
圖解Janusgraph系列-分散式id生成策略分析
阿新 • • 發佈:2020-09-01
# JanusGraph - 分散式id的生成策略
大家好,我是洋仔,JanusGraph圖解系列文章,`實時更新`~
>本次更新時間:2020-9-1
>文章為作者跟蹤原始碼和檢視官方文件整理,如有任何問題,請聯絡我或在評論區指出,感激不盡!
**`圖資料庫網上資源太少,評論區評論 or 私信我,邀你加入“相簿交流微信群”,一起交流學習!`**
**原始碼分析相關:**
[原始碼相簿-一文搞定janusgraph圖資料庫的本地原始碼編譯(janusgraph source code compile)](https://liyangyang.blog.csdn.net/article/details/106674499)
圖解相簿JanusGraph系列-一文知曉匯入資料流程(待發布)
圖解相簿JanusGraph系列-簡要分析查詢讀資料流程(待發布)
圖解相簿JanusGraph系列-一文知曉鎖機制(本地鎖+分散式鎖)(待發布)
[圖解相簿JanusGraph系列-一文知曉分散式id生成策略](https://mp.weixin.qq.com/s?__biz=MzAwODkwMDk4OQ==&mid=2247483936&idx=1&sn=1b0ebe5699ee267d4b0360c90c937492&chksm=9b669a32ac111324e66af490a24478b81ad5221a88af61897353a6f4d80ff6005b60fbbb8490&scene=126&sessionid=1598925790&key=4598b5ee8f6c495005e73b5167cd30412733226c9d6ce3657d87cabb5291569908596536a55cce3dd7a6aea5825a3376ea9164400735c8294ba829b5fe929c554a15390fbc2cde275c4a553c77f55ee95eda0ccbc57348e1982181a8d10974962f967b290f0cfd7665a5c03e4c9637ce95166cf387b34bbb11239469172c253b&ascene=1&uin=MjMwNTU3MjU4MQ%3D%3D&devicetype=Windows+10+x64&version=62090529&lang=zh_CN&exportkey=AU6RYjWx80jN1DKuoVRSczA%3D&pass_ticket=tfgSbQAaIYvDoARCTj0WD5fc96MDzkEkABiBJf%2FX0t532Z7kIWU5Z3x5qVTyNpkY)
圖解相簿JanusGraph系列-一文知曉相簿儲存分割槽策略(待發布)
**儲存結構相關:**
[圖解相簿JanusGraph系列-一文知曉圖資料底層儲存結構](https://mp.weixin.qq.com/s?__biz=MzAwODkwMDk4OQ==&mid=2247483894&idx=1&sn=0d7b98d8d7abf86bfacf8c86b694651d&chksm=9b6699e4ac1110f2626789d78aaf617dc02b7a9cdad320c5273172a6fa3a21d8f40d63958461&token=2053731774&lang=zh_CN#rd)
**其他:**
[解惑圖資料庫!你知道什麼是圖資料庫嗎?](https://mp.weixin.qq.com/s?__biz=MzAwODkwMDk4OQ==&mid=2247483830&idx=1&sn=71ad0d9e0d5868ae15011b7744c0fe8f&chksm=9b6699a4ac1110b294487a6987be5392a5093405a7a40f58d4bca697a18d64000db1aeda0a6f&token=1631136587&lang=zh_CN#rd)
圖解相簿JanusGraph系列-官方測試圖:諸神之圖分析(待發布)
> **`原始碼分析相關可檢視github(求star~~)`**: [https://github.com/YYDreamer/janusgraph](https://github.com/YYDreamer/janusgraph)
> 下述流程高清大圖地址:[https://www.processon.com/view/link/5f471b2e7d9c086b9903b629](https://www.processon.com/view/link/5f471b2e7d9c086b9903b629)
> 版本:JanusGraph-0.5.2
**轉載文章請保留以下宣告:**
>作者:洋仔聊程式設計
>微信公眾號:匠心Java
## 正文
在介紹JanusGraph的分散式ID生成策略之前,我們來簡單分析一下`分散式ID`應該滿足哪些特徵?
