
Visualizing and Understanding Convolutional Networks 閱讀筆記-網路視覺化NO.1
Visualizing and Understanding Convolutional Networks 閱讀筆記
綜述:此篇paper是CNN視覺化的開山之作(由Lecun得意門生Matthew Zeiler發表於2013年),主要解決了兩個問題
1)why CNN perform so well?
2)how CNN might be improved?背景介紹:
1)近些年來,CNN針對影象分類問題有著令人驚歎的效果,2012年的AlexNet(test error:15.3%)碾壓第二名(test error:26.2%),由此CNN如雨後春筍般瘋狂生長,CNN之所以成功主要歸功於三個方面:①數以百萬計的帶標籤資料,②強大的GPU計算能力,③更好的正則化處理
2)提出問題:訓練出來的CNN模型為什麼能夠奏效?怎樣奏效?在科研方面,這些問題並沒有得到解決。論文介紹了CNN各層到底學到了原始影象的什麼特徵以及這些特徵對最終預測結果的影響力度- 實現(paper的展開以2013年的ZFNet=5層conv+3層FC 為基礎,在此基礎上進行了略微調整(such as:kernel size、stride),並提升了效果)
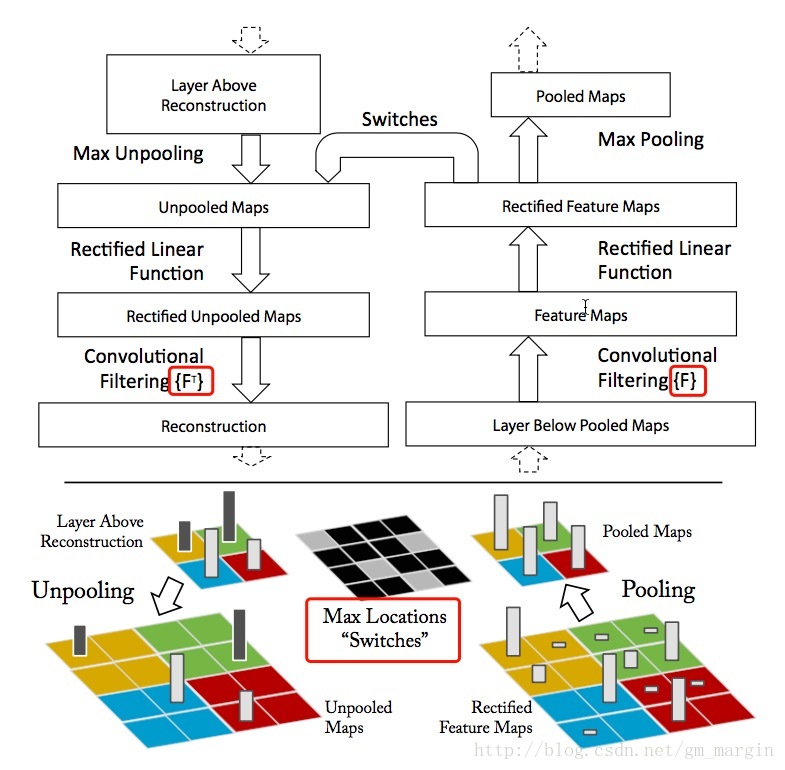
1)我們都知道ZFNet以conv+ReLU+Maxpooling為主要的實現方式,“看懂並理解”網路就是這個過程的逆過程,即Unpooling+ReLU+反捲積,下面我們分別進行介紹:
2)Unpooling:毫無疑問,maxpooling是一個不可逆過程,例如在一個3*3的pool中,我們選擇9個元素的最大值進而實現降取樣,我們必然會損失其他8個元素的真實資料。實現過程中,我們需要記錄pool中最大值的位置資訊,我們稱之為“Switches”表格,在unpooling過程中,我們將最大值直接放回該位置,將其他位置直接置0;
3)ReLU:在CNN中,我們使用ReLU作為啟用函式是為了修正feature map,使其恆不為負,為了重構每一層的輸出,這種約束依然成立,我們繼續使用ReLU;
4)反捲積:CNN中,上層的輸出與學習到的filters進行卷積,得到本層的特徵,逆過程的實現就是通過使用相同卷積核的轉置,與矯正之後的特徵進行卷積,從而實現反捲積。這時候便產生了疑問?為什麼使相同卷積核的轉置?下面將進行粗淺說明:
