
結巴中文分詞的學習和使用
結巴分詞
演算法
(1) 基於Trie樹結構實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的有向無環圖(DAG);
(2) 採用了動態規劃查詢最大概率路徑, 找出基於詞頻的最大切分組合;
(3) 對於未登入詞,採用了基於漢字成詞能力的HMM模型,使用了Viterbi演算法。
三種分詞模式
(1) 精確模式:試圖將句子最精確地切開,適合文字分析;
(2) 全模式:把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義問題;
(3) 搜尋引擎模式:在精確模式的基礎上,對長詞再次切分,提高召回率,適合用於搜尋引擎分詞。
安裝
程式碼對 Python 2/3 均相容
- 全自動安裝:
easy_install jieba或者pip install jieba/pip3 install jieba - 半自動安裝:先下載 http://pypi.python.org/pypi/jieba/,解壓後執行
python setup.py install - 手動安裝:將 jieba 目錄放置於當前目錄或者 site-packages 目錄
- 通過
import jieba來引用
使用手動安裝的方式
使用
jieba.cut方法接受三個輸入引數: 需要分詞的字串;cut_all 引數用來控制是否採用全模式;HMM 引數用來控制是否使用 HMM 模型jieba.cut_for_search方法接受兩個引數:需要分詞的字串;是否使用 HMM 模型。該方法適合用於搜尋引擎構建倒排索引的分詞,粒度比較細- 待分詞的字串可以是 unicode 或 UTF-8 字串、GBK 字串。注意:不建議直接輸入 GBK 字串,可能無法預料地錯誤解碼成 UTF-8
jieba.cut以及jieba.cut_for_search返回的結構都是一個可迭代的 generator,可以使用 for 迴圈來獲得分詞後得到的每一個詞語(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 listjieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定義分詞器,可用於同時使用不同詞典。jieba.dt 為預設分詞器,所有全域性分詞相關函式都是該分詞器的對映。
例項:
# encoding=utf-8
import jieba
seg_list = jieba.cut("我來到北京清華大學", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我來到北京清華大學", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精確模式
seg_list = jieba.cut("他來到了網易杭研大廈") # 預設是精確模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明碩士畢業於中國科學院計算所,後在日本京都大學深造") # 搜尋引擎模式
print(", ".join(seg_list))結果:
============= RESTART: /Users/zhanglipeng/Documents/testjieba.py =============
Building prefix dict from the default dictionary ...
Dumping model to file cache /var/folders/kp/3zwp94853sg8jtb7cjrywlxw0000gn/T/jieba.cache
Loading model cost 0.818 seconds.
Prefix dict has been built succesfully.
Full Mode: 我/ 來到/ 北京/ 清華/ 清華大學/ 華大/ 大學
Default Mode: 我/ 來到/ 北京/ 清華大學
他, 來到, 了, 網易, 杭研, 大廈
小明, 碩士, 畢業, 於, 中國, 科學, 學院, 科學院, 中國科學院, 計算, 計算所, ,, 後, 在, 日本, 京都, 大學, 日本京都大學, 深造
借鑑其他博文,程式碼如下:
import jieba
import jieba.analyse
import xlwt #寫入Excel表的庫
if __name__=="__main__":
wbk = xlwt.Workbook(encoding = 'utf-8')
sheet = wbk.add_sheet("wordCount")#Excel單元格名字
word_lst = []
key_list=[]
for line in open('xiaoshuo.txt','r',encoding="utf-8"):#test.txt是需要分詞統計的文件
