
四大卷積網路發家之路
>
AlexNet
VGGNet
Google Inception Net
ResNet
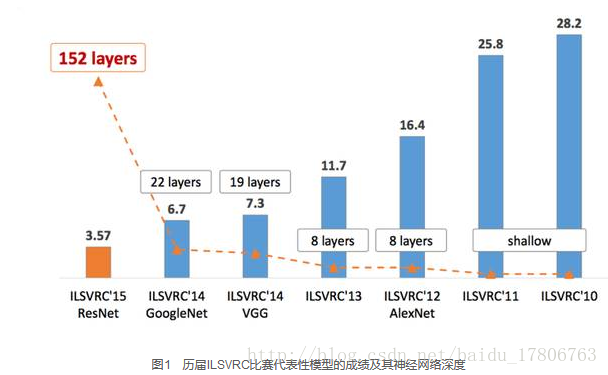
這4種網路依照出現的先後順序排列,深度和複雜度也依次遞進。它們分別獲得了ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比賽分類專案的2012年冠軍(top-5錯誤率16.4%,使用額外資料可達到15.3%,8層神經網路)、2014年亞軍(top-5錯誤率7.3%,19層神經網路),2014年冠軍(top-5錯誤率6.7%,22層神經網路)和2015年的冠軍(top-5錯誤率3.57%,152層神經網路)。
這4個經典的網路都在各自的年代率先使用了很多先進的卷積神經網路結構,對卷積網路乃至深度學習有非常大的推動作用,也象徵了卷積神經網路在2012—2015這四年間的快速發展。如圖1所示,ILSVRC的top-5錯誤率在最近幾年取得重大突破,而主要的突破點都是在深度學習和卷積神經網路,成績的大幅提升幾乎都伴隨著卷積神經網路的層數加深。
而傳統機器學習演算法目前在ILSVRC上已經難以追上深度學習的步伐了,以至於逐漸被稱為淺層學習(Shallow Learning)。目前在ImageNet資料集上人眼能達到的錯誤率大概在5.1%,這還是經過了大量訓練的專家能達到的成績,一般人要區分1000種類型的圖片是比較困難的。而ILSVRC 2015年冠軍——152層ResNet的成績達到錯誤率3.57%,已經超過了人眼,這說明卷積神經網路已經基本解決了ImageNet資料集上的圖片分類問題。
前面提到的計算機視覺比賽ILSVRC使用的資料都來自ImageNet,如圖2所示。ImageNet專案於2007年由斯坦福大學華人教授李飛飛創辦,目標是收集大量帶有標註資訊的圖片資料供計算機視覺模型訓練。ImageNet擁有1500萬張標註過的高清圖片,總共擁有22000類,其中約有100萬張標註了圖片中主要物體的定位邊框。ImageNet專案最早的靈感來自於人類通過視覺學習世界的方式,如果假定兒童的眼睛是生物照相機,他們平均每200ms就拍照一次(眼球轉動一次的平均時間),那麼3歲大時孩子就已經看過了上億張真實世界的照片,可以算得上是一個非常大的資料集。ImageNet專案下載了網際網路上近10億張圖片,使用亞馬遜的土耳其機器人平臺實現眾包的標註過程,有來自世界上167個國家的近5萬名工作者幫忙一起篩選、標註。

每年度的ILSVRC比賽資料集中大概擁有120萬張圖片,以及1000類的標註,是ImageNet全部資料的一個子集。比賽一般採用top-5和top-1分類錯誤率作為模型效能的評測指標,圖3所示為AlexNet識別ILSVRC資料集中圖片的情況,每張圖片下面是分類預測得分最高的5個分類及其分值。

AlexNet
2012年,Hinton的學生Alex Krizhevsky提出了深度卷積神經網路模型AlexNet,它可以算是LeNet的一種更深更寬的版本。AlexNet中包含了幾個比較新的技術點,也首次在CNN中成功應用了ReLU、Dropout和LRN等Trick。同時AlexNet也使用了GPU進行運算加速,作者開源了他們在GPU上訓練卷積神經網路的CUDA程式碼。AlexNet包含了6億3000萬個連線,6000萬個引數和65萬個神經元,擁有5個卷積層,其中3個卷積層後面連線了最大池化層,最後還有3個全連線層。AlexNet以顯著的優勢贏得了競爭激烈的ILSVRC 2012比賽,top-5的錯誤率降低至了16.4%,相比第二名的成績26.2%錯誤率有了巨大的提升。AlexNet可以說是神經網路在低谷期後的第一次發聲,確立了深度學習(深度卷積網路)在計算機視覺的統治地位,同時也推動了深度學習在語音識別、自然語言處理、強化學習等領域的拓展。
AlexNet將LeNet的思想發揚光大,把CNN的基本原理應用到了很深很寬的網路中。AlexNet主要使用到的新技術點如下。
(1)成功使用ReLU作為CNN的啟用函式,並驗證其效果在較深的網路超過了Sigmoid,成功解決了Sigmoid在網路較深時的梯度彌散問題。雖然ReLU啟用函式在很久之前就被提出了,但是直到AlexNet的出現才將其發揚光大。
(2)訓練時使用Dropout隨機忽略一部分神經元,以避免模型過擬合。Dropout雖有單獨的論文論述,但是AlexNet將其實用化,通過實踐證實了它的效果。在AlexNet中主要是最後幾個全連線層使用了Dropout。
