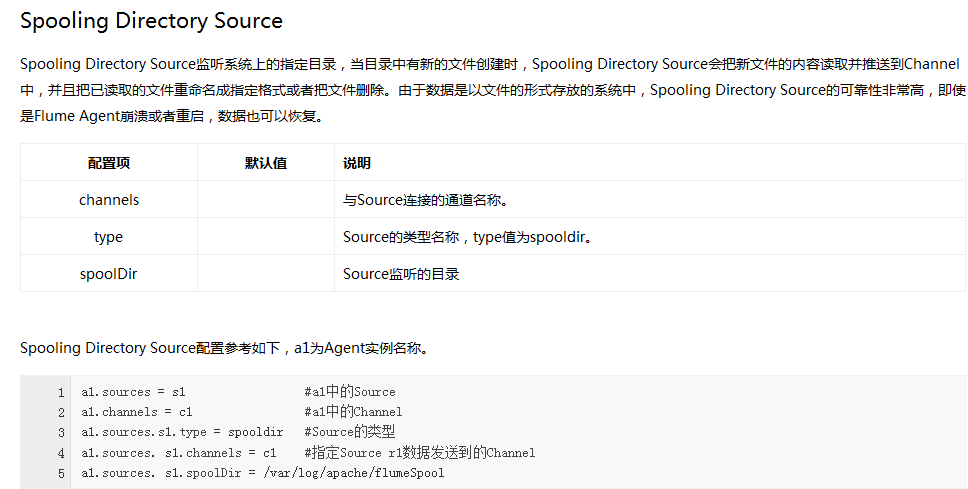
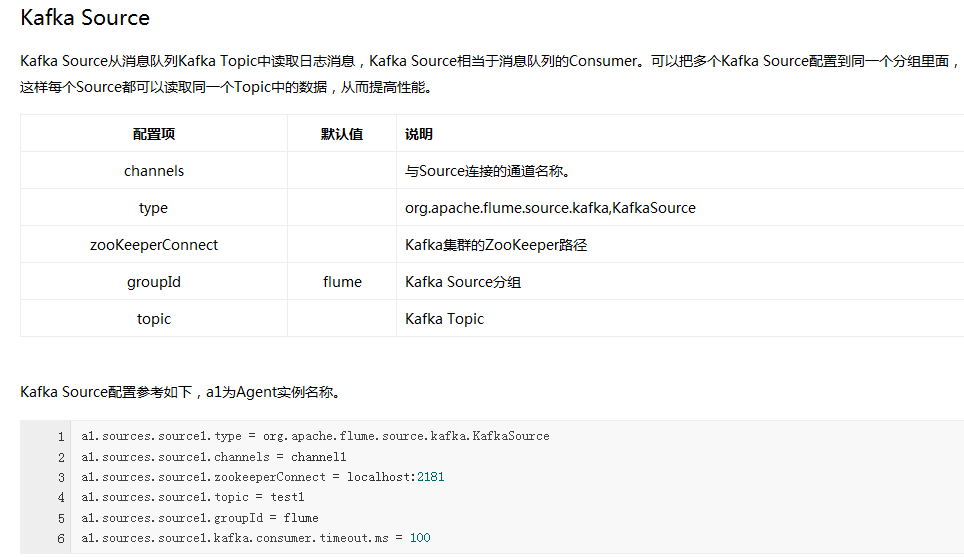
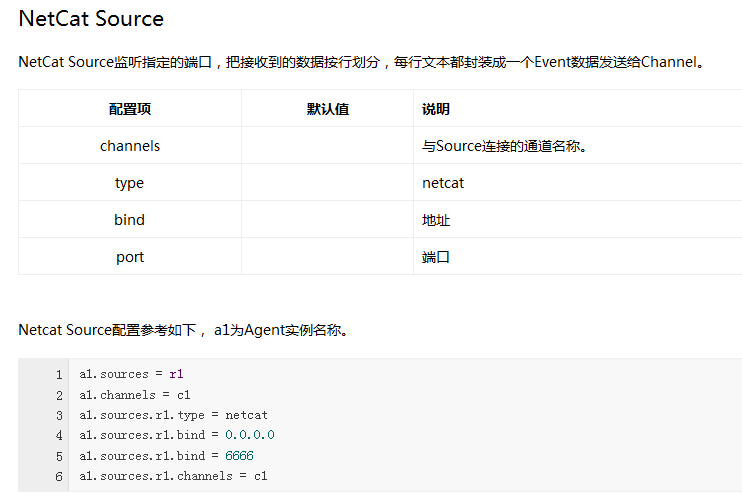
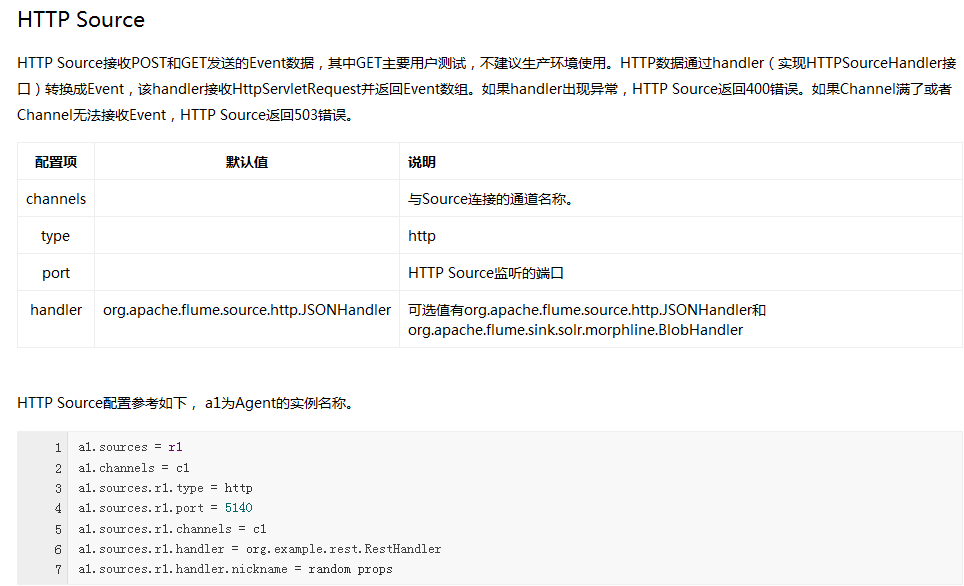
Flume內建了大量的Source,其中Avro Source、Thrift Source、Spooling