
Scikit-Learn 與 TensorFlow 機器學習實用指南學習筆記2 — 機器學習的主要挑戰

紅色石頭的個人網站:redstonewill.com
簡而言之,因為機器學習的主要任務就是選擇合適的機器學習演算法在資料集上進行訓練,所以不好的演算法和不好的資料都可能嚴重影響訓練效果。下面我們先來看看不好的資料會帶來什麼影響。
1.4.1 訓練資料不足
對一個蹣跚學步的孩子來說,如何識別蘋果?方法是拿出很多各種各樣顏色、形狀的蘋果圖片給他看,教他。這樣,孩子就能夠更好地識別出各種蘋果。
而對機器學習來說還達不到這種程度,大多數機器學習演算法都需要很多資料才能有不錯的表現。即使是簡單的演算法可能也需要上千個訓練樣本。對於複雜的機器學習問題,例如影象識別、語音處理,需要的訓練樣本就更多了,甚至是百萬級別的(除非你基於已有的模型進行再次訓練,類似於遷移學習,所需的樣本可能不多)。
資料的不合理有效性
在 2001 年發表的著名文章裡,微軟研究員 Michele Banko 和 Eric Brill 展示了不同的機器學習演算法在一個較複雜的自然語言消歧問題上的表現情況,他們發現一旦有足夠多的訓練資料,各演算法的表現都基本一致(如下圖所示)。
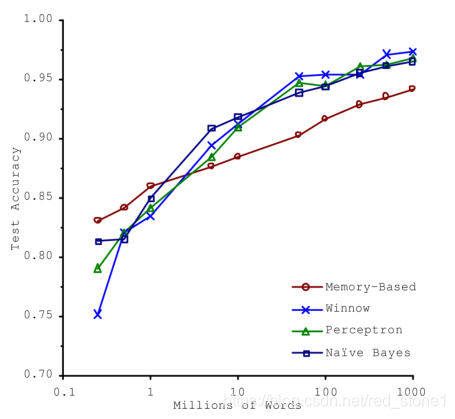
正如作者所說:“這個結果表明我們可能需要重新考慮是花費時間、金錢在演算法研究上還是在擴充語料庫上。”
對於複雜問題,資料比演算法更加重要這一思想在 Peter Norving 等人於 2009 年釋出的文章《The Unreasonable Effectiveness of Data》中得到進一步的推廣。值得注意的是,小型和中等數量的資料集仍然非常常見,而且想要獲得大量的訓練資料通常並不是一件簡單的事情,所以還不能拋棄演算法。
1.4.2 沒有代表性的訓練資料
為了讓模型有更好的泛化能力,很重要的一點是你的訓練資料應該有很好的代表性,無論你使用的是基於例項學習還是基於模型學習。
例如,之前我們訓練線性模型選擇的一些國家並不具有很好的代表性,缺少了一些國家。下圖展示了增加這些國家之後的資料分佈和線性模型。
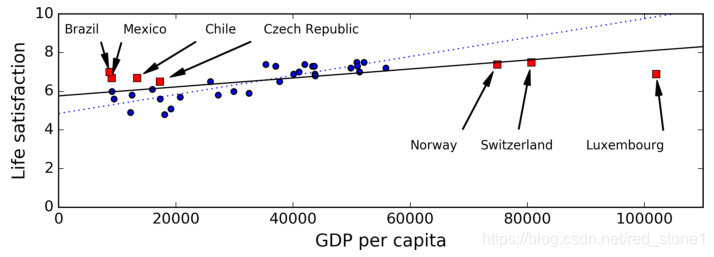
如果你在這些完整的資料上訓練線性模型,得到的黑色實線;原來的線性模型是藍色虛線。如你所見,新增幾個缺失的國家後不僅顯著地改變了模型,而且清楚地表明,這種簡單的線性模型可能永遠都不會有很好的效能。看起來,非常富裕的國家並不比中等富裕國家幸福(事實上,他們似乎更不幸福),相反,一些窮國似乎比許多富裕國家更加幸福。
如果使用沒有代表性的資料進行訓練,模型不可能得到準確的預測,特別是那些非常貧困和非常富有的國家。
使用有代表性的訓練資料是非常重要的。但這通常比較困難,如果樣本太少,容易引入取樣噪聲(即非代表性的資料);即使是很多樣本,如果取樣方法有缺陷,也可能得到不好的資料,這被稱為取樣偏差(sampling bias)。
一個著名的取樣偏差例子