(3)在CNN中使用重疊的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。並且AlexNet中提出讓步長比池化核的尺寸小,這樣池化層的輸出之間會有重疊和覆蓋,提升了特徵的豐富性。
(4)提出了LRN層,對區域性神經元的活動建立競爭機制,使得其中響應比較大的值變得相對更大,並抑制其他反饋較小的神經元,增強了模型的泛化能力。
(5)使用CUDA加速深度卷積網路的訓練,利用GPU強大的平行計算能力,處理神經網路訓練時大量的矩陣運算。AlexNet使用了兩塊GTX 580 GPU進行訓練,單個GTX 580只有3GB視訊記憶體,這限制了可訓練的網路的最大規模。因此作者將AlexNet分佈在兩個GPU上,在每個GPU的視訊記憶體中儲存一半的神經元的引數。因為GPU之間通訊方便,可以互相訪問視訊記憶體,而不需要通過主機記憶體,所以同時使用多塊GPU也是非常高效的。同時,AlexNet的設計讓GPU之間的通訊只在網路的某些層進行,控制了通訊的效能損耗。
(6)資料增強,隨機地從256´256的原始影象中擷取224´224大小的區域(以及水平翻轉的映象),相當於增加了(256-224)2´2=2048倍的資料量。如果沒有資料增強,僅靠原始的資料量,引數眾多的CNN會陷入過擬閤中,使用了資料增強後可以大大減輕過擬合,提升泛化能力。進行預測時,則是取圖片的四個角加中間共5個位置,並進行左右翻轉,一共獲得10張圖片,對他們進行預測並對10次結果求均值。同時,AlexNet論文中提到了會對影象的RGB資料進行PCA處理,並對主成分做一個標準差為0.1的高斯擾動,增加一些噪聲,這個Trick可以讓錯誤率再下降1%。
整個AlexNet有8個需要訓練引數的層(不包括池化層和LRN層),前5層為卷積層,後3層為全連線層,如圖4所示。AlexNet最後一層是有1000類輸出的Softmax層用作分類。 LRN層出現在第1個及第2個卷積層後,而最大池化層出現在兩個LRN層及最後一個卷積層後。ReLU啟用函式則應用在這8層每一層的後面。因為AlexNet訓練時使用了兩塊GPU,因此這個結構圖中不少元件都被拆為了兩部分。現在我們GPU的視訊記憶體可以放下全部模型引數,因此只考慮一塊GPU的情況即可。
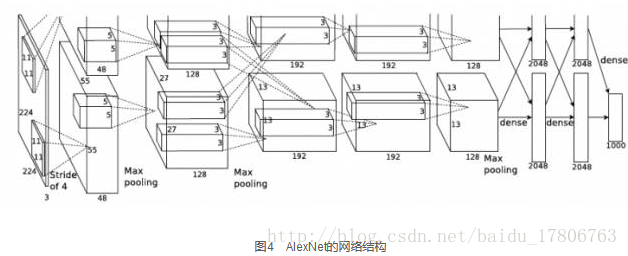
AlexNet每層的超引數如圖5所示。其中輸入的圖片尺寸為224´224,第一個卷積層使用了較大的卷積核尺寸11´11,步長為4,有96個卷積核;緊接著一個LRN層;然後是一個3´3的最大池化層,步長為2。這之後的卷積核尺寸都比較小,都是5´5或者3´3的大小,並且步長都為1,即會掃描全圖所有畫素;而最大池化層依然保持為3´3,並且步長為2。我們可以發現一個比較有意思的現象,在前幾個卷積層,雖然計算量很大,但引數量很小,都在1M左右甚至更小,只佔AlexNet總引數量的很小一部分。這就是卷積層有用的地方,可以通過較小的引數量提取有效的特徵。而如果前幾層直接使用全連線層,那麼引數量和計算量將成為天文數字。雖然每一個卷積層佔整個網路的引數量的1%都不到,但是如果去掉任何一個卷積層,都會使網路的分類效能大幅地下降。

VGGNet
VGGNet是牛津大學計算機視覺組(Visual Geometry Group)和Google DeepMind公司的研究員一起研發的的深度卷積神經網路。VGGNet探索了卷積神經網路的深度與其效能之間的關係,通過反覆堆疊3´3的小型卷積核和2´2的最大池化層,VGGNet成功地構築了16~19層深的卷積神經網路。VGGNet相比之前state-of-the-art的網路結構,錯誤率大幅下降,並取得了ILSVRC 2014比賽分類專案的第2名和定位專案的第1名。同時VGGNet的拓展性很強,遷移到其他圖片資料上的泛化性非常好。VGGNet的結構非常簡潔,整個網路都使用了同樣大小的卷積核尺寸(3´3)和最大池化尺寸(2´2)。到目前為止,VGGNet依然經常被用來提取影象特徵。VGGNet訓練後的模型引數在其官方網站上開源了,可用來在domain specific的影象分類任務上進行再訓練(相當於提供了非常好的初始化權重),因此被用在了很多地方。
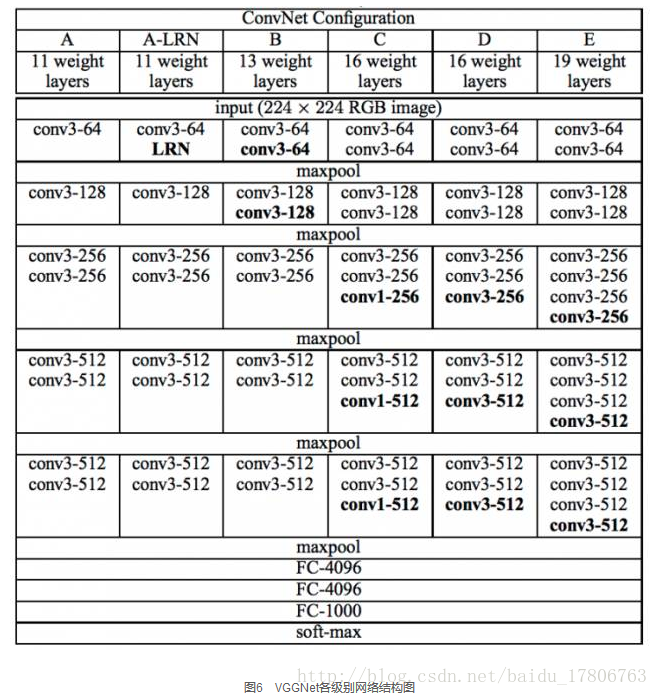
