
細聊分散式ID生成方法
一、需求緣起
幾乎所有的業務系統,都有生成一個記錄標識的需求,例如:
(1)訊息標識:message-id
(2)訂單標識:order-id
(3)帖子標識:tiezi-id
這個記錄標識往往就是資料庫中的唯一主鍵,資料庫上會建立聚集索引(cluster index),即在物理儲存上以這個欄位排序。
這個記錄標識上的查詢,往往又有分頁或者排序的業務需求,例如:
(1)拉取最新的一頁訊息:selectmessage-id/ order by time/ limit 100
(2)拉取最新的一頁訂單:selectorder-id/ order by time/ limit 100
(3)拉取最新的一頁帖子:selecttiezi-id/ order by time/ limit 100
所以往往要有一個time欄位,並且在time欄位上建立普通索引(non-cluster index)。
我們都知道普通索引儲存的是實際記錄的指標,其訪問效率會比聚集索引慢,如果記錄標識在生成時能夠基本按照時間有序,則可以省去這個time欄位的索引查詢:
select message-id/ (order by message-id)/limit 100
再次強調,能這麼做的前提是,message-id的生成基本是趨勢時間遞增的。
這就引出了記錄標識生成(也就是上文提到的三個XXX-id)的兩大核心需求:
(1)全域性唯一
(2)趨勢有序
這也是本文要討論的核心問題:如何高效生成趨勢有序的全域性唯一ID。
二、常見方法、不足與優化
【常見方法一:使用資料庫的 auto_increment 來生成全域性唯一遞增ID】
優點:
(1)簡單,使用資料庫已有的功能
(2)能夠保證唯一性
(3)能夠保證遞增性
(4)步長固定
缺點:
(1)可用性難以保證:資料庫常見架構是一主多從+讀寫分離,生成自增ID是寫請求,主庫掛了就玩不轉了
(2)擴充套件性差,效能有上限:因為寫入是單點,資料庫主庫的寫效能決定ID的生成效能上限,並且難以擴充套件
改進方法:
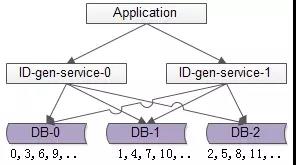
(1)增加主庫,避免寫入單點
(2)資料水平切分,保證各主庫生成的ID不重複
如上圖所述,由1個寫庫變成3個寫庫,每個寫庫設定不同的auto_increment初始值,以及相同的增長步長,以保證每個資料庫生成的
改進後的架構保證了可用性,但缺點是:
(1)喪失了ID生成的“絕對遞增性”:先訪問庫0生成0,3,再訪問庫1生成1,可能導致在非常短的時間內,ID生成不是絕對遞增的(這個問題不大,我們的目標是趨勢遞增,不是絕對遞增)
(2)資料庫的寫壓力依然很大,每次生成ID都要訪問資料庫
為了解決上述兩個問題,引出了第二個常見的方案
【常見方法二:單點批量ID生成服務】
分散式系統之所以難,很重要的原因之一是“沒有一個全域性時鐘,難以保證絕對的時序”,要想保證絕對的時序,還是隻能使用單點服務,用本地時鐘保證“絕對時序”。資料庫寫壓力大,是因為每次生成ID都訪問了資料庫,可以使用批量的方式降低資料庫寫壓力。
如上圖所述,資料庫使用雙master保證可用性,資料庫中只儲存當前ID的最大值,例如0。ID生成服務假設每次批量拉取6個ID,服務訪問資料庫,將當前ID的最大值修改為5,這樣應用訪問ID生成服務索要ID,ID生成服務不需要每次訪問資料庫,就能依次派發0,1,2,3,4,5這些ID了,當ID發完後,再將ID的最大值修改為11,就能再次派發6,7,8,9,10,11這些ID了,於是資料庫的壓力就降低到原來的1/6了。
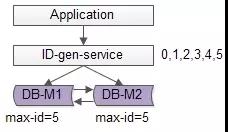
優點:
(1)保證了ID生成的絕對遞增有序
(2)大大的降低了資料庫的壓力,ID生成可以做到每秒生成幾萬幾十萬個
缺點:
(1)服務仍然是單點
(2)如果服務掛了,服務重啟起來之後,繼續生成ID可能會不連續,中間出現空洞(服務記憶體是儲存著0,1,2,3,4,5,資料庫中max-id是5,分配到3時,服務重啟了,下次會從6開始分配,4和5就成了空洞,不過這個問題也不大)
(3)雖然每秒可以生成幾萬幾十萬個ID,但畢竟還是有效能上限,無法進行水平擴充套件
改進方法:
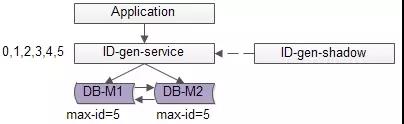
單點服務的常用高可用優化方案是“備用服務”,也叫“影子服務”,所以我們能用以下方法優化上述缺點(1):
如上圖,對外提供的服務是主服務,有一個影子服務時刻處於備用狀態,當主服務掛了的時候影子服務頂上。這個切換的過程對呼叫方是透明的,可以自動完成,常用的技術是vip+keepalived,具體就不在這裡展開。
【常見方法三:uuid】
上述方案來生成ID,雖然效能大增,但由於是單點系統,總還是存在效能上限的。同時,上述兩種方案,不管是資料庫還是服務來生成ID,業務方Application都需要進行一次遠端呼叫,比較耗時。有沒有一種本地生成ID的方法,即高效能,又時延低呢?