item = line.strip('\n\r').split('\t') #製表格切分
# print item
tags = jieba.analyse.extract_tags(item[0]) #jieba分詞
for t in tags:
word_lst.append(t)
word_dict= {}
with open("wordCount.txt",'w',encoding="utf-8") as wf2: #開啟檔案
for item in word_lst:
if item not in word_dict: #統計數量
word_dict[item] = 1
else:
word_dict[item] += 1
orderList=list(word_dict.values())
orderList.sort(reverse=True)
# print orderList
for i in range(len(orderList)):
for key in word_dict:
if word_dict[key]==orderList[i]:
wf2.write(key+' '+str(word_dict[key])+'\n') #寫入txt文件
key_list.append(key)
word_dict[key]=0
for i in range(len(key_list)):
sheet.write(i, 1, label = orderList[i])
sheet.write(i, 0, label = key_list[i])
wbk.save('wordCount.xls') #儲存為 wordCount.xls檔案
執行,報錯:
================= RESTART: /Users/zhanglipeng/Desktop/ok.py =================
Traceback (most recent call last):
File "/Users/zhanglipeng/Desktop/ok.py", line 2, in <module>
import numpy as np
ModuleNotFoundError: No module named 'xlwt'
在終端進行操作及系統響應如下:
zhanglipengdeMacBook-Pro:~ zhanglipeng$ python3 -m pip install --upgrade pip
Collecting pip
Downloading https://files.pythonhosted.org/packages/c2/d7/90f34cb0d83a6c5631cf71dfe64cc1054598c843a92b400e55675cc2ac37/pip-18.1-py2.py3-none-any.whl (1.3MB)
100% |████████████████████████████████| 1.3MB 3.6MB/s
Installing collected packages: pip
Found existing installation: pip 10.0.1
Uninstalling pip-10.0.1:
Successfully uninstalled pip-10.0.1
Successfully installed pip-18.1
zhanglipengdeMacBook-Pro:~ zhanglipeng$ sudo pip3 install xlwt
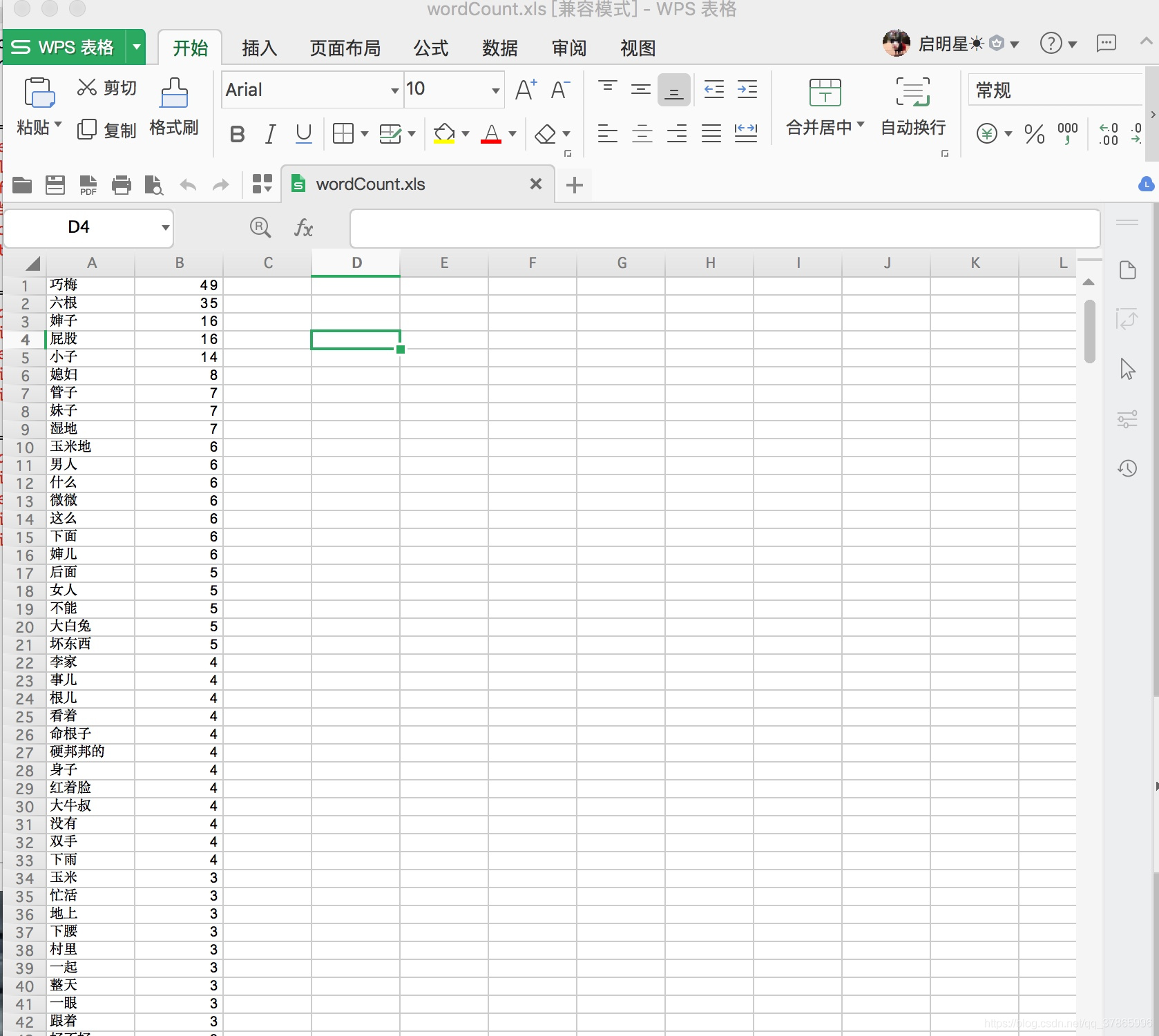
小說原文不便分享了,隨便個小說網竟然帶了顏色。。。
執行結果:
本次僅使用分詞功能、詞頻統計功能,更多請見官方文件:https://github.com/fxsjy/jieba
官方原文如下:
主要功能
- 分詞
jieba.cut方法接受三個輸入引數: 需要分詞的字串;cut_all 引數用來控制是否採用全模式;HMM 引數用來控制是否使用 HMM 模型jieba.cut_for_search方法接受兩個引數:需要分詞的字串;是否使用 HMM 模型。該方法適合用於搜尋引擎構建倒排索引的分詞,粒度比較細- 待分詞的字串可以是 unicode 或 UTF-8 字串、GBK 字串。注意:不建議直接輸入 GBK 字串,可能無法預料地錯誤解碼成 UTF-8
jieba.cut以及jieba.cut_for_search返回的結構都是一個可迭代的 generator,可以使用 for 迴圈來獲得分詞後得到的每一個詞語(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回 listjieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定義分詞器,可用於同時使用不同詞典。jieba.dt為預設分詞器,所有全域性分詞相關函式都是該分詞器的對映。