VGGNet論文中全部使用了3´3的卷積核和2´2的池化核,通過不斷加深網路結構來提升效能。圖6所示為VGGNet各級別的網路結構圖,圖7所示為每一級別的引數量,從11層的網路一直到19層的網路都有詳盡的效能測試。雖然從A到E每一級網路逐漸變深,但是網路的引數量並沒有增長很多,這是因為引數量主要都消耗在最後3個全連線層。前面的卷積部分雖然很深,但是消耗的引數量不大,不過訓練比較耗時的部分依然是卷積,因其計算量比較大。這其中的D、E也就是我們常說的VGGNet-16和VGGNet-19。C很有意思,相比B多了幾個1´1的卷積層,1´1卷積的意義主要在於線性變換,而輸入通道數和輸出通道數不變,沒有發生降維。

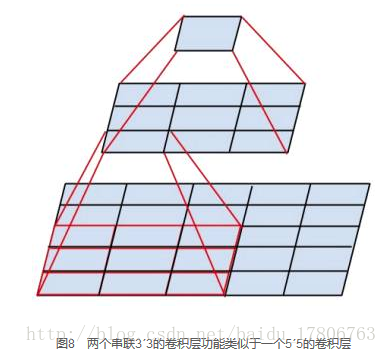
VGGNet擁有5段卷積,每一段內有2~3個卷積層,同時每段尾部會連線一個最大池化層用來縮小圖片尺寸。每段內的卷積核數量一樣,越靠後的段的卷積核數量越多:64 – 128 – 256 – 512 – 512。其中經常出現多個完全一樣的3´3的卷積層堆疊在一起的情況,這其實是非常有用的設計。如圖8所示,兩個3´3的卷積層串聯相當於1個5´5的卷積層,即一個畫素會跟周圍5´5的畫素產生關聯,可以說感受野大小為5´5。而3個3´3的卷積層串聯的效果則相當於1個7´7的卷積層。除此之外,3個串聯的3´3的卷積層,擁有比1個7´7的卷積層更少的引數量,只有後者的。最重要的是,3個3´3的卷積層擁有比1個7´7的卷積層更多的非線性變換(前者可以使用三次ReLU啟用函式,而後者只有一次),使得CNN對特徵的學習能力更強。
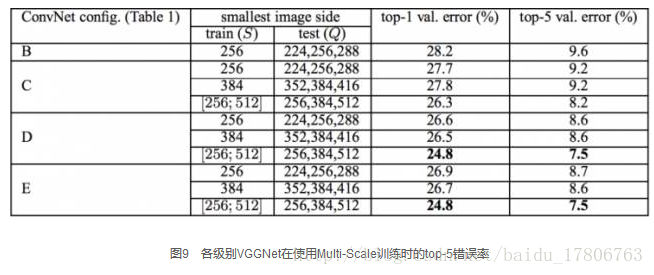
VGGNet在訓練時有一個小技巧,先訓練級別A的簡單網路,再複用A網路的權重來初始化後面的幾個複雜模型,這樣訓練收斂的速度更快。在預測時,VGG採用Multi-Scale的方法,將影象scale到一個尺寸Q,並將圖片輸入卷積網路計算。然後在最後一個卷積層使用滑窗的方式進行分類預測,將不同視窗的分類結果平均,再將不同尺寸Q的結果平均得到最後結果,這樣可提高圖片資料的利用率並提升預測準確率。同時在訓練中,VGGNet還使用了Multi-Scale的方法做資料增強,將原始影象縮放到不同尺寸S,然後再隨機裁切224´224的圖片,這樣能增加很多資料量,對於防止模型過擬合有很不錯的效果。實踐中,作者令S在[256,512]這個區間內取值,使用Multi-Scale獲得多個版本的資料,並將多個版本的資料合在一起進行訓練。圖9所示為VGGNet使用Multi-Scale訓練時得到的結果,可以看到D和E都可以達到7.5%的錯誤率。最終提交到ILSVRC 2014的版本是僅使用Single-Scale的6個不同等級的網路與Multi-Scale的D網路的融合,達到了7.3%的錯誤率。不過比賽結束後作者發現只融合Multi-Scale的D和E可以達到更好的效果,錯誤率達到7.0%,再使用其他優化策略最終錯誤率可達到6.8%左右,非常接近同年的冠軍Google Inceptin Net。同時,作者在對比各級網路時總結出了以下幾個觀點。
(1)LRN層作用不大。
(2)越深的網路效果越好。
(3)1*1的卷積也是很有效的,但是沒有3*3的卷積好,大一些的卷積核可以學習更大的空間特徵。
InceptionNet
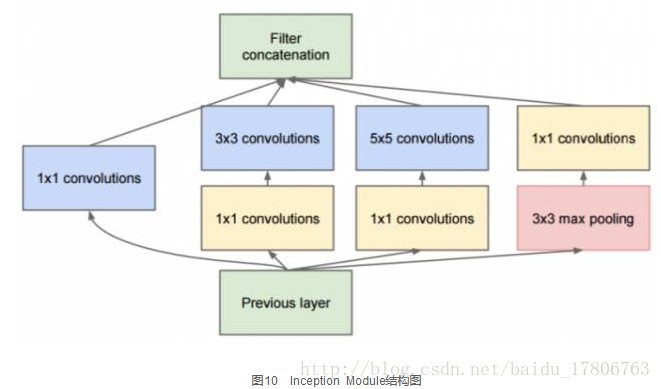
Google Inception Net首次出現在ILSVRC 2014的比賽中(和VGGNet同年),就以較大優勢取得了第一名。那屆比賽中的Inception Net通常被稱為Inception V1,它最大的特點是控制了計算量和引數量的同時,獲得了非常好的分類效能——top-5錯誤率6.67%,只有AlexNet的一半不到。Inception V1有22層深,比AlexNet的8層或者VGGNet的19層還要更深。但其計算量只有15億次浮點運算,同時只有500萬的引數量,僅為AlexNet引數量(6000萬)的1/12,卻可以達到遠勝於AlexNet的準確率,可以說是非常優秀並且非常實用的模型。Inception V1降低引數量的目的有兩點,第一,引數越多模型越龐大,需要供模型學習的資料量就越大,而目前高質量的資料非常昂貴;第二,引數越多,耗費的計算資源也會更大。