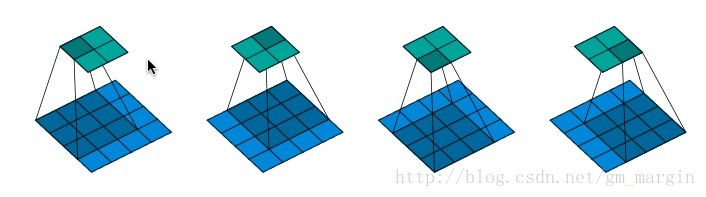
注:假設在某次的卷積過程如圖所示,feature map size=4*4,padding=0,strides=1,則會產生2*2的feature map
1.將輸入矩陣(藍色)展開為16維向量,記作x
2.將輸出矩陣(綠色)可展開為4維向量,記作y
3.由1,2可知,卷積運算可表示為y = Cx,正向傳播時接收16維,輸出4維;反向傳播時接收4維,輸出16維,正向傳播與反向傳播可類比於卷積與逆卷積運算,其中的C為:
注:其中的 代表卷積核的中的元素,推導過程如下:
具體實現過程如圖所示:
注:Max Locations “Switches”在maxpooling過程中儲存了最大值得座標資訊,反捲積的卷積核使用的是相同卷積核的轉置 - 訓練細節
1)dataset:模型使用的資料集是ImageNet 2012 training set (130萬張照片, 1000個種類),每張照片都從中間擷取256*256大小的圖片,而後減去所有訓練圖片畫素的均值,每張圖片使用10個不同的field,可以通過水平翻轉+移動方式獲得
2)training:初始學習率0.01,使用SGD學習方式,minibatch為128,momentum動量為0.9,當validation error平穩時對learning rate進行調節,在fc層我們使用dropout(rate為0.5) - 網路視覺化
1)網路每層的視覺化結果展示了網路層次化的特點,較低的網路層級學到的特徵較為明顯,一般表現為顏色、形狀、紋理,隨著網路層級的加深,網路學到的特徵越抽象。同時,較低的網路層級收斂速度較快,但對輸入影象的敏感性很高;較高層級收斂速度較慢,但對輸入影象的魯棒性較高。
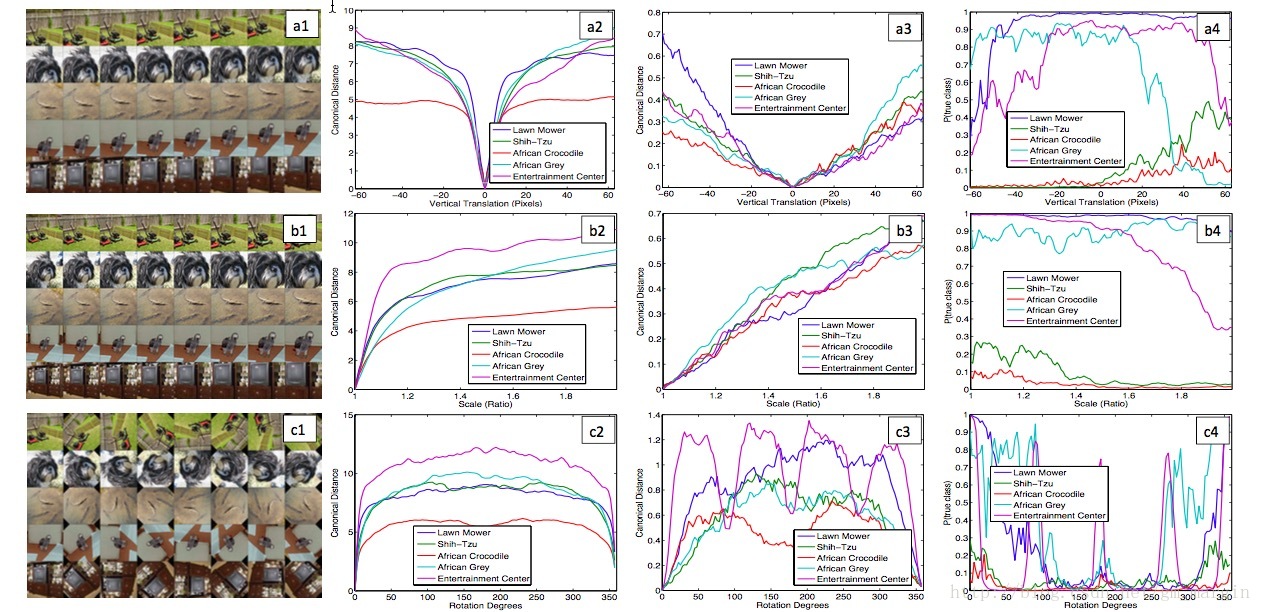
2)CNN模型對影象的平移、縮放具有較強的魯棒性,但影象的旋轉操作會對CNN的feature map影響較大。效果如下圖所示:
注:a1,b1,c1分別是對原始影象進行垂直移動、放大、旋轉等操作;a2,b2,c2和a3,b3,c3分別是對應變化與原始影象在layer1和layer7中feature的歐幾里得距離;a4,b4,c4分別是預測正確的概率(其中有兩個class預測正確的概率超級低,不知道為什麼。。。不過目前的這個結果已經足夠有意思了,哈哈哈) - 部分影象遮擋對分類結果的影響
