
吳恩達卷積神經網路——深度卷積網路:例項探究
經典網路
LeNet5

隨著網路的加深,影象的高度和寬度在縮小,通道數量增加
池化後使用sigmoid函式
AlexNet
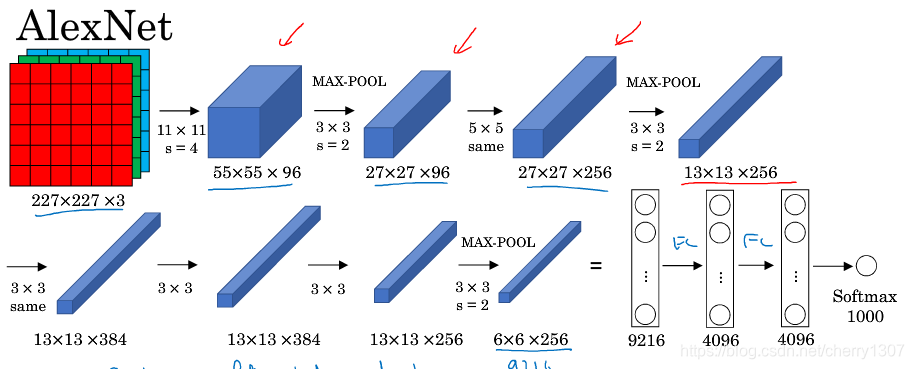
與LeNet相似,但大得多
使用ReLu函式
VGG-16
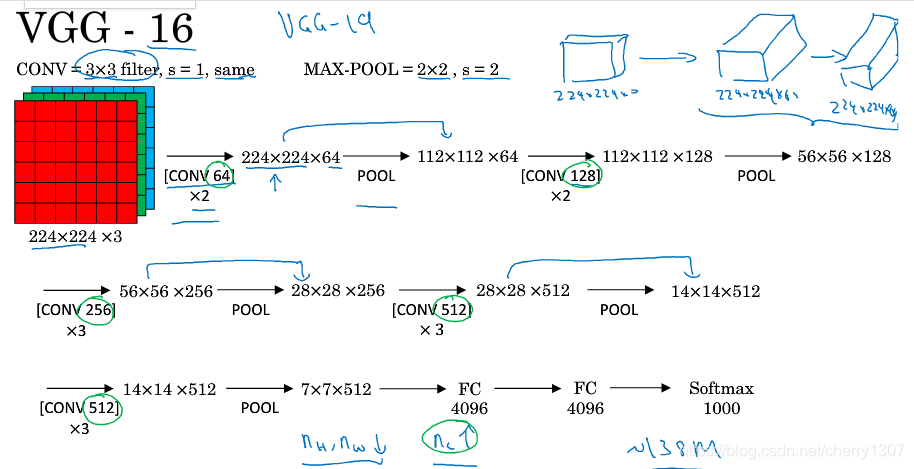
網路大,但結構並不複雜
影象縮小的比例和通道增加的比例是有規律的
64->128->256->521
殘差網路
非常深的網路是很難訓練的,因為存在梯度消失和梯度爆炸問題。
skip connection:可以從某一層獲取啟用函式,然後迅速反饋給另外一層甚至網路更深層。
利用skip connection訓練ResNets。
ResNets是由殘差塊構成。

從a^ [l]到a^ [l+2]尋妖經過上圖步驟,但還有一個捷徑:
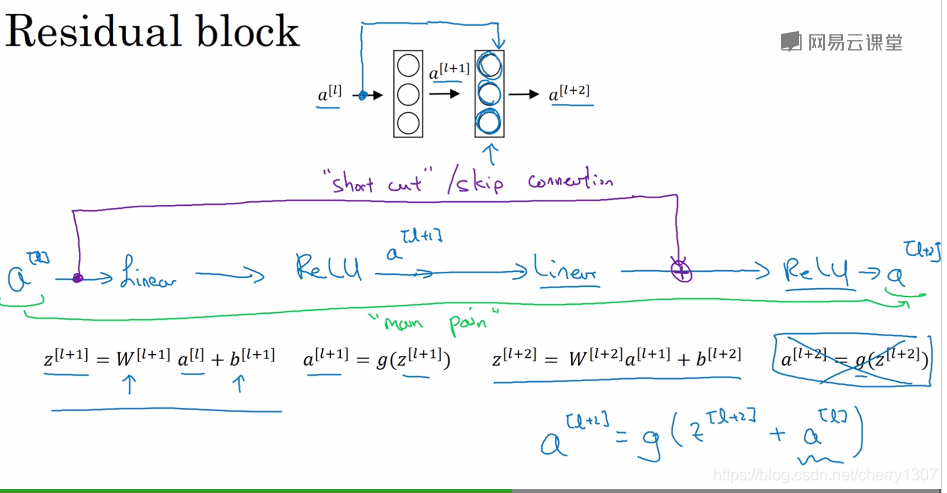
線上性啟用函式之後,在ReLu啟用函式之前