Inception V1引數少但效果好的原因除了模型層數更深、表達能力更強外,還有兩點:一是去除了最後的全連線層,用全域性平均池化層(即將圖片尺寸變為1´1)來取代它。全連線層幾乎佔據了AlexNet或VGGNet中90%的引數量,而且會引起過擬合,去除全連線層後模型訓練更快並且減輕了過擬合。用全域性平均池化層取代全連線層的做法借鑑了Network In Network(以下簡稱NIN)論文。二是Inception V1中精心設計的Inception Module提高了引數的利用效率,其結構如圖10所示。這一部分也借鑑了NIN的思想,形象的解釋就是Inception Module本身如同大網路中的一個小網路,其結構可以反覆堆疊在一起形成大網路。不過Inception V1比NIN更進一步的是增加了分支網路,NIN則主要是級聯的卷積層和MLPConv層。一般來說卷積層要提升表達能力,主要依靠增加輸出通道數,但副作用是計算量增大和過擬合。每一個輸出通道對應一個濾波器,同一個濾波器共享引數,只能提取一類特徵,因此一個輸出通道只能做一種特徵處理。而NIN中的MLPConv則擁有更強大的能力,允許在輸出通道之間組合資訊,因此效果明顯。可以說,MLPConv基本等效於普通卷積層後再連線1´1的卷積和ReLU啟用函式。
我們再來看Inception Module的基本結構,其中有4個分支:第一個分支對輸入進行1´1的卷積,這其實也是NIN中提出的一個重要結構。1´1的卷積是一個非常優秀的結構,它可以跨通道組織資訊,提高網路的表達能力,同時可以對輸出通道升維和降維。可以看到Inception Module的4個分支都用到了1´1卷積,來進行低成本(計算量比3´3小很多)的跨通道的特徵變換。第二個分支先使用了1´1卷積,然後連線3´3卷積,相當於進行了兩次特徵變換。第三個分支類似,先是1´1的卷積,然後連線5´5卷積。最後一個分支則是3´3最大池化後直接使用1´1卷積。我們可以發現,有的分支只使用1´1卷積,有的分支使用了其他尺寸的卷積時也會再使用1´1卷積,這是因為1´1卷積的價效比很高,用很小的計算量就能增加一層特徵變換和非線性化。Inception Module的4個分支在最後通過一個聚合操作合併(在輸出通道數這個維度上聚合)。Inception Module中包含了3種不同尺寸的卷積和1個最大池化,增加了網路對不同尺度的適應性,這一部分和Multi-Scale的思想類似。早期計算機視覺的研究中,受靈長類神經視覺系統的啟發,Serre使用不同尺寸的Gabor濾波器處理不同尺寸的圖片,Inception V1借鑑了這種思想。Inception V1的論文中指出,Inception Module可以讓網路的深度和寬度高效率地擴充,提升準確率且不致於過擬合。
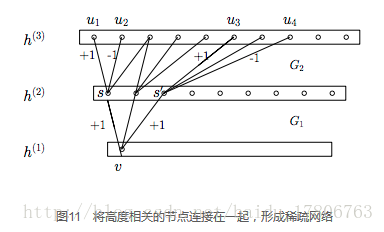
人腦神經元的連線是稀疏的,因此研究者認為大型神經網路的合理的連線方式應該也是稀疏的。稀疏結構是非常適合神經網路的一種結構,尤其是對非常大型、非常深的神經網路,可以減輕過擬合併降低計算量,例如卷積神經網路就是稀疏的連線。Inception Net的主要目標就是找到最優的稀疏結構單元(即Inception Module),論文中提到其稀疏結構基於Hebbian原理,這裡簡單解釋一下Hebbian原理:神經反射活動的持續與重複會導致神經元連線穩定性的持久提升,當兩個神經元細胞A和B距離很近,並且A參與了對B重複、持續的興奮,那麼某些代謝變化會導致A將作為能使B興奮的細胞。總結一下即“一起發射的神經元會連在一起”(Cells that fire together, wire together),學習過程中的刺激會使神經元間的突觸強度增加。受Hebbian原理啟發,另一篇文章Provable Bounds for Learning Some Deep Representations提出,如果資料集的概率分佈可以被一個很大很稀疏的神經網路所表達,那麼構築這個網路的最佳方法是逐層構築網路:將上一層高度相關(correlated)的節點聚類,並將聚類出來的每一個小簇(cluster)連線到一起,如圖11所示。這個相關性高的節點應該被連線在一起的結論,即是從神經網路的角度對Hebbian原理有效性的證明。