程式碼示例
輸出:
- 新增自定義詞典
載入詞典
- 開發者可以指定自己自定義的詞典,以便包含 jieba 詞庫裡沒有的詞。雖然 jieba 有新詞識別能力,但是自行新增新詞可以保證更高的正確率
- 用法: jieba.load_userdict(file_name) # file_name 為檔案類物件或自定義詞典的路徑
- 詞典格式和
dict.txt一樣,一個詞佔一行;每一行分三部分:詞語、詞頻(可省略)、詞性(可省略),用空格隔開,順序不可顛倒。file_name若為路徑或二進位制方式開啟的檔案,則檔案必須為 UTF-8 編碼。 - 詞頻省略時使用自動計算的能保證分出該詞的詞頻。
例如:
-
更改分詞器(預設為
jieba.dt)的tmp_dir和cache_file屬性,可分別指定快取檔案所在的資料夾及其檔名,用於受限的檔案系統。 -
範例:
-
自定義詞典:https://github.com/fxsjy/jieba/blob/master/test/userdict.txt
-
用法示例:https://github.com/fxsjy/jieba/blob/master/test/test_userdict.py
-
之前: 李小福 / 是 / 創新 / 辦 / 主任 / 也 / 是 / 雲 / 計算 / 方面 / 的 / 專家 /
-
載入自定義詞庫後: 李小福 / 是 / 創新辦 / 主任 / 也 / 是 / 雲端計算 / 方面 / 的 / 專家 /
-
-
調整詞典
-
使用
add_word(word, freq=None, tag=None)和del_word(word)可在程式中動態修改詞典。 -
使用
suggest_freq(segment, tune=True)可調節單個詞語的詞頻,使其能(或不能)被分出來。 -
注意:自動計算的詞頻在使用 HMM 新詞發現功能時可能無效。
程式碼示例:
- "通過使用者自定義詞典來增強歧義糾錯能力" --- https://github.com/fxsjy/jieba/issues/14
- 關鍵詞提取
基於 TF-IDF 演算法的關鍵詞抽取
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 為待提取的文字
- topK 為返回幾個 TF/IDF 權重最大的關鍵詞,預設值為 20
- withWeight 為是否一併返回關鍵詞權重值,預設值為 False
- allowPOS 僅包括指定詞性的詞,預設值為空,即不篩選
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 例項,idf_path 為 IDF 頻率檔案
程式碼示例 (關鍵詞提取)
https://github.com/fxsjy/jieba/blob/master/test/extract_tags.py
關鍵詞提取所使用逆向檔案頻率(IDF)文字語料庫可以切換成自定義語料庫的路徑
- 用法: jieba.analyse.set_idf_path(file_name) # file_name為自定義語料庫的路徑
- 自定義語料庫示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
- 用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_idfpath.py
關鍵詞提取所使用停止詞(Stop Words)文字語料庫可以切換成自定義語料庫的路徑
- 用法: jieba.analyse.set_stop_words(file_name) # file_name為自定義語料庫的路徑
- 自定義語料庫示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
- 用法示例:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_stop_words.py
關鍵詞一併返回關鍵詞權重值示例
基於 TextRank 演算法的關鍵詞抽取
- jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 直接使用,介面相同,注意預設過濾詞性。
- jieba.analyse.TextRank() 新建自定義 TextRank 例項
演算法論文: TextRank: Bringing Order into Texts
基本思想:
- 將待抽取關鍵詞的文字進行分詞
- 以固定視窗大小(預設為5,通過span屬性調整),詞之間的共現關係,構建圖
- 計算圖中節點的PageRank,注意是無向帶權圖
使用示例:
- 詞性標註
