
詞嵌入向量(Word Embedding)的原理和生成方法
Word Embedding
詞嵌入向量(WordEmbedding)是NLP裡面一個重要的概念,我們可以利用Word Embedding將一個單詞轉換成固定長度的向量表示,從而便於進行數學處理。本文將介紹Word Embedding的使用方式,並講解如何通過神經網路生成Word Embedding。
Word Embedding的使用
使用數學模型處理文字語料的第一步就是把文字轉換成數學表示,有兩種方法,第一種方法可以通過one-hot矩陣表示一個單詞,one-hot矩陣是指每一行有且只有一個元素為1,其他元素都是0的矩陣。針對字典中的每個單詞,我們分配一個編號,對某句話進行編碼時,將裡面的每個單詞轉換成字典裡面這個單詞編號對應的位置為1的one-hot矩陣就可以了。比如我們要表達“the cat sat on the mat”,可以使用如下的矩陣表示。
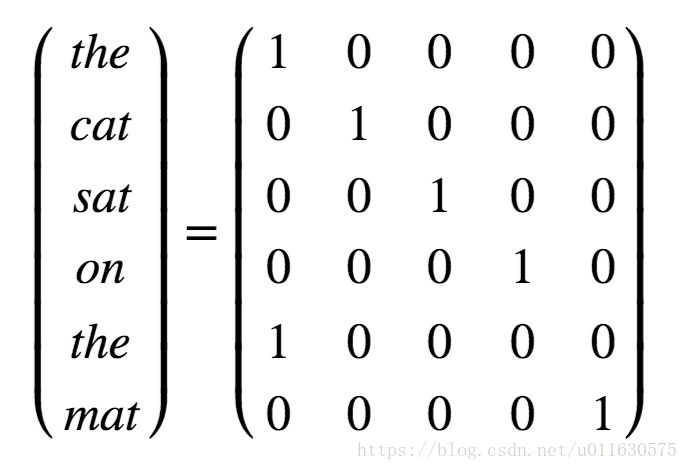
one-hot矩陣表示法
one-hot表示方式很直觀,但是有兩個缺點,第一,矩陣的每一維長度都是字典的長度,比如字典包含10000個單詞,那麼每個單詞對應的one-hot向量就是1X10000的向量,而這個向量只有一個位置為1,其餘都是0,浪費空間,不利於計算。第二,one-hot矩陣相當於簡單的給每個單詞編了個號,但是單詞和單詞之間的關係則完全體現不出來。比如“cat”和“mouse”的關聯性要高於“cat”和“cellphone”,這種關係在one-hot表示法中就沒有體現出來。
Word Embedding解決了這兩個問題。Word Embedding矩陣給每個單詞分配一個固定長度的向量表示,這個長度可以自行設定,比如300,實際上會遠遠小於字典長度(比如10000)
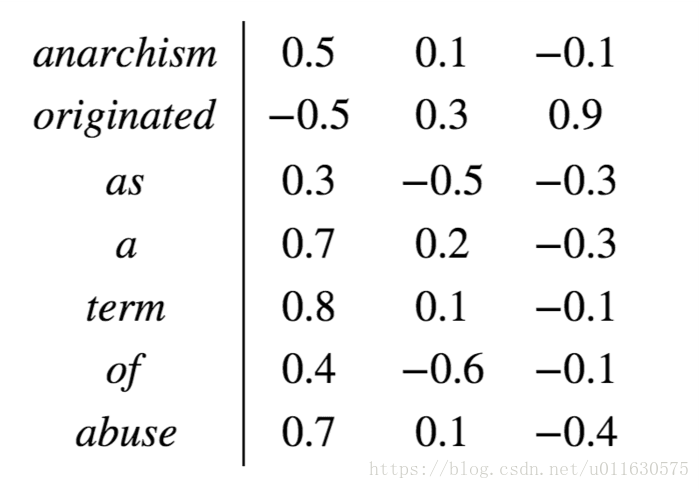
Word Embedding表示法
通過簡單的餘弦函式,我們就可以計算兩個單詞之間的相關性,簡單高效:
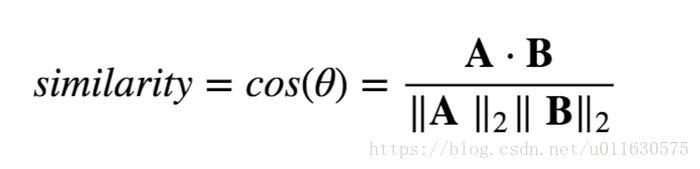
兩個向量相關性計算
因為Word Embedding節省空間和便於計算的特點,使得它廣泛應用於NLP領域。接下來我們講解如何通過神經網路生成Word Embedding。
Word Embedding的生成
Word Embedding的生成我們使用tensorflow,通過構造一個包含了一個隱藏層的神經網路實現。
下面是下載資料和載入資料的程式碼,一看就懂。訓練資料我們使用的是http://mattmahoney.net/dc/enwik8.zip資料,裡面是維基百科的資料。
接下來是如何構建訓練資料。構建訓練資料主要包括統計詞頻,生成字典檔案,並且根據字典檔案給訓練源資料中的單詞進行編號等工作。我們生成的字典不可能包含所有的單詞,一般我們按照單詞頻率由高到低排序,選擇覆蓋率大於95%的單詞加入詞典就可以了,因為詞典越大,覆蓋的場景越大,同時計算開銷越大,這是一個均衡。下面的程式碼展示了這個過程,首先統計所有輸入語料的詞頻,選出頻率最高的10000個單詞加入字典。同時在字典第一個位置插入一項“UNK"代表不能識別的單詞,也就是未出現在字典的單詞統一用UNK表示。然後給字典裡每個詞編號,並把源句子裡每個詞表示成在字典中的編號。我們可以根據每個詞的編號查詢Word Embedding中的向量表示。