因此一個“好”的稀疏結構,應該是符合Hebbian原理的,我們應該把相關性高的一簇神經元節點連線在一起。在普通的資料集中,這可能需要對神經元節點聚類,但是在圖片資料中,天然的就是臨近區域的資料相關性高,因此相鄰的畫素點被卷積操作連線在一起。而我們可能有多個卷積核,在同一空間位置但在不同通道的卷積核的輸出結果相關性極高。因此,一個1´1的卷積就可以很自然地把這些相關性很高的、在同一個空間位置但是不同通道的特徵連線在一起,這就是為什麼1´1卷積這麼頻繁地被應用到Inception Net中的原因。1´1卷積所連線的節點的相關性是最高的,而稍微大一點尺寸的卷積,比如3´3、5´5的卷積所連線的節點相關性也很高,因此也可以適當地使用一些大尺寸的卷積,增加多樣性(diversity)。最後Inception Module通過4個分支中不同尺寸的1´1、3´3、5´5等小型卷積將相關性很高的節點連線在一起,就完成了其設計初衷,構建出了很高效的符合Hebbian原理的稀疏結構。
在Inception Module中,通常1´1卷積的比例(輸出通道數佔比)最高,3´3卷積和5´5卷積稍低。而在整個網路中,會有多個堆疊的Inception Module,我們希望靠後的Inception Module可以捕捉更高階的抽象特徵,因此靠後的Inception Module的卷積的空間集中度應該逐漸降低,這樣可以捕獲更大面積的特徵。因此,越靠後的Inception Module中,3´3和5´5這兩個大面積的卷積核的佔比(輸出通道數)應該更多。
Inception Net有22層深,除了最後一層的輸出,其中間節點的分類效果也很好。因此在Inception Net中,還使用到了輔助分類節點(auxiliary classifiers),即將中間某一層的輸出用作分類,並按一個較小的權重(0.3)加到最終分類結果中。這樣相當於做了模型融合,同時給網路增加了反向傳播的梯度訊號,也提供了額外的正則化,對於整個Inception Net的訓練很有裨益。
當年的Inception V1還是跑在TensorFlow的前輩DistBelief上的,並且只執行在CPU上。當時使用了非同步的SGD訓練,學習速率每迭代8個epoch降低4%。同時,Inception V1也使用了Multi-Scale、Multi-Crop等資料增強方法,並在不同的取樣資料上訓練了7個模型進行融合,得到了最後的ILSVRC 2014的比賽成績——top-5錯誤率6.67%。
同時,Google Inception Net還是一個大家族,包括:
—
2014年9月的論文Going Deeper with Convolutions提出的Inception V1(top-5錯誤率6.67%)。—
2015年2月的論文Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate提出的Inception V2(top-5錯誤率4.8%)。—
2015年12月的論文Rethinking the Inception Architecture for Computer Vision提出的Inception V3(top-5錯誤率3.5%)。—
2016年2月的論文Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning提出的Inception V4(top-5錯誤率3.08%)。
Inception V2學習了VGGNet,用兩個3´3的卷積代替5´5的大卷積(用以降低引數量並減輕過擬合),還提出了著名的Batch Normalization(以下簡稱BN)方法。BN是一個非常有效的正則化方法,可以讓大型卷積網路的訓練速度加快很多倍,同時收斂後的分類準確率也可以得到大幅提高。BN在用於神經網路某層時,會對每一個mini-batch資料的內部進行標準化(normalization)處理,使輸出規範化到N(0,1)的正態分佈,減少了Internal Covariate Shift(內部神經元分佈的改變)。BN的論文指出,傳統的深度神經網路在訓練時,每一層的輸入的分佈都在變化,導致訓練變得困難,我們只能使用一個很小的學習速率解決這個問題。而對每一層使用BN之後,我們就可以有效地解決這個問題,學習速率可以增大很多倍,達到之前的準確率所需要的迭代次數只有1/14,訓練時間大大縮短。而達到之前的準確率後,可以繼續訓練,並最終取得遠超於Inception V1模型的效能——top-5錯誤率4.8%,已經優於人眼水平。因為BN某種意義上還起到了正則化的作用,所以可以減少或者取消Dropout,簡化網路結構。
