
Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks閱讀筆記
1.摘要
論文提出一種統一的網路結構模型,這種模型可以直接通過一次前向計算就可以同時實現對影象中文字定位和識別的任務。這種網路結構可以直接以end-to-end的方式訓練,訓練的時候只需要輸入影象,影象中文字的bbox,以及文字對應的標籤資訊。這種end-to-end訓練的模型,可以學習到更加豐富的特徵資訊。而且,這種模型所需要的時間更少,因為在文字檢測和識別的時候,只需要計算一次影象的特徵,這種特徵是同時別文字檢測和識別所共享的。
2.相關工作介紹
將檢測和識別統一到一個模型裡面,進行end-to-end訓練的優點:
a.由於檢測和識別是高度相關的,因此將檢測和識別統一到一個模型裡面,就使得影象的feature可以被共享利用。
b.檢測和識別這兩種任務可以是互補的,更好的檢測結果可以提升識別的準確率,識別的資訊也可以被用來精修檢測的結果。
論文的主要貢獻有三個:
a.end-to-end方式訓練出來的模型可以學習到更豐富的影象特徵,並且這種特徵可以被兩種不同任務所共享,可以有效的節省時間。
b.論文中提出了一種全新的region feature抽取方法。這種feature抽取方法可以很好的相容文字bbox原始長寬比以及避免影象的扭曲,而且ROI pooling可以生成具有不同長度的feature maps。
c.提出了一種類似課程學習策略的方法用一種逐漸增加影象複雜性的資料集來訓練模型。
3.模型中各個模組介紹

模型整體框架介紹:首先用修改後的VGG16網路對影象進行特徵提取,用TPN對提取的CNN特徵進行region proposals的生成。然後用由LSTM組成的RFE將region proposals編碼成固定長度的表徵序列。將fixed-length的representation輸入到TDN,計算每個region proposals屬於文字區域的置信度與座標偏移量.然後RFE再計算TDN所提供的bboxes內的fixed-length representation.最後TRN基於檢測到的bbox的representation來識別單詞。
3.1 TPN

這種結構是由faster rcnn中的RPN接面構改進得到。為了適應文字區域的不同程度的長寬比以及尺度的不同,TPN接面構採用了相比於RPN更多的anchors(24個),包括4種尺度(16^2,32^2,64^2,80^2),6種長寬比(1:1,2:1,3:1,5:1,7:1,10:1).同時使用了兩種256維的卷積核(5x3,3x1),分別抽取feature maps中區域性和上下文的資訊.這種長方形的filters更加適用於本身具有不同長寬比的單詞bbox.
3.2 RFE
 首先利用尺寸為h×w的ROI pooling操作將region proposals池化成H×min(W_max,2Hw/h)大小。最後獲得包含有任意寬度的feature maps Q∈R^(C×H×W)。將這些feature maps按列進行轉換成序列(q_1,q_2,…,q_W)。然後將這些序列輸入到LSTM中進行編碼,取LSTM最後一個時間步的隱層輸出h_W作為fixed-length representation。
首先利用尺寸為h×w的ROI pooling操作將region proposals池化成H×min(W_max,2Hw/h)大小。最後獲得包含有任意寬度的feature maps Q∈R^(C×H×W)。將這些feature maps按列進行轉換成序列(q_1,q_2,…,q_W)。然後將這些序列輸入到LSTM中進行編碼,取LSTM最後一個時間步的隱層輸出h_W作為fixed-length representation。
3.3 TDN
將編碼向量輸入到兩個並行的網路層——分別用於分類和bbox迴歸。整個bbox位置的精修分成兩個部分:TPN和TDN。
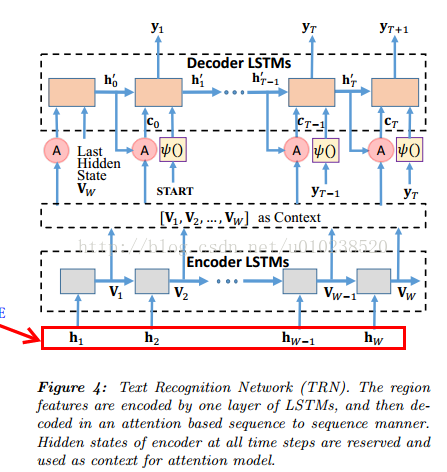
TRN主要用來預測檢測視窗中的文字資訊,通過使用注意力機制來將抽取的feature解碼成單詞。將來自RFE的隱層輸出輸入到具有1024個神經元的LSTM編碼器,得到每個時間步隱層的輸出作為抽取的region features V=[v_1,v_2,…,v_W]。在訓練的時候,將每個文字bbox的單詞label作為LSTM每個時間步的輸入,詞序列為s={s_0,s_1,…,s_(T+1)}。
將x_0,x_1,…,x_(T+1)作為解碼LSTM的輸入,其中x_0=[v_W;Atten(V,0)],x_i=[φ(s_(i-1));Atten(V,h_(i-1)^')],φ()表示將詞向量進行變換的嵌入操作。c_i=Atten(V,h_(i-1)^')的定義如下:
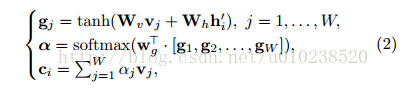
整個解碼LSTM的隱層計算和輸出計算如下:
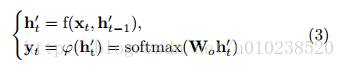
4. 多工損失函式
整個網路包含了分類和檢測兩個部分,所以在訓練的時候,整個模型所使用的損失函式為一個多工損失函式,定義如下,前兩個部分主要用來訓練TDN部分,最後一個部分用來TRN識別分類部分。