殘差網路

如果使用一個標準優化演算法訓練一個普通網路,如果沒有多餘的殘差,憑經驗會發現,隨著網路深度的增加,訓練誤差會先減小後的增大。但理論上,隨著網路深度的增加,會訓練的越來越好。
有了殘差網路,即使網路再深,訓練的表現卻不錯。
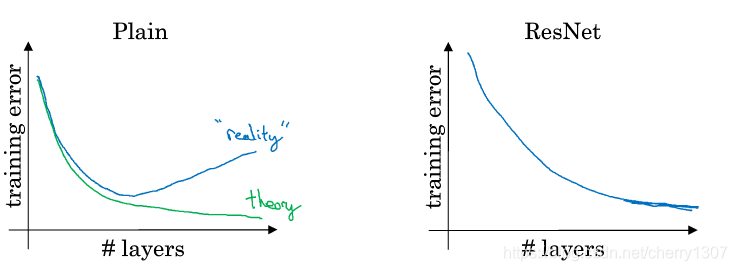
為什麼殘差網路有用?
假設一個大型神經網路輸入為X,輸出啟用函式為a^ [l],如果想加深:
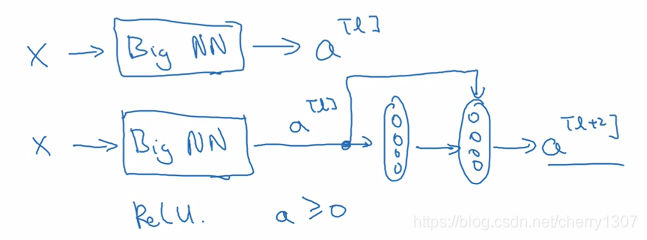
假設啟用函式為:ReLu,則a^ [l+2]為:
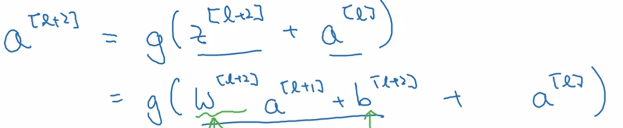

a^ [l+2] = g(a^ [l])
起作用的原因:這些殘差塊學習恆等函式非常容易,不會降低效率,提升網路效能。
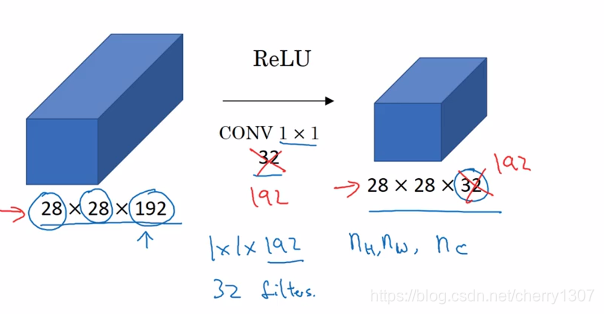
1*1卷積
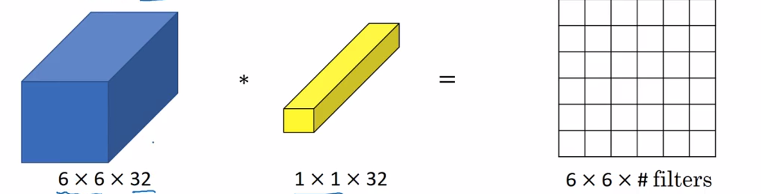