當然,只是單純地使用BN獲得的增益還不明顯,還需要一些相應的調整:增大學習速率並加快學習衰減速度以適用BN規範化後的資料;去除Dropout並減輕L2正則(因BN已起到正則化的作用);去除LRN;更徹底地對訓練樣本進行shuffle;減少資料增強過程中對資料的光學畸變(因為BN訓練更快,每個樣本被訓練的次數更少,因此更真實的樣本對訓練更有幫助)。在使用了這些措施後,Inception V2在訓練達到Inception V1的準確率時快了14倍,並且模型在收斂時的準確率上限更高。
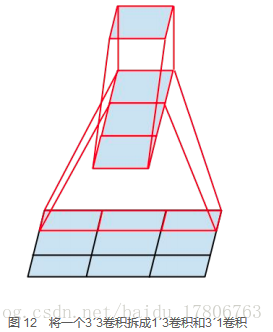
而Inception V3網路則主要有兩方面的改造:一是引入了Factorization into small convolutions的思想,將一個較大的二維卷積拆成兩個較小的一維卷積,比如將7´7卷積拆成1´7卷積和7´1卷積,或者將3´3卷積拆成1´3卷積和3´1卷積,如圖12所示。一方面節約了大量引數,加速運算並減輕了過擬合(比將7´7卷積拆成1´7卷積和7´1卷積,比拆成3個3´3卷積更節約引數),同時增加了一層非線性擴充套件模型表達能力。論文中指出,這種非對稱的卷積結構拆分,其結果比對稱地拆為幾個相同的小卷積核效果更明顯,可以處理更多、更豐富的空間特徵,增加特徵多樣性。
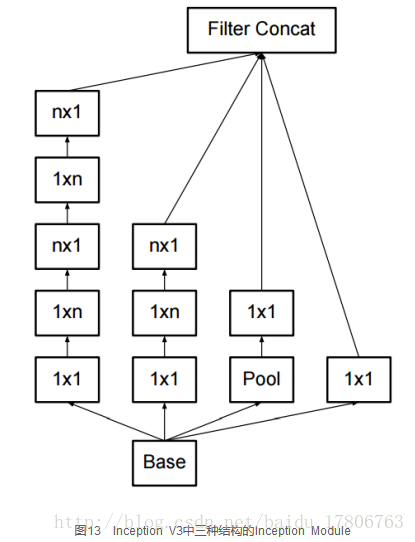
另一方面,Inception V3優化了Inception Module的結構,現在Inception Module有35´35、17´17和8´8三種不同結構,如圖13所示。這些Inception Module只在網路的後部出現,前部還是普通的卷積層。並且Inception V3除了在Inception Module中使用分支,還在分支中使用了分支(8´8的結構中),可以說是Network In Network In Network。
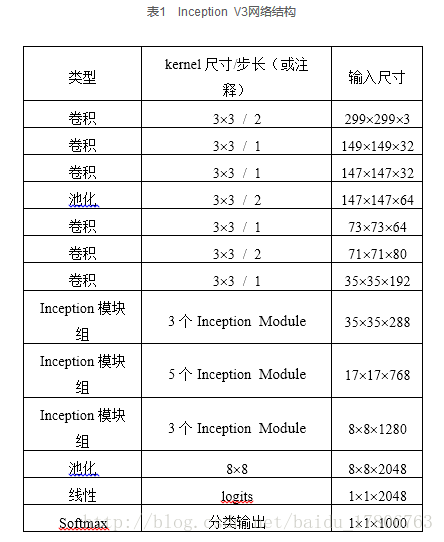
而Inception V4相比V3主要是結合了微軟的ResNet,而ResNet將在6.4節單獨講解,這裡不多做贅述。因此本節將實現的是Inception V3,其整個網路結構如表1所示。由於Google Inception Net V3相對比較複雜,所以這裡使用tf.contrib.slim輔助設計這個網路。contrib.slim中的一些功能和元件可以大大減少設計Inception Net的程式碼量,我們只需要少量程式碼即可構建好有42層深的Inception V3。
ResNet
ResNet(Residual Neural Network)由微軟研究院的Kaiming He等4名華人提出,通過使用Residual Unit成功訓練152層深的神經網路,在ILSVRC 2015比賽中獲得了冠軍,取得3.57%的top-5錯誤率,同時引數量卻比VGGNet低,效果非常突出。ResNet的結構可以極快地加速超深神經網路的訓練,模型的準確率也有非常大的提升。6.3節我們講解並實現了Inception V3,而Inception V4則是將Inception Module和ResNet相結合。可以看到ResNet是一個推廣性非常好的網路結構,甚至可以直接應用到Inception Net中。本節就講解ResNet的基本原理,以及如何用TensorFlow來實現它。
在ResNet之前,瑞士教授Schmidhuber提出了Highway Network,原理與ResNet很相似。這位Schmidhuber教授同時也是LSTM網路的發明者,而且是早在1997年發明的,可謂是神經網路領域元老級的學者。通常認為神經網路的深度對其效能非常重要,但是網路越深其訓練難度越大,Highway Network的目標就是解決極深的神經網路難以訓練的問題。Highway Network相當於修改了每一層的啟用函式,此前的啟用函式只是對輸入做一個非線性變換,Highway NetWork則允許保留一定比例的原始輸入x,即,其中T為變換系數,C為保留係數,論文中令。這樣前面一層的資訊,有一定比例可以不經過矩陣乘法和非線性變換,直接傳輸到下一層,彷彿一條資訊高速公路,因此得名Highway Network。