或許最有名的取樣偏差例子發生在 1936 年的美國大選,林軒田課程中也提到過這個例子。當時的候選人是 Landon 和 Roosevelt,《Literary Digest》做了一次很大的民意調查,給 10,000,000 選民傳送郵件徵集選民意向,總共收到了 2,400,000 的反饋結果。調查報告顯示 Landon 的支援率是 57%,但是最終選舉投票 Roosevelt 得到了 62% 的選票贏了 Landon。差別如此之大的原因在於《Literary Digest》的民意調查取樣方法有缺陷:
-
首先,《Literary Digest》傳送郵件的選民大部分都是美國富人,而這些富人支援共和黨(即 Landon)的較多。
-
其次,只有不到 25% 的人反饋了民意調查。這同樣引入了取樣偏差,排除了那些對選舉不關心的,或者不喜歡《Literary Digest》的,或者是其他關鍵組織。這種取樣偏差被稱為無應答偏差(nonreponse bias)。
還有一個例子,假如你想構建一個系統來識別 funk 音樂視訊。得到訓練集的方法之一就是在 YouTube 上搜索 “funk music”,得到的視訊作為訓練集,但這是假設 YouTube 搜尋引擎返回的是所有具有代表性的 funk music。事實上,搜尋結果可能偏向於推薦某些有名的音樂家(跟你的所在地、平時喜好都有關係)。
1.4.3 低質量資料
顯然,如果訓練資料都是錯誤、離群點和噪聲(例如,由於質量不佳的測量),想要得到一個性能較好的模型是非常困難的。因此,花費時間清洗訓練資料是十分必要的,這也是資料科學家們非常重視的。常用的方法如下:
-
對於離群點,通常的辦法是剔除這個例項或者手動修正這個錯誤。
-
對於有特徵缺失值的情況,可以選擇刪除這個特徵,或者刪除缺失特徵的例項樣本,或者填充缺失值(中值或平均值),或者分別訓練包含該特徵和不包含該特徵的兩個模型對比效果等方法。
1.4.4 不相關特徵
俗話說:種瓜得瓜,種豆得豆。如果訓練資料包含了足夠的相關特徵,沒有太多的不相關特徵,模型就有能力學習。機器學習如此強大的一個重要原因就是提取一些重要的特徵來訓練。提取特徵並處理的過程我們稱之為特徵工程,具體包含以下幾個方面:
-
特徵選擇:從所有特徵中選擇最有用的特徵供模型來訓練。
-
特徵提取:結合已有的特徵產生更有用的特徵(例如降維技術)。
-
通過收集新資料建立新特徵。
以上就是一些不好的資料型別,接下來我們將介紹有哪些不好的演算法。
1.4.5 過擬合
舉個形象的例子,比如你去某個國家旅遊搭乘計程車,半路上司機把你丟在路邊,你可能會說這個國家的計程車司機都是壞蛋!這種過度概括的行為是人類經常做的。同樣不幸的是,機器有時候也會出現類似的情況,機器學習裡稱之為過擬合:表示模型在訓練資料上表現的很好,但是在其它樣本上表現得卻不好,泛化能力差。
下圖展示了使用高階多項式模型來擬合生活滿意度與人均 GDP 的關係。儘管在訓練資料上該高階模型表現比簡單的線性模型好得多,但是你真的相信這是一個很好的模型嗎?