1*1卷積所實現的功能是:遍歷這36個單元格,計算作圖32個數字和卷積核中32個數字的元素智慧乘積,然後應用ReLu函式。
給NN增加了一個非線性函式,從而減小或保持輸入層中通道不變。
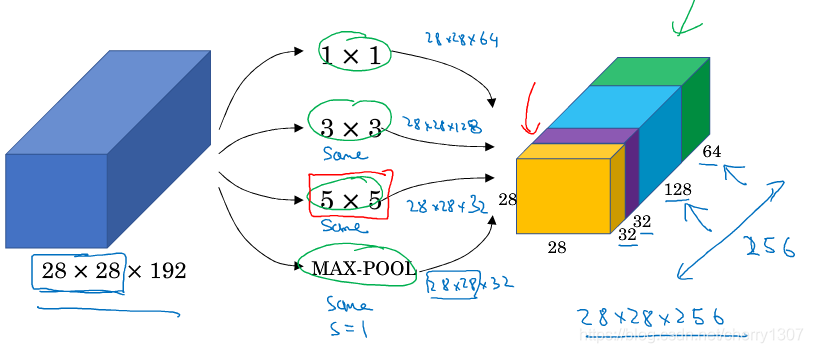
Inception網路
作用:代替人工確定卷積層中卷積核的型別或確定是否需要建立卷積層或池化層。
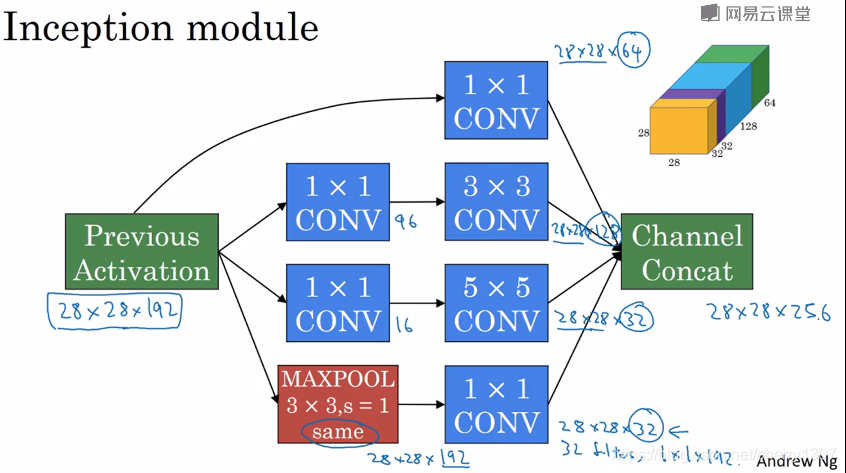
Inception模組
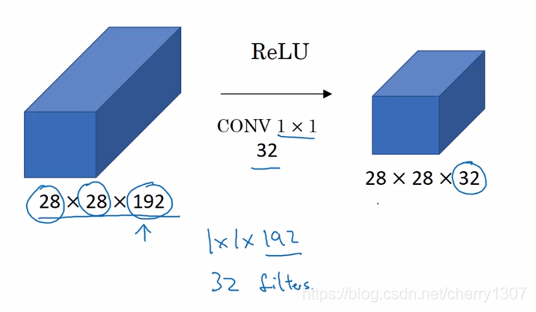
輸入為2828192
輸入為2828256
基本思想:網路自行決定使用哪個卷積核或池化,給網路新增這些引數的所有可能值,然後把這些輸入連線起來,讓網路自己學習需要哪些引數,哪些卷積核組合。
計算成本:
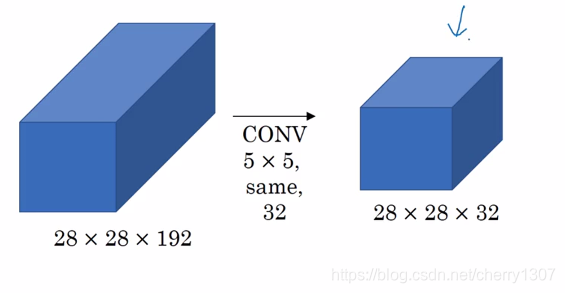
28281925532 = 120M
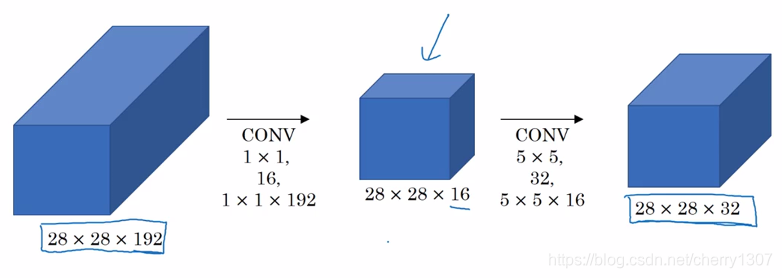