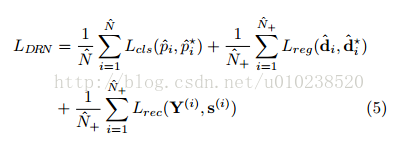
5. 網路訓練
a. 先將TRN部分固定,用合成的資料來訓練網路的其他部分,其中卷積部分用VGG16網路來進行初始化,剩餘網路部分採用高斯隨機初始化,其中前四個卷積層學習率設定為10^-5,其餘的網路層設定為10^-3.訓練迭代30k次。
b. 將TRN部分加入訓練,並將此部分的學習率設定為10^-3,之前用隨機初始化的網路部分的學習率降低為原來的一半,訓練時使用的資料與步驟a中一樣。訓練迭代30k次。
c. 合成新的資料集,將文字資訊隨機加入到真實場景中。用這些新合成的資料集訓練整個模型,其中卷積部分學習率設定為10^-5,其餘網路層設定為10^-4。訓練迭代50k次。
d. 用真實的資料來訓練模型。在訓練的過程中,卷積層固定不再發生變化,其餘部分的學習率設定為10^-5,訓練迭代20k次。
參考文獻
1.Li H, Wang P, Shen C. Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks[J]. 2017.
2.Girshick R. Fast R-CNN[J]. Computer Science, 2015.
3.Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137.
相關推薦
Towards End-to-end Text Spotting with Convolutional Recurrent Neural Networks閱讀筆記
1.摘要 論文提出一種統一的網路結構模型,這種模型可以直接通過一次前向計算就可以同時實現對影象中文字定位和識別的任務。這種網路結構可以直接以end-to-end的方式訓練,訓練的時候只需要輸入影象,影象中文字的bbox,以及文字對應的標籤資訊。這種end-to-end訓練的
Flower classification using deep convolutional neural networks 閱讀筆記
** Flower classification using deep convolutional neural networks ** 本部落格主要是對該篇論文做一個閱讀筆記 ,用FCN+CNN去做識別 期刊: IET Computer Vision 內容: (1)自動分割
DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks
step with 圖片 eight enter sub img layer each 1、Introduction DL解決VO問題:End-to-End VO with RCNN 2、Network structure a.CNN based Feature Ext
【USE】《An End-to-End System for Automatic Urinary Particle Recognition with CNN》
Urine Sediment Examination(USE) JMOS-2018 目錄 目錄 1 Background and Motivation 2 Innovation
FlowTrack-End-to-end Flow Correlation Tracking with Spatial-temporal Attention(CVPR2018)
動機:大多數DCF方法僅考慮當前幀的特徵,而很少受益於運動和幀間資訊。發生遮擋和形變時,時間資訊缺失導致效能減低。 本文提出FlowTrack,利用連續幀中豐富的光流資訊來改善特徵表示和跟蹤精度。具體是將光流估計,特徵提取,聚合和相關濾波器跟蹤制定為網路中的特殊層,從而實現端到端學習。這種在深度
CBHG 模組 來自TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS
作者的靈感來源於在文章Fully Character-Level Neural Machine Translation without Explicit Segmentation中的模型。原型如下圖所示: CBHG模組如下圖所示。首次提出在Goggle的一篇文章:TACO
深度學習論文翻譯解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
論文標題:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition 論文作者: Baoguang Shi, Xiang B
A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classificatio
abstract 文字摘要和情感分類都是要捕獲文字的重要資訊,但是在不同的水平上的。文字摘要是用一些句子表示原始文件,情感分類是給文字貼標籤。 提出層次級的端到端模型進行摘要抽取和情感分類的聯合學習,標籤是作為文字摘要抽取的輸出,情感分類依賴於摘要抽取, 情感分類放在摘要
「Medical Image Analysis」Note on End-to-end DP with CNN (EDPCNN)