Highway Network主要通過gating units學習如何控制網路中的資訊流,即學習原始資訊應保留的比例。這個可學習的gating機制,正是借鑑自Schmidhuber教授早年的LSTM迴圈神經網路中的gating。幾百乃至上千層深的Highway Network可以直接使用梯度下降演算法訓練,並可以配合多種非線性啟用函式,學習極深的神經網路現在變得可行了。事實上,Highway Network的設計在理論上允許其訓練任意深的網路,其優化方法基本上與網路的深度獨立,而傳統的神經網路結構則對深度非常敏感,訓練複雜度隨深度增加而急劇增加。
ResNet和HighWay Network非常類似,也是允許原始輸入資訊直接傳輸到後面的層中。ResNet最初的靈感出自這個問題:在不斷加神經網路的深度時,會出現一個Degradation的問題,即準確率會先上升然後達到飽和,再持續增加深度則會導致準確率下降。這並不是過擬合的問題,因為不光在測試集上誤差增大,訓練集本身誤差也會增大。假設有一個比較淺的網路達到了飽和的準確率,那麼後面再加上幾個的全等對映層,起碼誤差不會增加,即更深的網路不應該帶來訓練集上誤差上升。而這裡提到的使用全等對映直接將前一層輸出傳到後面的思想,就是ResNet的靈感來源。
假定某段神經網路的輸入是x,期望輸出是,如果我們直接把輸入x傳到輸出作為初始結果,那麼此時我們需要學習的目標就是。如圖14所示,這就是一個ResNet的殘差學習單元(Residual Unit),ResNet相當於將學習目標改變了,不再是學習一個完整的輸出,只是輸出和輸入的差別,即殘差。
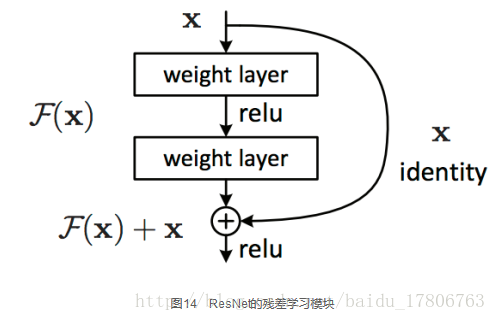
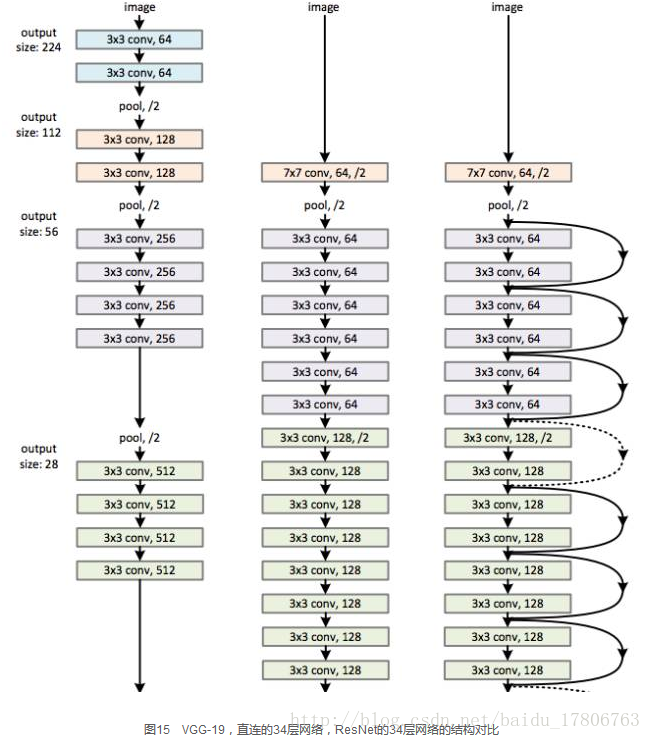
圖15所示為VGGNet-19,以及一個34層深的普通卷積網路,和34層深的ResNet網路的對比圖。可以看到普通直連的卷積神經網路和ResNet的最大區別在於,ResNet有很多旁路的支線將輸入直接連到後面的層,使得後面的層可以直接學習殘差,這種結構也被稱為shortcut或skip connections。
傳統的卷積層或全連線層在資訊傳遞時,或多或少會存在資訊丟失、損耗等問題。ResNet在某種程度上解決了這個問題,通過直接將輸入資訊繞道傳到輸出,保護資訊的完整性,整個網路則只需要學習輸入、輸出差別的那一部分,簡化學習目標和難度。
在ResNet的論文中,除了提出圖14中的兩層殘差學習單元,還有三層的殘差學習單元。兩層的殘差學習單元中包含兩個相同輸出通道數(因為殘差等於目標輸出減去輸入,即,因此輸入、輸出維度需保持一致)的3´3卷積;而3層的殘差網路則使用了Network In Network和Inception Net中的1´1卷積,並且是在中間3´3的卷積前後都使用了1´1卷積,有先降維再升維的操作。另外,如果有輸入、輸出維度不同的情況,我們可以對x做一個線性對映變換維度,再連線到後面的層。
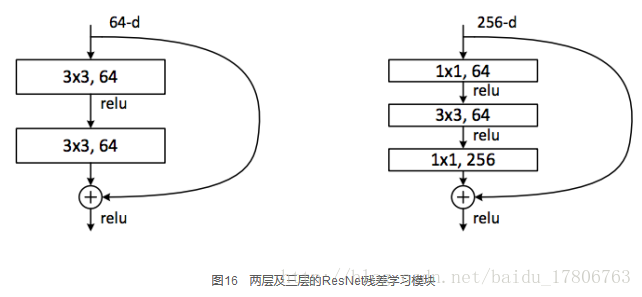
圖17所示為ResNet在不同層數時的網路配置,其中基礎結構很類似,都是前面提到的兩層和三層的殘差學習單元的堆疊。
在使用了ResNet的結構後,可以發現層數不斷加深導致的訓練集上誤差增大的現象被消除了,ResNet網路的訓練誤差會隨著層數增大而逐漸減小,並且在測試集上的表現也會變好。在ResNet推出後不久,Google就借鑑了ResNet的精髓,提出了Inception V4和Inception-ResNet-V2,並通過融合這兩個模型,在ILSVRC資料集上取得了驚人的3.08%的錯誤率。
可見,ResNet及其思想對卷積神經網路研究的貢獻確實非常顯著,具有很強的推廣性。在ResNet的作者的第二篇相關論文Identity Mappings in Deep Residual Networks中,ResNet V2被提出。ResNet V2和ResNet V1的主要區別在於,作者通過研究ResNet殘差學習單元的傳播公式,發現前饋和反饋訊號可以直接傳輸,因此skip connection的非線性啟用函式(如ReLU)替換為Identity Mappings()。同時,ResNet V2在每一層中都使用了Batch Normalization。這樣處理之後,新的殘差學習單元將比以前更容易訓練且泛化性更強。