* **全域性唯一**:必須保證ID是分散式環境中全域性性唯一的,這是基本要求
* **高效能**:高可用低延時,ID生成響應快;否則可能會成為業務瓶頸
* **高可用**:提供分散式id的生成的服務要保證高可用,不能隨隨便便就掛掉了,會對業務產生影響
* **趨勢遞增**:主要看業務場景,類似於圖儲存中節點的唯一id就儘量保持趨勢遞增;但是如果類似於電商訂單就儘量不要趨勢遞增,因為趨勢遞增會被惡意估算出當天的訂單量和成交量,洩漏公司資訊
* **接入方便**:如果是中介軟體,要秉著拿來即用的設計原則,在系統設計和實現上要儘可能的簡單
## 一:常用分散式id生成策略
當前`常用的`分散式id的生成策略主要分為以下四種:
* UUID
* 資料庫+號段模式(優化:資料庫+號段+雙buffer)
* 基於Redis實現
* 雪花演算法(SnowFlake)
還有一些其他的比如:基於資料庫自增id、資料庫多主模式等,這些在小併發的情況下可以使用,大併發的情況下就不太ok了
市面上有一些生成分散式id的開源元件,包括滴滴基於`資料庫+號段`實現的`TinyID` 、百度基於`SnowFlake`的`Uidgenerator`、美團支援`號段`和`SnowFlake`的`Leaf`等
那麼,在JanusGraph中分散式id的生成是採用的什麼方式呢?
## 二:JanusGraph的分散式id策略
在JanusGraph中,分散式id的生成採用的是`資料庫+號段+雙buffer優化`的模式; 下面我們來具體分析一下:
分散式id生成使用的資料庫就是JanusGraph當前使用的第三方儲存後端,這裡我們以使用的儲存後端`Hbase`為例;
**JanusGraph分散式id生成所需元資料儲存位置:**
在Hbase中有`column family 列族`的概念; JanusGraph在初始化Hbase表時預設建立了9大列族,用於儲存不同的資料, 具體看《圖解相簿JanusGraph系列-一文知曉圖資料底層儲存結構》;
其中有一個列族`janusgraph_ids`簡寫為`i`這個列族,主要儲存的就是JanusGraph分散式id生成所需要的元資料!
**JanusGraph的分散式id的組成結構:**
```java
// 原始碼中有一句話體現
/* --- JanusGraphElement id bit format ---
* [ 0 | count | partition | ID padding (if any) ]
*/
```
主要分為4部分:`0、count、partition、ID padding(每個型別是固定值)`;
其實這4部分的順序在序列化為二進位制資料時,順序會有所改變;這裡只是標明瞭id的組成部分!
上述部分的`partition` + `count`來保證分散式節點的唯一性;
* partition id:分割槽id值,JanusGraph預設分了32個邏輯分割槽;節點分到哪個分割槽採用的是`隨機分配`;
* count:每個partition都有對應的一個count範圍:0-2的55次冪;JanusGraph每次拉取一部分的範圍作為節點的count取值;JanusGraph保證了針對相同的partition,不會重複獲取同一個count值!
保證count在partition維度保持全域性唯一性,就保證了生成的最終id的全域性唯一性!!