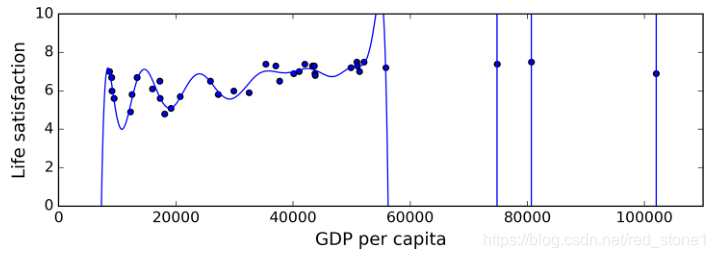
諸如深層神經網路這種複雜模型可以檢測出資料中的細微模式,但是如果訓練集包含噪聲,或者樣本不多(帶來取樣噪聲),模型很可能會檢測到噪聲本身的模式。很明顯這些模式無法很好地泛化到其它樣本中。例如,生活滿意度模型中,採用國家名稱這一屬性作為特徵之一,發現所有訓練樣本中國家名稱包含字母 w 的生活指數都大於 7:New Zealand (7.3), Norway (7.4), Sweden (7.2), Switzerland (7.5)。這種結論你覺得能歸納到訓練樣本以外的其它樣本嗎?例如 Rwanda、Zimbabwe?顯然是不行的,這一模式只是偶然發生在訓練資料中,但是模型本身沒有辦法判斷一個模式是真實反映資料內在特徵的還是資料中噪聲造成的。
當模型過於複雜時,容易發生過擬合,常用的解決方法是:
-
選擇少量的引數作為特徵,簡化模型(例如使用線性模型而不是高階模型)。
-
獲取更多的訓練資料
-
減少訓練資料中的噪聲(例如修復資料中的錯誤,移除離群點)。
限制模型複雜度,讓它變得簡單,減少過擬合風險的做法稱之為正則化(regularization)。例如,我們之前定義的線性模型包含兩個引數 和 。這給了學習演算法兩個自由度來讓模型適應訓練資料:可以除錯直線的截距 和斜率 。如果令 ,則演算法只有一個自由度,很難較好地擬合數據:可以做的僅僅是把這條水平線上下移動,儘量接近訓練樣本,最終停留在所有訓練樣本的均值位置。這確實是一個非常簡單的模型!如果 ,但值很小,學習演算法有效的自由度在一和二之間,它比兩個自由度模型簡單,比一個自由度模型複雜。其實,你的目標就是在完美擬合數據和簡化模型之間找到平衡,使模型具有較好的泛化能力。
下圖展示了三種模型:藍色點線表示原始的線性模型,缺少一些國家的資料;紅色短劃線表示第二個線性模型,使用了所有國家的資料訓練得到的;藍色實線表示的模型與第一個類似,只是使用了正則化限制。可以看出正則化使得模型的斜率變小,對訓練資料的擬合效果比第一種差一些,但是對新樣本的擬合效果比第一種更好,泛化能力變強了。
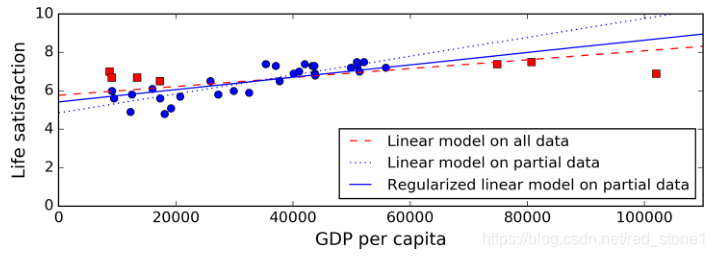
正則化的程度由超引數控制。超引數是演算法的引數(不是模型的引數),不受演算法本身的影響。超引數在訓練模型之前就設定好,整個訓練過程中保持不變。如果將超引數設定很大的值,將會得到一個近似平坦的模型(斜率接近 0 )。這時候不太可能出現過擬合,但是模型過於簡單,對資料的擬合效果很差。這種情況叫做欠擬合,它和過擬合是兩個對立的概念。除錯超引數是構建機器學習系統過程中非常重要的一步,下一章節我們想詳細介紹。
1.4.6 欠擬合
正如上文所說,欠擬合是與過擬合對立的概念:它發生在模型過於簡單以至於不能很好地擬合數據的時候。例如,生活滿意度的線性模型就可能存在欠擬合,實際的模型可能要比線性模型更加複雜。因此,線性模型即便是對訓練樣本也會預測得不夠準確。
解決欠擬合得主要方法有:
-
選擇更加強大得模型,帶有更多引數。
-
增加更好得特徵到學習演算法中(特徵工程)。
-
減小對模型的限制(例如減小正則化超引數)。
1.4.7 回顧
到目前為止,我們已經學習了很多機器學習概念知識,下面做個簡單回顧:
-
機器學習就是讓機器能夠從資料中學習,在某些任務中做得更好,而不是簡單地執行固定的程式。
-
機器學習型別有很多:監督式和非監督式,批量學習和線上學習,基於例項學習和基於模型學習等。
-
在一個機器學習工程中,我們收集資料作為訓練集,使用學習演算法在訓練集上進行訓練。如果演算法是基於模型的,得到最佳的模型引數,使模型能夠擬合訓練集,並且對訓練集之外的樣本也能有較好的擬合效果。如果演算法是基於例項的,學習過程就是簡單的記憶,並使用相似性測量來歸納到新的樣本中。