根據Schmidhuber教授的觀點,ResNet類似於一個沒有gates的LSTM網路,即將輸入x傳遞到後面層的過程是一直髮生的,而不是學習出來的。同時,最近也有兩篇論文表示,ResNet基本等價於RNN且ResNet的效果類似於在多層網路間的整合方法(ensemble)。ResNet在加深網路層數上做出了重大貢獻,而另一篇論文The Power of Depth for Feedforward Neural Networks則從理論上證明了加深網路比加寬網路更有效,算是給ResNet提供了聲援,也是給深度學習為什麼要深才有效提供了合理解釋。
總結
以上,我們簡單回顧了卷積神經網路的歷史,圖18所示大致勾勒出最近幾十年卷積神經網路的發展方向。
Perceptron(感知機)於1957年由Frank Resenblatt提出,而Perceptron不僅是卷積網路,也是神經網路的始祖。Neocognitron(神經認知機)是一種多層級的神經網路,由日本科學家Kunihiko Fukushima於20世紀80年代提出,具有一定程度的視覺認知的功能,並直接啟發了後來的卷積神經網路。LeNet-5由CNN之父Yann LeCun於1997年提出,首次提出了多層級聯的卷積結構,可對手寫數字進行有效識別。
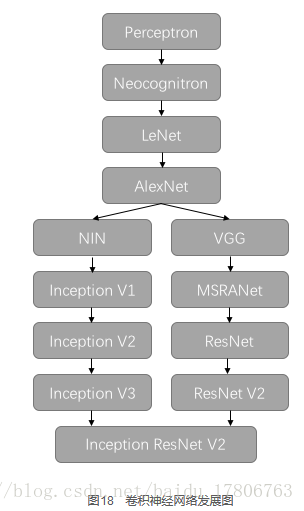
可以看到前面這三次關於卷積神經網路的技術突破,間隔時間非常長,需要十餘年甚至更久才出現一次理論創新。而後於2012年,Hinton的學生Alex依靠8層深的卷積神經網路一舉獲得了ILSVRC 2012比賽的冠軍,瞬間點燃了卷積神經網路研究的熱潮。AlexNet成功應用了ReLU啟用函式、Dropout、最大覆蓋池化、LRN層、GPU加速等新技術,並啟發了後續更多的技術創新,卷積神經網路的研究從此進入快車道。
在AlexNet之後,我們可以將卷積神經網路的發展分為兩類,一類是網路結構上的改進調整(圖18中的左側分支),另一類是網路深度的增加(圖18中的右側分支)。
2013年,顏水成教授的Network in Network工作首次發表,優化了卷積神經網路的結構,並推廣了1´1的卷積結構。在改進卷積網路結構的工作中,後繼者還有2014年的Google Inception Net V1,提出了Inception Module這個可以反覆堆疊的高效的卷積網路結構,並獲得了當年ILSVRC比賽的冠軍。2015年初的Inception V2提出了Batch Normalization,大大加速了訓練過程,並提升了網路效能。2015年年末的Inception V3則繼續優化了網路結構,提出了Factorization in Small Convolutions的思想,分解大尺寸卷積為多個小卷積乃至一維卷積。
而另一條分支上,許多研究工作則致力於加深網路層數,2014年,ILSVRC比賽的亞軍VGGNet全程使用3´3的卷積,成功訓練了深達19層的網路,當年的季軍MSRA-Net也使用了非常深的網路。2015年,微軟的ResNet成功訓練了152層深的網路,一舉拿下了當年ILSVRC比賽的冠軍,top-5錯誤率降低至3.46%。其後又更新了ResNet V2,增加了Batch Normalization,並去除了啟用層而使用Identity Mapping或Preactivation,進一步提升了網路效能。此後,Inception ResNet V2融合了Inception Net優良的網路結構,和ResNet訓練極深網路的殘差學習模組,集兩個方向之長,取得了更好的分類效果。
我們可以看到,自AlexNet於2012年提出後,深度學習領域的研究發展極其迅速,基本上每年甚至每幾個月都會出現新一代的技術。新的技術往往伴隨著新的網路結構,更深的網路的訓練方法等,並在影象識別等領域不斷創造新的準確率記錄。至今,ILSVRC比賽和卷積神經網路的研究依然處於高速發展期,CNN的技術日新月異。當然其中不可忽視的推動力是,我們擁有了更快的GPU計算資源用以實驗,以及非常方便的開源工具(比如TensorFlow)可以讓研究人員快速地進行探索和嘗試。在以前,研究人員如果沒有像Alex那樣高超的程式設計實力能自己實現cuda-convnet,可能都沒辦法設計CNN或者快速地進行實驗。現在有了TensorFlow,研究人員和開發人員都可以簡單而快速地設計神經網路結構並進行研究、測試、部署乃至實用。
本文並非原創
由於此文對CNN發展歷程介紹較為詳細,想要留存下來,以便後續檢視,又怕原文連結可能會失效,顧貼上至此。
侵刪。
EMMA
SIAT
2017.03.01