
(有解題思路)機器學習coursera吳恩達第六週最後測驗習題彙總
第六週的習題做了三遍才100%正確,其中還是參照了不少論壇裡大神的答案(比如BeiErGeLaiDe的部落格,連結點選開啟連結)
正式進入主題:ML第六週最後測驗,共五題。文中大部分屬於個人觀點,如有錯誤歡迎指正、交流。
1. You are working on a spam classification system using regularized logistic regression. "Spam" is a positive class (y = 1) and "not spam" is the negative class (y = 0). You have trained your classifier and there are m = 1000 examples in the cross-validation set. The chart of predicted class vs. actual class is:
| Actual Class: 1 | Actual Class: 0 | |
| Predicted Class: 1 | 85 | 890 |
| Predicted Class: 0 | 15 | 10 |
For reference:
· Accuracy = (true positives + true negatives) / (total examples)
· Precision = (true positives) / (true positives + false positives)
· Recall = (true positives) / (true positives + false negatives)
·
What is the classifier's accuracy (as avalue from 0 to 1)?
Enter your answer in the box below. If necessary, provide at least two values after the decimal point.
答:第一題我抽到的三次都不一樣,反正是把精度Accuraccy、查準率precision、查全率recall全算了一遍,算是基礎題目。
精度Accuraccy = ( 85+10)/1000 = 0.095;
recall = 85 / (85+15) = 0.85
precision = 85/(85+890) = 0.087
F1 = 2*0.085*0.087/(0.087+0.85)=0.16(題意,精確到小數點後兩位)2. Suppose a massive dataset is available for training a learning algorithm. Training on a lot of data is likely to give good performance when two of the following conditions hold true.
Which are the two?
Our learning algorithm is able to represent fairly complex functions (for example, if we train a neural network or other model with a large number of parameters).
A human expert on the application domain can confidently predict y when given only the features x (or more generally, if we have some way to be confident that x contains sufficient information to predict y accurately).
When we are willing to include high order polynomial features of x (such as x21, x22, x1x2, etc.).
The classes are not too skewed.
答:A,我們的學習演算法能夠表示相當複雜的功能(例如,如果我們訓練神經網路或其他具有大量引數的模型)。模型複雜,表示複雜的函式,此時的特徵多項式可能比較多,能夠很好的擬合訓練集中的資料,使用大量的資料能夠很好的訓練模型。
B:當只給出特徵x(或者更一般來說,如果我們有辦法可以確信x包含足夠的資訊來準確預測y),在應用型領域的專家可以相當準確地預測y。 資料的有效性,使資料本身有一定規律可循。
3. Suppose you have trained a logistic regression classifier which is outputing hθ(x).
Currently, you predict 1 if hθ(x)≥threshold, and predict 0 if hθ(x)<threshold, where currently the threshold is set to 0.5.
Suppose you decrease the threshold to 0.1. Which of the following are true? Check all that apply.
The classifier is likely to have unchanged precision and recall, and thus thesame F1 score.
The classifier is likely to have unchanged precision and recall, but higher accuracy.
The classifier is likely to now have lower recall.
The classifier is likely to now have lower precision.

答:選第四個。這題還有一個版本是將閾值threshould提升到0.9的,答案和這個這個0.7的是一樣的。
首先閾值的設定並不會影響查全率recall和查準率precision,recall和precision是此消彼長的一個過程,吳恩達老師課程裡講到的那個圖可以幫助理解這個題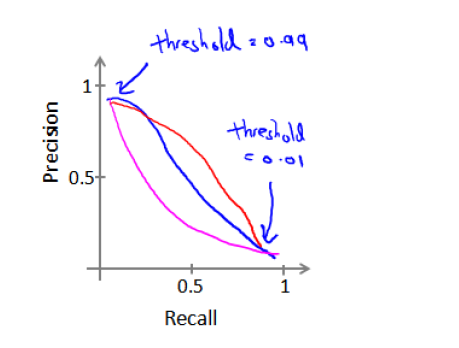
4. Suppose you are working on a spam classifier, where spam emails are positive examples (y=1) and non-spam emails are negative examples (y=0). You have a training set of emails in which 99% of the emails are non-spam and the other 1% is spam. Which of the following statements are true? Check all that apply.
If you always predict non-spam (output y=0), your classifier will have 99% accuracy on the trainingset, but it will do much worse on the cross validation set because it has overfit the training data.
A good classifier should have both a high precision and high recall on the cross validation set.
If you always predict non-spam (output y=0), your classifier will have 99% accuracy on the training set, and it will likely perform similarly on the cross validation set.
If you always predict non-spam (output y=0), your classifier will have an accuracy of 99%.
5. Which of the following statements are true? Check all that apply.
The"error analysis" process of manually examining the examples whichyour algorithm got wrong can help suggest what are good steps to take (e.g., developing new features) to improve your algorithm's performance.
Itis a good idea to spend a lot of time collecting a large amount of data before building your first version of a learning algorithm.
If your model is underfitting the training set, then obtaining more data is likely to help.
After training a logistic regression classifier, you must use 0.5 as your threshold for predicting whether an example is positive or negative.
Using a very large training set makes it unlikely for model to overfit the training data.
答:選A、E。
手動檢查你的演算法出錯的例子如“錯誤分析”過程可以幫助建議採取什麼好辦法(例如,開發新功能)來改進演算法的效能。
使用非常大的訓練集使模型不太可能過擬合訓練資料。
這題答案主要參考以上劉亞龍大神的解析,
注:誤差分析計算可以得出各因素對模型效能的影響,可以通過這種計算的方法判斷如何改進模型效能,所以A正確;B錯,資料還要保證方便符合模型和計算,最重要的是要有一定的潛在規律可循,多而不亂,即找大量有用的資料,而不僅僅是大量資料;C裡面已經是underfitting了,可能為模型太簡單,特徵太少(比如用來擬合數據僅僅只是一次線性函式,那肯定不行,再多的資料也無法正確擬合,此時應該做的是嘗試增加更多的多項式特徵)或者課上提到的資料太多(或者說資料太雜);D裡面must use不對,考慮到Skewed Data,不一定最終把threshold設為0.5;E很明顯正確,可以參照課上overfitting和underfitting的定義;
結束
附:測驗長截圖