接下來我們看一下如何將源句子轉換成訓練過程的輸入和輸出,這一步是比較關鍵的。有兩種業界常用的Word Embedding生成方式,Continuous Bag Of Words (CBOW)方法和n-gram方法,我們採用n-gram方法。訓練的目的是獲得能夠反映任意兩個單詞之間關係的單詞向量表示,所以我們的輸入到輸出的對映也要翻譯兩個單詞之間的關聯。n-gram的思路是將所有的源句子按固定長度(比如128個單詞)分割成很多batch。對於每個batch,從前往後每次選取長度為skip_window的視窗(我們設定skip_window=5)。對於視窗中的5個單詞,我們生成兩個source-target資料對,這兩個source-target對的source都是視窗中間的單詞,也就是第三個單詞,然後從另外四個單詞中隨機選取兩個作為兩個target單詞。然後視窗向後移動一個單詞,每次向後移動一個位置獲取下5個單詞,一共迴圈64次,獲取到64X2=128個source-target對,作為一個batch的訓練資料。總的思路就是把某個單詞和附近的單片語對,作為輸入和輸出。這裡同一個source單詞,會被對映到不同的target單詞,這樣理論上可以獲取任意兩個單詞之間的關係。
比如對於句子"cat and dog play balls on the floor",第一個視窗就是“cat and dog play balls",生成的兩個source-target對可能是下面中的任意兩個:dog -> cat dog -> and dog -> balls dog -> play
第二個視窗是"and dog play balls on",生成的兩個source-target對可能是下面中的任意兩個:play -> andplay -> ballsplay -> dogplay -> on
接下來是構建神經網路的過程,我們構建了一個包含一個隱藏層的神經網路,該隱藏層包含300個節點,這個數量和我們要構造的WordEmbedding維度一致。
我們首先隨機初始化embeddings矩陣,通過tf.nn.embedding_lookup函式將輸入序列轉換成Word Embedding表示作為隱藏層的輸入。初始化weights和biases,計算隱藏層的輸出。然後計算輸出和target結果的交叉熵,使用GradientDescentOptimizer完成一次反向傳遞,更新可訓練的引數,包括embeddings變數。在Validate過程中,對測試資料集中的單詞,利用embeddings矩陣計算測試單詞和所有其他單詞的相似度,輸出相似度最高的幾個單詞,看看它們相關性如何,作為一種驗證方式。
通過這個神經網路,就可以完成WordEmbedding的訓練,繼而應用於其他NLP的任務。