實驗證明,當對影象的關鍵位置進行遮擋時,影象預測正確的概率將大大降低
論文中還做了一個實驗,很有意思,如下圖所示:
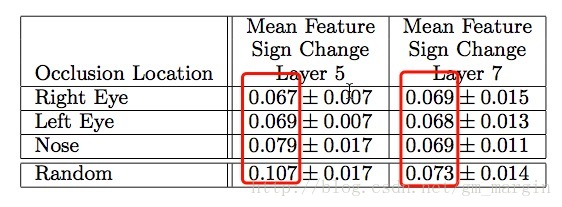
注:圖片展示了對原始影象進行不同部位的遮擋,第1列為原始影象,第2,3,4分別是對狗的左眼、右眼、鼻子進行遮擋,其他列則是隨機進行遮擋,layer5和layer7的
注:layer5關注區域性特徵,而layer7則關注類別特徵(原文:Measure of correspondence for dierent object parts in 5 different dog images. The lower scores for the eyes and nose (compared to random object parts) show the model implicitly establishing some form of correspondence of parts at layer 5 in the model. At layer 7, the scores are more similar, perhaps due to upper layers trying to discriminate between the different breeds of dog.) 之後論文詳細闡述瞭如何重構Alexnet、做出的哪些微調以及最終的效果,此處不再贅述
Summary:論文通過conv+ReLU+maxpooling的逆過程視覺化CNN,並通過觀察重構結果調整網路結構,提高了模型精確度。是網路視覺化的開山經典之作,而後還有幾篇視覺化的經典之作,如下:
1)《Visualizing and Understanding Convolutional Networks》–就是此篇開創了視覺化的先河
2)《Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps》
3)《Learning Deep Features for Discriminative Localization》
4)《Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization》
有時間的話,再和大家一起分享



*作者:gengmiao 時間:2018.02.18,原創文章,轉載請保留原文地址、作者等資訊*