jieba.posseg.POSTokenizer(tokenizer=None)新建自定義分詞器,tokenizer引數可指定內部使用的jieba.Tokenizer分詞器。jieba.posseg.dt為預設詞性標註分詞器。- 標註句子分詞後每個詞的詞性,採用和 ictclas 相容的標記法。
- 用法示例
- 並行分詞
-
原理:將目標文字按行分隔後,把各行文字分配到多個 Python 程序並行分詞,然後歸併結果,從而獲得分詞速度的可觀提升
-
基於 python 自帶的 multiprocessing 模組,目前暫不支援 Windows
-
用法:
jieba.enable_parallel(4)# 開啟並行分詞模式,引數為並行程序數jieba.disable_parallel()# 關閉並行分詞模式
-
例子:https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
-
實驗結果:在 4 核 3.4GHz Linux 機器上,對金庸全集進行精確分詞,獲得了 1MB/s 的速度,是單程序版的 3.3 倍。
-
注意:並行分詞僅支援預設分詞器
jieba.dt和jieba.posseg.dt。
- Tokenize:返回詞語在原文的起止位置
- 注意,輸入引數只接受 unicode
- 預設模式
- 搜尋模式
- ChineseAnalyzer for Whoosh 搜尋引擎
- 引用:
from jieba.analyse import ChineseAnalyzer - 用法示例:https://github.com/fxsjy/jieba/blob/master/test/test_whoosh.py
- 命令列分詞
使用示例:python -m jieba news.txt > cut_result.txt
命令列選項(翻譯):
--help 選項輸出:
延遲載入機制
jieba 採用延遲載入,import jieba 和 jieba.Tokenizer() 不會立即觸發詞典的載入,一旦有必要才開始載入詞典構建字首字典。如果你想手工初始 jieba,也可以手動初始化。
在 0.28 之前的版本是不能指定主詞典的路徑的,有了延遲載入機制後,你可以改變主詞典的路徑:
例子: https://github.com/fxsjy/jieba/blob/master/test/test_change_dictpath.py
其他詞典
-
佔用記憶體較小的詞典檔案 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.small
-
支援繁體分詞更好的詞典檔案 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.big
下載你所需要的詞典,然後覆蓋 jieba/dict.txt 即可;或者用 jieba.set_dictionary('data/dict.txt.big')
其他語言實現
結巴分詞 Java 版本
作者:piaolingxue 地址:https://github.com/huaban/jieba-analysis
結巴分詞 C++ 版本
作者:yanyiwu 地址:https://github.com/yanyiwu/cppjieba
結巴分詞 Node.js 版本
作者:yanyiwu 地址:https://github.com/yanyiwu/nodejieba
結巴分詞 Erlang 版本
作者:falood 地址:https://github.com/falood/exjieba
結巴分詞 R 版本
作者:qinwf 地址:https://github.com/qinwf/jiebaR
結巴分詞 iOS 版本
作者:yanyiwu 地址:https://github.com/yanyiwu/iosjieba
結巴分詞 PHP 版本
作者:fukuball 地址:https://github.com/fukuball/jieba-php
結巴分詞 .NET(C#) 版本
作者:anderscui 地址:https://github.com/anderscui/jieba.NET/
結巴分詞 Go 版本
- 作者: wangbin 地址: https://github.com/wangbin/jiebago
- 作者: yanyiwu 地址: https://github.com/yanyiwu/gojieba
結巴分詞Android版本
- 作者 Dongliang.W 地址:https://github.com/452896915/jieba-android
系統整合
分詞速度
- 1.5 MB / Second in Full Mode
- 400 KB / Second in Default Mode
- 測試環境: Intel(R) Core(TM) i7-2600 CPU @ 3.4GHz;《圍城》.txt
常見問題
1. 模型的資料是如何生成的?