Directory Source、Kafka Source具有較好的效能和較廣泛的使用場景。下面是Source的一些參考資料:
(1)*******
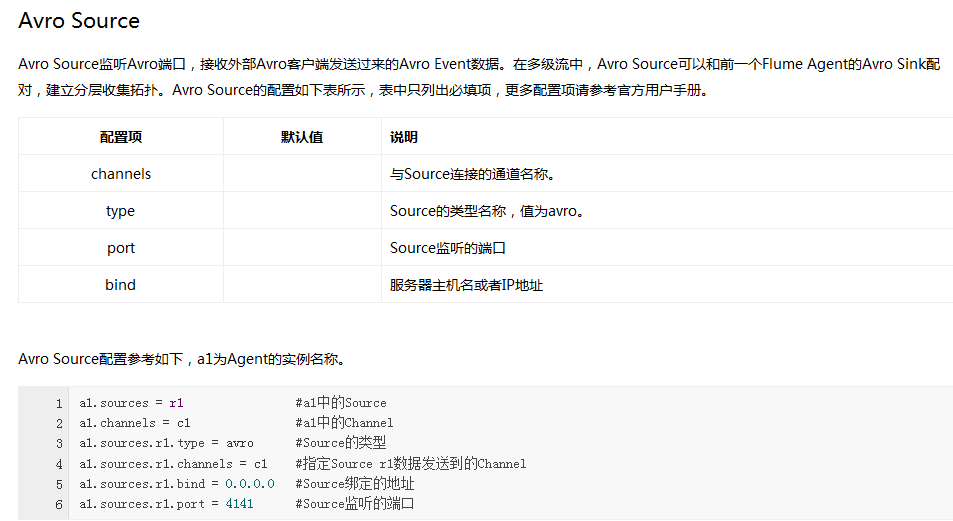
(2)*******
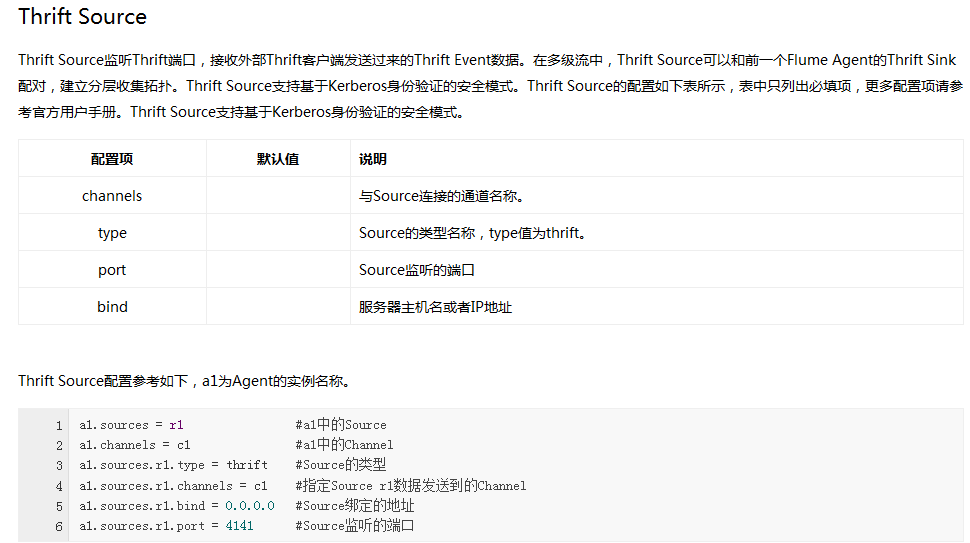
(3)*******
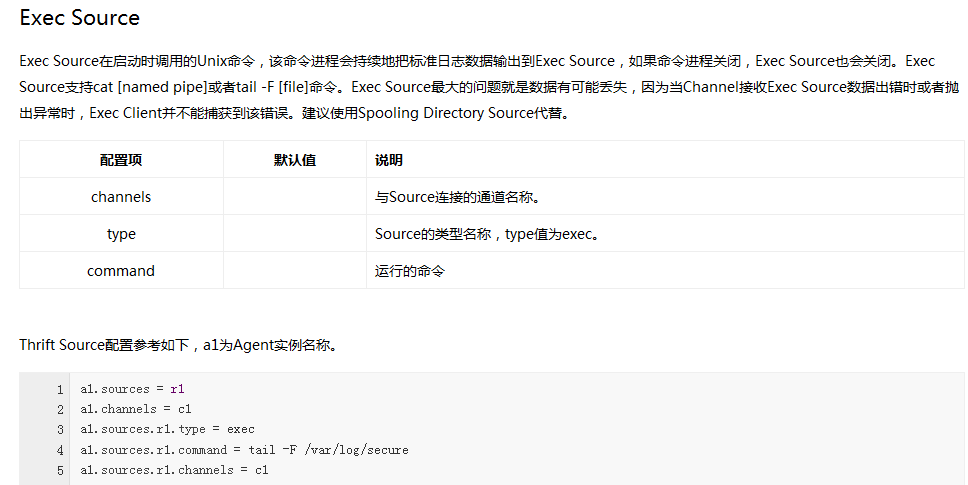
(4)*******