-
以下因素可能造成系統表現不好:訓練集樣本太少,資料不具有代表性,資料有噪聲,受到不相關特徵的汙染。最後,模型不能過於簡單(欠擬合),也不能過於複雜(過擬合)。
還有一點需要討論:一旦訓練了一個模型,不能僅僅是“希望”它的泛化能力好,我們還要去評估這個模型,必要的時候除錯模型。下面就來介紹怎麼去除錯模型。
1.5 測試和驗證
評估模型好壞的唯一方法就是測試模型在新樣本中的表現。一種做法是把模型直接放到生產中實際檢測其表現。但如果模型效能不佳,會讓使用者抱怨吐槽——因此,這並不是一個好方法。
一種更好的做法是把資料集劃分成兩部分:訓練集和測試集。顧名思義,訓練集用來訓練模型,測試集用來評估模型。模型在新樣本下的錯誤率被稱為泛化誤差(又叫樣本外誤差,out-of-sample error)。模型在測試集上評估模型,得到的誤差可以近似認為就是模型的泛化誤差。一般使用整個資料集的 80% 作為訓練集,20% 作為測試集。
如果模型的訓練誤差(模型在訓練集上的誤差)很小,而泛化誤差很大,則說明模型很可能發生了過擬合。
這下,評估模型變得簡單了:使用測試集即可。如果有兩個模型(一個線性模型,一個多項式模型),如何決定哪個模型更好呢?方法就是直接訓練兩個模型,然後比較它們在測試集上的泛化誤差大小就可以了。
還有一個問題,如何選擇最佳的正則化超引數呢?一種方法就是分別使用不同的超引數訓練模型,然後比較各個超引數對應模型的泛化誤差(泛化誤差在測試集上得到),對應泛化誤差最小(例如 5%)的超引數即為最佳值。
然後,將模型上線釋出,但不幸的是模型表現卻並不像測試時那麼好,實際誤差達到了 15%。這又是為什麼呢?
問題在於我們是在同一測試集上多次測量泛化誤差的,這樣產生的最佳模型是適應測試集的,可能造成模型在測試集之外新的樣本上表現得不太好。
解決這一問題通常的做法是除了設定訓練集、測試集之外,還設定一個驗證集。同樣使用訓練集來訓練不同超引數的模型,每個模型在驗證集上進行驗證,選擇表現最好的超引數對應的模型,最後該模型在測試集上進行測試得到的誤差為最終的泛化誤差。
為了避免驗證集佔用過多的訓練樣本,造成浪費,通常使用交叉驗證(cross-validation):將整個訓練集劃分為 N 份,取其中的 N-1 份作為訓練集,另外的 1 份作為驗證集,重複 N 次。然後將 N 次的驗證誤差求平均作為驗證誤差。一旦模型和超引數選定之後,使用該模型和超引數,在整個訓練集上進行訓練。最後,在測試集上測試得到泛化誤差。
無免費午餐定理
模型是樣本觀測的一種簡化。簡化意味著丟棄一些多餘的不具備泛化能力的細節。然而,決定哪些資料保留,哪些資料拋棄,我們必須做出假設。例如,一個線性模型假設資料是呈線性關係的,例項與直線之間的距離僅僅是噪聲,是可以忽略的。
在 1996 年的一篇著名論文中,David Wolpert 證明了如果對資料不作任何假設,選擇一個模型而不選擇其它模型是沒有理由的。這被稱為無免費午餐(NFL)定理。對某些資料集來說,最好的模型是線性模型,而對於另外某些資料集來說,最好的模型可能是神經網路。沒有哪個模型一定是最好的(正如這個定理的名字那樣)。確定哪個模型最好的唯一方法就是對所有的模型進行評估,但是這顯然不太可能。實際上我們通常會對資料作出某些合理的假設,僅僅評估一些合理的模型。例如,我們可能設定不同的正則化引數來評估線性模型;對於更復雜的問題,可能評估不同的神經網路模型。
專案地址:
https://github.com/RedstoneWill/Hands-On-Machine-Learning-with-Sklearn-TensorFlow