*則分散式id的唯一性保證,就在於`count`基於`partition`維度的唯一性!下面我們的分析也是著重在`count`的獲取!*
**JanusGraph分散式id生成的主要邏輯流程如下圖所示:(推薦結合原始碼分析觀看!)**
> 分析過程中有一個概念為`id block`:指當前獲取的號段範圍
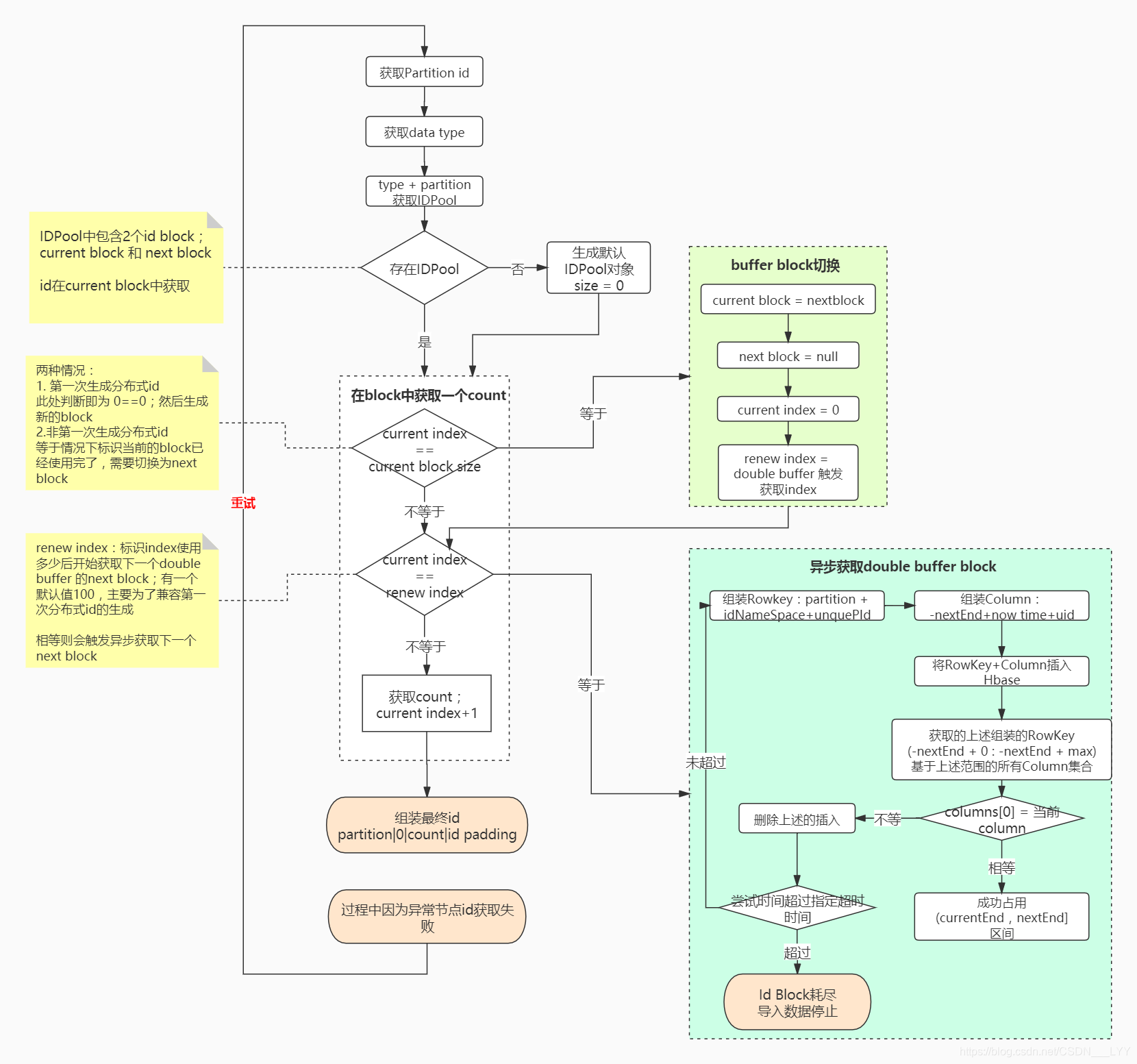
JanusGraph主要使用``PartitionIDPool `類來儲存不同型別的`StandardIDPool`; 在`StandardIDPool`中主要包含兩個id Block:
* current block:當前生成id使用的block
* next block:double buffer中的另一個已經準備好的block
**為什麼要有兩個block呢?**
主要是如果只有一個block的話,當我們在使用完當前的block時,需要阻塞等待區獲取下一個block,這樣便會導致分散式id生成較長時間的阻塞等待block的獲取;
怎麼優化上述問題呢? `double buffer`;
除了當前使用的block,我們再儲存一個`next block`;當正在使用的block假設已經使用了50%,觸發`next block`的非同步獲取,如上圖的藍色部分所示;
這樣當`current block`使用完成後可以直接無延遲的切換到`next block`如上圖中綠色部分所示;
**在執行過程中可能會因為一些異常導致節點id獲取失敗,則會進行重試;重試次數預設為1000次;**
```java
private static final int MAX_PARTITION_RENEW_ATTEMPTS = 1000;
for (int attempt = 0; attempt < MAX_PARTITION_RENEW_ATTEMPTS; attempt++) {
// 獲取id的過程
}
```
> ps:上述所說的IDPool和block是基於當前`圖例項`維度共用的!