28281921116+28281655*32=12.4M
計算成本大大降低
瓶頸設計合理
既可以縮小表示層規模又不會降低網路效能,從而大量節省的計算
Inception網路
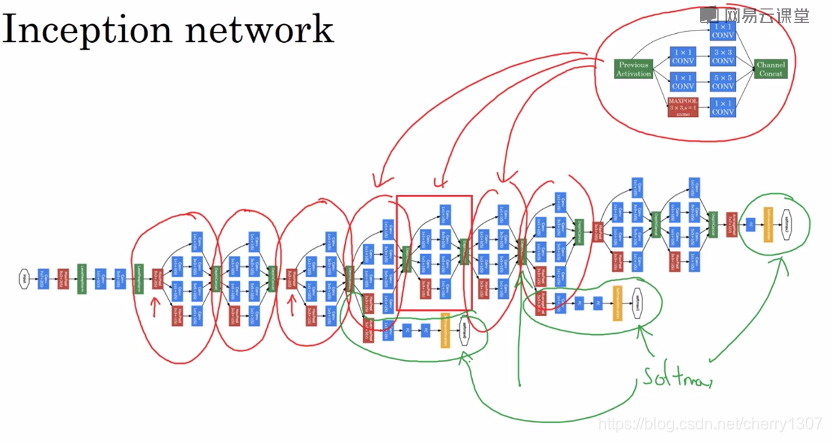 在網路的最後基層通常是全連線,在它之後是喲個softmax層,做預測,這些分支就是通過隱藏層來做預測,事實上就是一個softmax層,它確保了即使是隱藏單元和中間層也參加了特徵計算,它們也能做影象分類,他在Inception網路中起調整作用,並能防止網路過擬合。
在網路的最後基層通常是全連線,在它之後是喲個softmax層,做預測,這些分支就是通過隱藏層來做預測,事實上就是一個softmax層,它確保了即使是隱藏單元和中間層也參加了特徵計算,它們也能做影象分類,他在Inception網路中起調整作用,並能防止網路過擬合。
遷移學習
將公共資料集的知識遷移到自己的問題上
資料擴充
垂直映象對稱
色彩變換
隨機剪裁
旋轉
剪下
區域性彎曲