
特徵選擇方法學習筆記(一)
阿新 • • 發佈:2019-01-04
今天開始會持續學習一些state-of-art的特徵選擇方法,跟大家分享一下學習的心得和這些方法的主要思想,希望能對同志們的工作有所啟發。
首先我們看的是一篇2005年發表在PAMI(IEEE Transactions on Pattern Analysis and Machine Intelligence)上的文章《Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy》。之所以先看這篇是因為在實驗中我首先跟這篇文章中的方法做的比較,發現這個裡面提到的mRMR方法魯棒性較好,在各個資料集上的分類準確率排名都能保持在前列,同時計算時間也較短。這也是我自己的方法首先挑戰的物件。
這篇文章中提出的方法叫“最小冗餘最大相關度標準”(mRMR),按照特徵選擇方法的大類來看應該算是filter的方法。該類方法有個明顯的優勢就是速度快,但是往往容易忽略特徵間的相互影響。文中提出的mRMR方法在一定程度上減小了這種忽略。文章首先用mRMR的方法進行特徵選擇初步的過濾選出最有表示力的候選特徵,然後再結合其他複雜的如wrapper類的方法進行特徵選擇。這樣既可以保證速度又能夠提高準確率。文章也從理論上證明了最大相關度和最小冗餘方法選取特徵是有效、高效的(對證明感興趣的同志們請參看論文,在此我們就品嚐一下這個方法的主要思想)。
一種最常用的特徵選擇方法是最大化特徵和目標之間的相關度。也就是說選擇核目標最相關的特徵。但是單純的對單個好特徵的組合未必能達到很好的分類效能。很多文章都指出“the m best features are not the best m features”。大家可以好好理解一下這句好。為什麼這麼說呢?如果這些好的單個特徵都是相關的(冗餘)那麼他們的組合就有可能比雖然單個不是和目標最相關但是特徵相互之間是不相關的(近似正交)特徵組合起來分類效果差。只是尋找單個表現比較好的特徵來進行組合也是以往filter類演算法的通病。這種情況下選出來的特徵往往會導致在特別低維的時候效果較好,但是當維數增高時效果就不如別的方法了(低維的時候效果好也沒用,因為一般情況下在低維的時候效果再好也比高維時候效果差的精度要低)。本文就是基於這個觀點出發,來構造了一種方法, 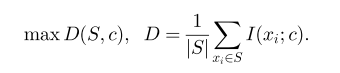
這個公式是用來衡量相似度大小的。
這個公式是用來衡量冗餘度大小的。 然後將這兩個公式統一到一個目標函式中: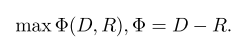
即
然後解這個目標函式的最優化問題,求得能使其最大的特徵子集就行了。 好了,最後總結一下這個方法,思想就是不光考慮單個特徵還考慮了特徵間的相互聯絡。就像我們考慮區域性情況的同時要考慮全域性的情況。在團隊中,個人不能為了貪圖自己的利益最大化而損害了整個團隊的利益,這樣到頭來團隊沒了自己的利益也就徹底沒了。想一想,科學中的道理和日常生活中很多道理都是通的,歸根到底大家都是由哲學衍生的嘛,大家做研究時不妨嘗試將這些道理融入進來,沒準一個新的成果就出來了。
這個公式是用來衡量相似度大小的。
這個公式是用來衡量冗餘度大小的。 然後將這兩個公式統一到一個目標函式中:
即
然後解這個目標函式的最優化問題,求得能使其最大的特徵子集就行了。 好了,最後總結一下這個方法,思想就是不光考慮單個特徵還考慮了特徵間的相互聯絡。就像我們考慮區域性情況的同時要考慮全域性的情況。在團隊中,個人不能為了貪圖自己的利益最大化而損害了整個團隊的利益,這樣到頭來團隊沒了自己的利益也就徹底沒了。想一想,科學中的道理和日常生活中很多道理都是通的,歸根到底大家都是由哲學衍生的嘛,大家做研究時不妨嘗試將這些道理融入進來,沒準一個新的成果就出來了。