詳見: https://github.com/fxsjy/jieba/issues/7
2. “臺中”總是被切成“臺 中”?(以及類似情況)
P(臺中) < P(臺)×P(中),“臺中”詞頻不夠導致其成詞概率較低
解決方法:強制調高詞頻
jieba.add_word('臺中') 或者 jieba.suggest_freq('臺中', True)
3. “今天天氣 不錯”應該被切成“今天 天氣 不錯”?(以及類似情況)
解決方法:強制調低詞頻
jieba.suggest_freq(('今天', '天氣'), True)
或者直接刪除該詞 jieba.del_word('今天天氣')
4. 切出了詞典中沒有的詞語,效果不理想?
解決方法:關閉新詞發現
jieba.cut('豐田太省了', HMM=False) jieba.cut('我們中出了一個叛徒', HMM=False)
更多問題請點選:https://github.com/fxsjy/jieba/issues?sort=updated&state=closed
修訂歷史
https://github.com/fxsjy/jieba/blob/master/Changelog
jieba
"Jieba" (Chinese for "to stutter") Chinese text segmentation: built to be the best Python Chinese word segmentation module.
Features
- Support three types of segmentation mode:
- Accurate Mode attempts to cut the sentence into the most accurate segmentations, which is suitable for text analysis.
- Full Mode gets all the possible words from the sentence. Fast but not accurate.
- Search Engine Mode, based on the Accurate Mode, attempts to cut long words into several short words, which can raise the recall rate. Suitable for search engines.
- Supports Traditional Chinese
- Supports customized dictionaries
- MIT License
Online demo
http://jiebademo.ap01.aws.af.cm/
(Powered by Appfog)
Usage
- Fully automatic installation:
easy_install jiebaorpip install jieba - Semi-automatic installation: Download http://pypi.python.org/pypi/jieba/ , run
python setup.py installafter extracting. - Manual installation: place the
jiebadirectory in the current directory or pythonsite-packagesdirectory. import jieba.
Algorithm
- Based on a prefix dictionary structure to achieve efficient word graph scanning. Build a directed acyclic graph (DAG) for all possible word combinations.
- Use dynamic programming to find the most probable combination based on the word frequency.
- For unknown words, a HMM-based model is used with the Viterbi algorithm.
Main Functions
- Cut
- The
jieba.cutfunction accepts three input parameters: the first parameter is the string to be cut; the second parameter iscut_all, controlling the cut mode; the third parameter is to control whether to use the Hidden Markov Model. jieba.cut_for_searchaccepts two parameter: the string to be cut; whether to use the Hidden Markov Model. This will cut the sentence into short words suitable for search engines.- The input string can be an unicode/str object, or a str/bytes object which is encoded in UTF-8 or GBK. Note that using GBK encoding is not recommended because it may be unexpectly decoded as UTF-8.
jieba.cutandjieba.cut_for_searchreturns an generator, from which you can use aforloop to get the segmentation result (in unicode).jieba.lcutandjieba.lcut_for_searchreturns a list.jieba.Tokenizer(dictionary=DEFAULT_DICT)creates a new customized Tokenizer, which enables you to use different dictionaries at the same time.jieba.dtis the default Tokenizer, to which almost all global functions are mapped.
Code example: segmentation
Output:
- Add a custom dictionary
Load dictionary
- Developers can specify their own custom dictionary to be included in the jieba default dictionary. Jieba is able to identify new words, but you can add your own new words can ensure a higher accuracy.
- Usage:
jieba.load_userdict(file_name)# file_name is a file-like object or the path of the custom dictionary - The dictionary format is the same as that of
dict.txt: one word per line; each line is divided into three parts separated by a space: word, word frequency, POS tag. Iffile_nameis a path or a file opened in binary mode, the dictionary must be UTF-8 encoded. - The word frequency and POS tag can be omitted respectively. The word frequency will be filled with a suitable value if omitted.
For example:
-
Change a Tokenizer's
tmp_dirandcache_fileto specify the path of the cache file, for using on a restricted file system. -
Example:
Modify dictionary
-
Use
add_word(word, freq=None, tag=None)anddel_word(word)to modify the dictionary dynamically in programs. -
Use
suggest_freq(segment, tune=True)to adjust the frequency of a single word so that it can (or cannot) be segmented. -
Note that HMM may affect the final result.
Example:
- Keyword Extraction
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())sentence: the text to be extractedtopK: return how many keywords with the highest TF/IDF weights. The default value is 20withWeight: whether return TF/IDF weights with the keywords. The default value is FalseallowPOS: filter words with which POSs are included. Empty for no filtering.
jieba.analyse.TFIDF(idf_path=None)creates a new TFIDF instance,idf_pathspecifies IDF file path.
Example (keyword extraction)
https://github.com/fxsjy/jieba/blob/master/test/extract_tags.py
Developers can specify their own custom IDF corpus in jieba keyword extraction
- Usage:
jieba.analyse.set_idf_path(file_name) # file_name is the path for the custom corpus - Custom Corpus Sample:https://github.com/fxsjy/jieba/blob/master/extra_dict/idf.txt.big
- Sample Code:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_idfpath.py
Developers can specify their own custom stop words corpus in jieba keyword extraction
- Usage:
jieba.analyse.set_stop_words(file_name) # file_name is the path for the custom corpus - Custom Corpus Sample:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
- Sample Code:https://github.com/fxsjy/jieba/blob/master/test/extract_tags_stop_words.py
There's also a TextRank implementation available.
Use: jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
Note that it filters POS by default.
jieba.analyse.TextRank() creates a new TextRank instance.
- Part of Speech Tagging
jieba.posseg.POSTokenizer(tokenizer=None)creates a new customized Tokenizer.tokenizerspecifies the jieba.Tokenizer to internally use.jieba.posseg.dtis the default POSTokenizer.- Tags the POS of each word after segmentation, using labels compatible with ictclas.
- Example:
- Parallel Processing
-
Principle: Split target text by line, assign the lines into multiple Python processes, and then merge the results, which is considerably faster.
-
Based on the multiprocessing module of Python.
-
Usage:
jieba.enable_parallel(4)# Enable parallel processing. The parameter is the number of processes.jieba.disable_parallel()# Disable parallel processing.
-
Example: https://github.com/fxsjy/jieba/blob/master/test/parallel/test_file.py
-
Result: On a four-core 3.4GHz Linux machine, do accurate word segmentation on Complete Works of Jin Yong, and the speed reaches 1MB/s, which is 3.3 times faster than the single-process version.
-
Note that parallel processing supports only default tokenizers,
jieba.dtandjieba.posseg.dt.
- Tokenize: return words with position
- The input must be unicode
- Default mode
- Search mode
- ChineseAnalyzer for Whoosh
from jieba.analyse import ChineseAnalyzer- Example: https://github.com/fxsjy/jieba/blob/master/test/test_whoosh.py
- Command Line Interface
Initialization
By default, Jieba don't build the prefix dictionary unless it's necessary. This takes 1-3 seconds, after which it is not initialized again. If you want to initialize Jieba manually, you can call:
You can also specify the dictionary (not supported before version 0.28) :
Using Other Dictionaries
It is possible to use your own dictionary with Jieba, and there are also two dictionaries ready for download:
-
A smaller dictionary for a smaller memory footprint: https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.small
-
There is also a bigger dictionary that has better support for traditional Chinese (繁體):https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.big
By default, an in-between dictionary is used, called dict.txt and included in the distribution.
In either case, download the file you want, and then call jieba.set_dictionary('data/dict.txt.big') or just replace the existing dict.txt.
Segmentation speed
- 1.5 MB / Second in Full Mode
- 400 KB / Second in Default Mode
- Test Env: Intel(R) Core(TM) i7-2600 CPU @ 3.4GHz;《圍城》.txt