uuid是一種常見的方案:string ID =GenUUID();
優點:
(1)本地生成ID,不需要進行遠端呼叫,時延低
(2)擴充套件性好,基本可以認為沒有效能上限
缺點:
(1)無法保證趨勢遞增
(2)uuid過長,往往用字串表示,作為主鍵建立索引查詢效率低,常見優化方案為“轉化為兩個uint64整數儲存”或者“折半儲存”(折半後不能保證唯一性)
【常見方法四:取當前毫秒數】
uuid是一個本地演算法,生成效能高,但無法保證趨勢遞增,且作為字串ID檢索效率低,有沒有一種能保證遞增的本地演算法呢?
取當前毫秒數是一種常見方案:uint64 ID = GenTimeMS();
優點:
(1)本地生成ID,不需要進行遠端呼叫,時延低
(2)生成的ID趨勢遞增
(3)生成的ID是整數,建立索引後查詢效率高
缺點:
(1)如果併發量超過1000,會生成重複的ID
我去,這個缺點要了命了,不能保證ID的唯一性。當然,使用微秒可以降低衝突概率,但每秒最多隻能生成1000000個ID,再多的話就一定會衝突了,所以使用微秒並不從根本上解決問題。
【常見方法五:類snowflake演算法】
snowflake是twitter開源的分散式ID生成演算法,其核心思想是:一個long型的ID,使用其中41bit作為毫秒數,10bit作為機器編號,12bit作為毫秒內序列號。這個演算法單機每秒內理論上最多可以生成1000*(2^12),也就是400W的ID,完全能滿足業務的需求。
借鑑snowflake的思想,結合各公司的業務邏輯和併發量,可以實現自己的分散式ID生成演算法。
舉例,假設某公司ID生成器服務的需求如下:
(1)單機高峰併發量小於1W,預計未來5年單機高峰併發量小於10W
(2)有2個機房,預計未來5年機房數量小於4個
(3)每個機房機器數小於100臺
(4)目前有5個業務線有ID生成需求,預計未來業務線數量小於10個
(5)…
分析過程如下:
(1)高位取從2016年1月1日到現在的毫秒數(假設系統ID生成器服務在這個時間之後上線),假設系統至少執行10年,那至少需要10年*365天*24小時*3600秒*1000毫秒=320*10^9,差不多預留39bit給毫秒數
(2)每秒的單機高峰併發量小於10W,即平均每毫秒的單機高峰併發量小於100,差不多預留7bit給每毫秒內序列號
(3)5年內機房數小於4個,預留2bit給機房標識
(4)每個機房小於100臺機器,預留7bit給每個機房內的伺服器標識
(5)業務線小於10個,預留4bit給業務線標識
這樣設計的64bit標識,可以保證:

(1)每個業務線、每個機房、每個機器生成的ID都是不同的
(2)同一個機器,每個毫秒內生成的ID都是不同的
(3)同一個機器,同一個毫秒內,以序列號區區分保證生成的ID是不同的
(4)將毫秒數放在最高位,保證生成的ID是趨勢遞增的
缺點:
(1)由於“沒有一個全域性時鐘”,每臺伺服器分配的ID是絕對遞增的,但從全域性看,生成的ID只是趨勢遞增的(有些伺服器的時間早,有些伺服器的時間晚)
最後一個容易忽略的問題:
生成的ID,例如message-id/ order-id/ tiezi-id,在資料量大時往往需要分庫分表,這些ID經常作為取模分庫分表的依據,為了分庫分表後資料均勻,ID生成往往有“取模隨機性”的需求,所以我們通常把每秒內的序列號放在ID的最末位,保證生成的ID是隨機的。
相關推薦
細聊分散式ID生成方法
一、需求緣起幾乎所有的業務系統,都有生成一個記錄標識的需求,例如:(1)訊息標識:message-id(2)訂單標識:order-id(3)帖子標識:tiezi-id這個記錄標識往往就是資料庫中的唯一主鍵,資料庫上會建立聚集索引(cluster index),即在物理儲存上以
分散式ID生成方法
今年企業對Java開發的市場需求,你看懂了嗎? >>>
分散式ID生成策略(1)_snowflake演算法
轉載: 最近在研究分散式ID的生成方法,發現Twitter的snowflake演算法挺有意思,因此親自動手用Java進行了實現。 snowflake演算法的原理就是用64位整數來表示主鍵,其結構如下圖: 1 bit符號位:設計者不喜歡負數主鍵?方便使用負數標識不正確
基於TwitterSnowflake分散式id生成工具類實現
1、 什麼是TwitterSnowflake? 簡介: TwitterSnowflake演算法是用來在分散式場景下生成唯一ID的。 舉個栗子:我們有10臺分散式MySql伺服器,我們的系統每秒能生成10W條資料插入到這10臺機器裡,現在我們需要為每一條資料生成一個全域性唯一的ID,
分散式ID生成系統 UUID與雪花(snowflake)演算法
Leaf——美團點評分散式ID生成系統 -https://tech.meituan.com/MT_Leaf.html 網遊伺服器中的GUID(唯一標識碼)實現-基於snowflake演算法-雲棲社群-阿里雲https://yq.aliyun.com/articles/229420 UUID_STRING
分散式ID生成
幾乎所有的業務系統,都會有很多表記錄,都有生成一個記錄標識的需求,或者直接使用資料自帶的自增鍵,或者自己開發(一般大公司有中介軟體部門提供元件或服務),作為工程師也是我們要掌握的技能,過往實踐中,碰到過不少ID生成場景,如: 資料量不大(資料在千萬以下),寫入併發未
Java叢集環境下全域性唯一流水ID生成方法之一
package com.pfq.deal.risk.util; import java.net.InetAddress; import java.net.UnknownHostException; import java.text.SimpleDateFormat; im
SnowFlake --- 分散式id生成演算法工具類
package util; import java.lang.management.ManagementFactory; import java.net.InetAddress; import java.net.NetworkInterface; /** *
SnowFlake --- 分散式id生成演算法
概述 SnowFlake演算法生成id的結果是一個64bit大小的整數,它的結構如下圖: 1位,不用。二進位制中最高位為1的都是負數,但是我們生成的id一般都使用整數,所以這個最高位固定是0 41位,用來記錄時間戳(毫秒)。 41位可以表示241
Leaf:美團分散式ID生成服務開源
開發十年,就只剩下這套架構體系了! >>>
常見分散式ID生成策略總結
Twitter的雪花演算法 Java實現 滴滴的TinyId TinyId官方Github地址 百度uid-generat
分散式id生成方案總結
ID是資料的唯一標識,傳統的做法是利用UUID和資料庫的自增ID,在網際網路企業中,大部分公司使用的都是Mysql,並且因為需要事務支援,所以通常會使用Innodb儲存引擎,UUID太長以及無序,所以並不適合在Innodb中來作為主鍵,自增ID比較合適,但是隨著公司的業務發展,資料量將越來越大,需要對資料進行
一口氣說出 9種 分散式ID生成方式,面試官有點懵了
整理了一些Java方面的架構、面試資料(微服務、叢集、分散式、中介軟體等),有需要的小夥伴可以關注公眾號【程式設計師內點事】,無套路自行領取 本文作者:程式設計師內點事 原文連結:https://mp.weixin.qq.com/s?__biz=MzAxNTM4NzAyNg 更多精選 3萬字總結,Mys
9種分散式ID生成之 美團(Leaf)實戰
整理了一些Java方面的架構、面試資料(微服務、叢集、分散式、中介軟體等),有需要的小夥伴可以關注公眾號【程式設計師內點事】,無套路自行領取 更多優選 一口氣說出 9種 分散式ID生成方式,面試官有點懵了 面試總被問分庫分表怎麼辦?你可以這樣懟他 3萬字總結,Mysql優化之精髓 為了不復制貼上,我被逼
美團分散式ID生成框架Leaf原始碼分析及優化改進
最近做了一個面試題解答的開源專案,大家可以看一看,如果對大家有幫助,希望大家幫忙給一個star,謝謝大家了! 《面試指北》專案地址:https://github.com/NotFound9/interviewGuide  它是基於當前時間微秒數的 用法如下: echo uniqid(); //13位的字串 echo uniqid("php_"); //當然你可以加上字首 echo uniqid("php_", TRUE); //如果第二個引數more_entro
生成資料庫自增不重複ID的方法
namespace ConsoleApp1 { class Program { static void Main(string[] args) { var list = new HashSet<string>(101);
分散式全域性id生成原始碼
package com.jd.medicine.base.common.global.id; import com.jd.jim.cli.Cluster; import com.jd.medicine.base.common.logging.LogUtil; import com.jd.m