## 三:原始碼分析
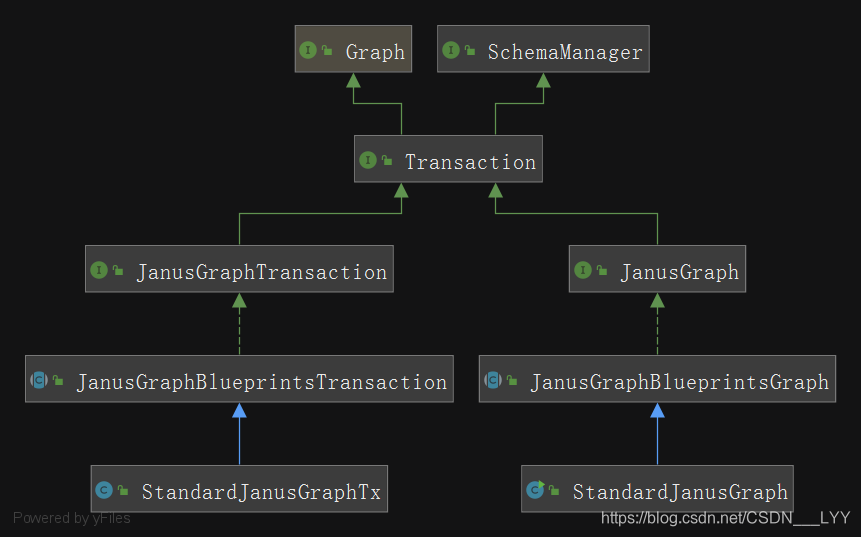
在JanusGraph的原始碼中,主要包含兩大部分和其他的一些元件:
* Graph相關類:用於對節點、屬性、邊的操作
* Transaction相關類:用於在對資料或者Schema進行CURD時,進行事務處理
* 其他一些:分散式節點id生成類;序列化類;第三方索引操作類等等
Graph和Transaction相關類的類圖如下所示:
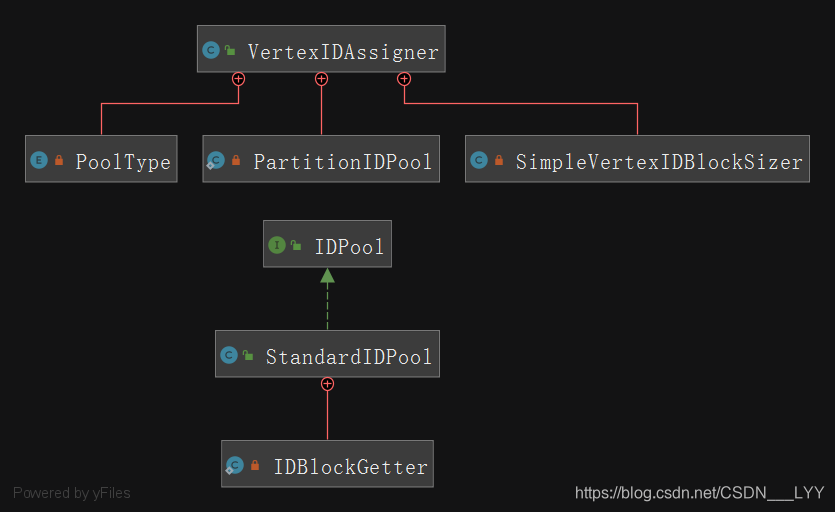
分散式id涉及到id生成的類圖如下所示:
**初始資料:**
```java
@Test
public void addVertexTest(){