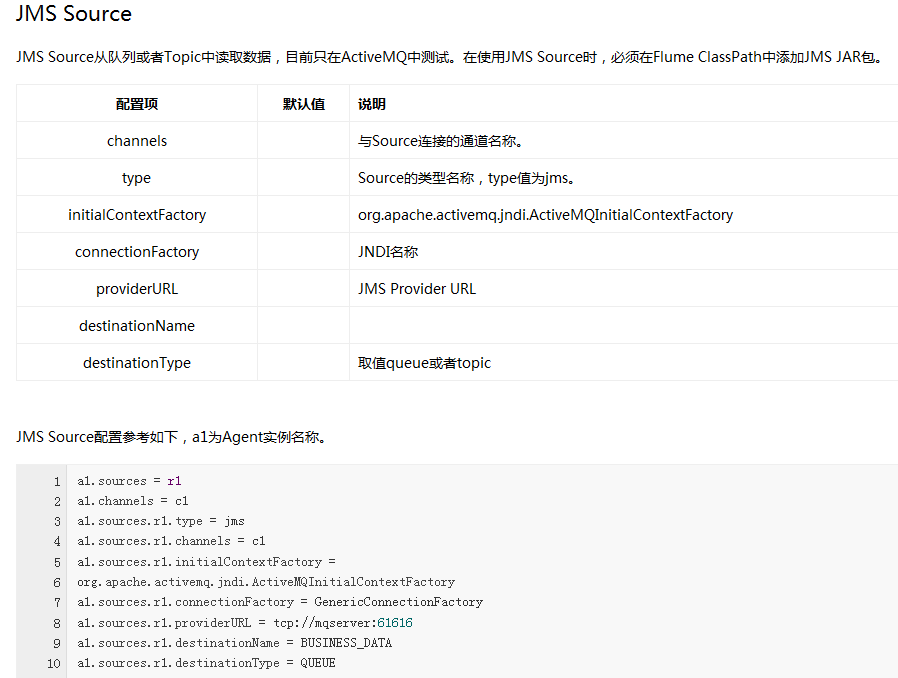
(5)*******
(6)*******
(7)*******
(8)*******
七、Flume所支援的Sources、Channels、Sinks
| Sources | Channels | Sinks |
|---|---|---|
|
|
|
轉發自:https://www.cnblogs.com/sunny3096/p/7813921.html