QQ Group: 428014259 Sina Weibo:小鋒子Shawn Tencent E-mail:[email protected] http://blog.csdn.net/dgyuanshaofeng/article/details/84843126 [1]
The Problem with End-to-End Tests – gitconnected
The Problem with End-to-End TestsSalt is great. According to Wikipedia, salt is essential for life in general, and saltiness is one of the basic human tast
An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
01 Mar 2018 Piotr Nowojski (@PiotrNowojski) & Mike Winters (@wints) This post is an adaptation of Piotr Nowojski’s presentation from Flink Forward Ber
論文筆記|Towards End-to-End Lane Detection: an Instance Segmentation
用盡量少的語言描述一篇paper 本文看點: 結合embedding和Segmentation mask提供一種做Lane Instance Segmentation的思路 Lane的Instance Segmentation可以比單純的Segmentati
論文筆記(1)DenseBox: Unifying Landmark Localization with End to End Object Detection
本文的貢獻有一下幾點: 1,實現了end-to-end的學習,同時完成了對bounding box和物體類別的預測; 2,在多工學習中融入定位資訊,提高了檢測的準確率。 我們先來看看他和其他幾篇代表性文章之間的不同。 在OverFeat[1]中提出了將分
【論文筆記】An End-to-End Model for QA over KBs with Cross-Attention Combining Global Knowledge
一、概要 該文章發於ACL 2017,在Knowledge base-based question answering (KB-QA)上,作者針對於前人工作中存在沒有充分考慮候選答案的相關資訊來訓練question representation的問題,提出
Overview:end-to-end深度學習網絡在超分辨領域的應用(待續)
向量 不同的 這就是 src dimens sep max pos pca 目錄 1. SRCNN Contribution Inspiration Network O. Pre-processing I. Patch extraction and representat
端到端的學習end-to-end learning (理解)
傳統的機器學習的流程是由多個獨立的模組組成,每一個獨立的任務其結果的好壞都會影響到下一個步驟,從而影響到整個訓練的結果,這個是非端到端的 而深度學習模型在訓練過程中,從輸入端(輸入資料)到輸出端會得到一個預測結果,與真實結果相比較會得到一個誤差,這個誤差會在模型中的每一層傳遞(反向傳播),每一層
目標檢測中對端對端(End to end)的理解
End to end:指的是輸入原始資料,輸出的是最後結果,應用在特徵學習融入演算法,無需單獨處理。 end-to-end(端對端)的方法,一端輸入我的原始資料,一端輸出我想得到的結果。只關心輸入和輸出,中間的步驟全部都不管。 端到端指的是輸入是原始資料,輸出是最後的結果,原來輸入端不是
Direct Shape Regression Networks for End-to-End Face Alignment
端到端人臉對齊的直接形狀迴歸網路1 主要的挑戰在於人臉影象和相關的面部形狀之間的高度非線性關係,這種非線性關係是基於標記的相關性耦合。現有的方法主要依賴於級聯迴歸,存在固有的缺點,例如對初始化的強依賴性和未能利用相關的標記。 本文提出了一種**直接形狀迴歸網路(direct shap
《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its...》論文閱讀之CRNN
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition paper: CRNN 翻譯:CRNN
《End-to-End Learning of Motion Representation for Video Understanding》論文閱讀
CVPR 2018 | 騰訊AI Lab、MIT等機構提出TVNet:可端到端學習視訊的運動表徵 動機 儘管端到端的特徵學習已經取得了重要的進展,但是人工設計的光流特徵仍然被廣泛用於各類視訊分析任務中。為了彌補這個不足而提出; 以前的方法: