
命名實體識別(NER)的發展歷程
命名實體識別(Named Entity Recognition,NER)簡單說就是從一段自然語言文字中找出相關實體,並標註出其位置以及型別。一般我們歸為序列標註問題(sequence labeling problem)中的一種。與分類問題相比,序列標註問題中當前的預測標籤不僅與當前的輸入特徵相關,還與之前的預測標籤相關,即預測標籤序列之間是有強相互依賴關係的。例如,使用BIO標籤進行NER時,正確的標籤序列中標籤O後面是不會接標籤I的。

NER的發展從早期基於詞典和規則的方法,到傳統機器學習的方法,到近年來基於深度學習的方法,大致如下。
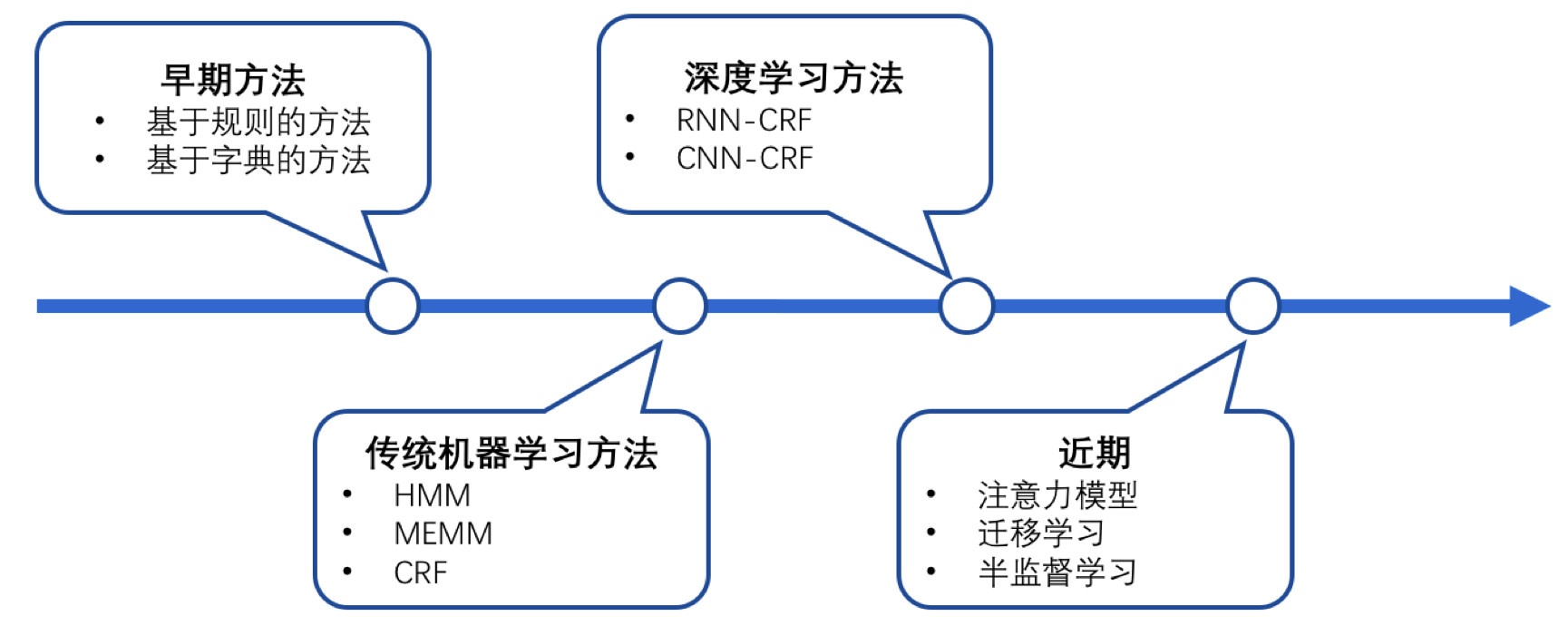
在傳統機器學習中,CRF(條件隨機場)是NER目前的主流模型。它的目標函式不僅考慮輸入的狀態特徵函式,而且還包含了標籤轉移特徵函式。在訓練時可以使用SGD學習模型引數。在已知模型時,給輸入序列求預測輸出序列即求使目標函式最大化的最優序列,是一個動態規劃問題,可以使用維特比演算法進行解碼。CRF的優點在於其為一個位置進行標註的過程中可以利用豐富的內部及上下文特徵資訊。

在傳統機器學習方法中,常用的特徵如下:

近年來,隨著算力的發展以及詞的分散式表示(word embedding)的提出,神經網路可以有效處理許多NLP任務。這類方法對於序列標註任務(如CWS、POS、NER)的處理方式是類似的:將token從離散one-hot表示對映到低維空間中成為稠密的embedding,隨後將句子的embedding序列輸入到RNN中,用神經網路自動提取特徵,Softmax來預測每個token的標籤。
這種方法使得模型的訓練成為一個端到端的過程,而非傳統的pipeline,不依賴於特徵工程,但神經網路種類繁多、對引數設定依賴大,模型可解釋性差。此外,這種方法的一個缺點是對每個token打標籤的過程是獨立的進行,不能直接利用上文已經預測的標籤(只能靠隱含狀態傳遞上文資訊),進而導致預測出的標籤序列可能是無效的,例如標籤I-PER後面是不可能緊跟著B-PER的,但Softmax不會利用到這個資訊。所以進一步提出DL-CRF模型做序列標註。在神經網路的輸出層接入CRF層(重點是利用標籤轉移概率)來做句子級別的標籤預測,使得標註過程不再是對各個token獨立分類。
2 NER中的神經網路結構
2.1 NN/CNN-CRF模型
《Natural language processing (almost) from scratch》是較早使用神經網路進行NER的代表工作之一。在這篇論文中,作者提出了視窗方法與句子方法兩種網路結構來進行NER。這兩種結構的主要區別就在於視窗方法僅使用當前預測詞的上下文視窗進行輸入,然後使用傳統的NN結構;而句子方法是以整個句子作為當前預測詞的輸入,加入了句子中相對位置特徵來區分句子中的每個詞,然後使用了一層卷積神經網路CNN結構。

在訓練階段,作者也給出了兩種目標函式:一種是詞級別的對數似然,即使用softmax來預測標籤概率,當成是一個傳統分類問題;另一種是句子級別的對數似然,其實就是考慮到CRF模型在序列標註問題中的優勢,將標籤轉移得分加入到了目標函式中。後來許多相關工作把這個思想稱為結合了一層CRF層,所以我這裡稱為NN/CNN-CRF模型。

在作者的實驗中,上述提到的NN和CNN結構效果基本一致,但是句子級別似然函式即加入CRF層在NER的效果上有明顯提高。
2.2 RNN-CRF模型
借鑑上面的CRF思路,出現了一系列使用RNN結構並結合CRF層進行NER的工作。模型結構如下圖:

它主要有Embedding層(主要有詞向量,字元向量以及一些額外特徵),雙向RNN層,tanh隱層以及最後的CRF層構成。它與之前NN/CNN-CRF的主要區別就是他使用的是雙向RNN代替了NN/CNN。這裡RNN常用LSTM或者GRU。實驗結果表明RNN-CRF獲得了更好的效果,已經達到或者超過了基於豐富特徵的CRF模型,成為目前基於深度學習的NER方法中的最主流模型。在特徵方面,該模型繼承了深度學習方法的優勢,無需特徵工程,使用詞向量以及字元向量就可以達到很好的效果,如果有高質量的詞典特徵,能夠進一步獲得提高。
3 最近的一些工作
近年在基於神經網路結構的NER研究上,主要集中在兩個方面:一是使用流行的注意力機制來提高模型效果(Attention Mechanism),二是針對少量標註訓練資料或無標註資料進行的一些研究。
3.1 Attention-based
《Attending to Characters in Neural Sequence Labeling Models》該論文還是在RNN-CRF模型結構基礎上,重點改進了詞向量與字元向量的拼接。使用attention機制將原始的字元向量和詞向量拼接改進為了權重求和,使用兩層傳統神經網路隱層來學習attention的權值,這樣就使得模型可以動態地利用詞向量和字元向量資訊。實驗結果表明比原始的拼接方法效果更好。

另一篇論文《Phonologically aware neural model for named entity recognition in low resource transfer settings》,在原始BiLSTM-CRF模型上,加入了音韻特徵,並在字元向量上使用attention機制來學習關注更有效的字元,主要改進如下圖。

3.2 少量標註資料
對於深度學習方法,一般需要大量標註資料,但是在一些領域並沒有海量的標註資料。所以在基於神經網路結構方法中如何使用少量標註資料進行NER也是最近研究的重點。其中包括了遷移學習《Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks》和半監督學習。這裡我提一下最近ACL2017剛錄用的一篇論文《Semi-supervised sequence tagging with bidirectional language models》。該論文使用海量無標註語料庫訓練了一個雙向神經網路語言模型,然後使用這個訓練好的語言模型來獲取當前要標註詞的語言模型向量(LM embedding),然後將該向量作為特徵加入到原始的雙向RNN-CRF模型中。實驗結果表明,在少量標註資料上,加入這個語言模型向量能夠大幅度提高NER效果,即使在大量的標註訓練資料上,加入這個語言模型向量仍能提供原始RNN-CRF模型的效果。整體模型結構如下圖:

4 總結
最後進行一下總結,目前將神經網路與CRF模型相結合的NN/CNN/RNN-CRF模型成為了目前NER的主流模型。我認為對於CNN與RNN,並沒有誰佔據絕對的優勢,各自有相應的優點。由於RNN有天然的序列結構,所以RNN-CRF使用更為廣泛。基於神經網路結構的NER方法,繼承了深度學習方法的優點,無需大量人工特徵。只需詞向量和字元向量就能達到主流水平,加入高質量的詞典特徵能夠進一步提升效果。對於少量標註訓練集問題,遷移學習,半監督/無監督學習應該是未來研究的重點。
參考文章
http://www.cnblogs.com/robert-dlut/p/6847401.html
https://my.oschina.net/datagrand/blog/2251431