
深度神經網路之正則化
1.正則化
之前介紹的文章之中,我們已多次接觸到正則化方法,但沒有詳細的解釋為什麼要正則化,什麼是正則化,以及L1正則化和L2正則化的區別。本次文章之中,我們將詳解機器學習中正則化的概念和深度神經網路中的正則化方法。
1.1 為什麼要正則化?
講到為什麼需要正則化,就需要了解什麼是過擬合問題。以下面圖片為例,我們能夠看到有兩個類別,其中以X代表男生,O代表女生。
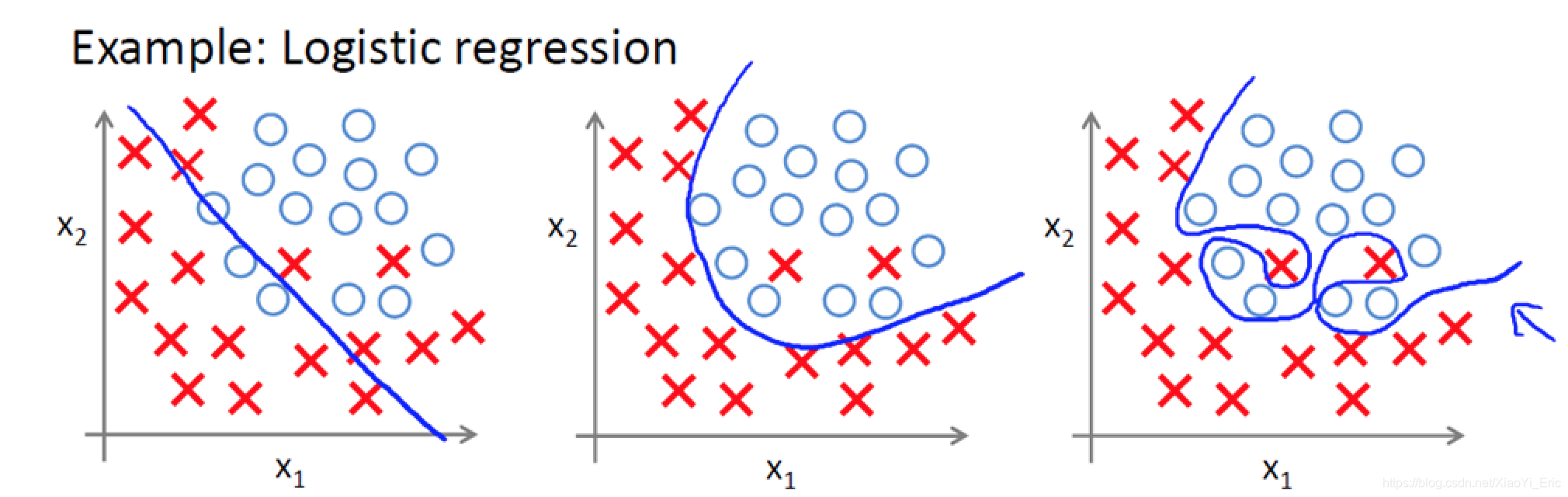
我們想要通過學習來得到分類曲線,其中分類曲線能夠有效區分男生和女生,現在來分析下上面的三種分類結果。
- **欠擬合:**圖1分類明顯欠缺,有些男生被分為女生,有些女生被分為男生。
- **正擬合:**圖2雖然有兩個男生被分類為女生,但能夠理解,畢竟我們人類自己也有分類錯誤的情況,比如通過化妝,女裝等方法。
- 過擬合:圖3雖然能夠全部分類正確,但結果全部正確就一定好嗎?不一定,我們能夠看到分類曲線明顯過於複雜,模型學習的時候學習了過多的引數項,但其中某些引數項是無用的特徵,比如眼睛大小。當我們進行識別測試集資料時,就需要提供更多的特徵,如果測試集包含海量的資料,模型的時間複雜度可想而知。
1.2 什麼是正則化?
既然我們已經知道什麼是過擬合,那麼怎麼解決過擬合問題呢?上面有介紹到,模型出現過擬合,是在模型特徵上過於複雜。而特徵又包含在我們的目標函式f(x)之中,那麼只能從目標函式f(x)中尋找解決問題的方法。假設目標函式f(x)和損失函式J0為
對於上式,如果特徵項越多的話,自然也就越多。想要減少特徵的數量,自然減小N也就好了。而N影響的是和兩項,那麼是從X解決問題還是從W解決問題呢?
如果從X入手解決問題,但訓練過程中我們不知道下一個樣本X是什麼,會怎樣的影響目標函式,所以此路不通。那麼W如何呢?我們知道W係數是訓練過程中通過學習歷史資料得到的,和歷史資料有關,所以應該可以。現在再回到我們原來的問題,希望減少N的數目,而讓N最小化,其實就是讓X向量或W向量中項的個數最小化,既然X不行,那麼我們可以嘗試讓W向量中項的個數最小化。如何求解才能讓W向量中項的個數最小,我們先簡單介紹下0、1、2範數的概念。
- **L0範數:**向量中非零元素的個數,記為。
- **L1範數:**絕對值之和,記為。
- **L2範數:**通常意義上的模,記為。
所以為了防止過擬合,我們需要讓最小,同時讓損失函式最小,為了滿足兩項最小化,可以讓和之和最小化。但因為比較難求(NP難問題),我們進而可以轉化為求。是的最優凸近似,都可以實現稀疏,比較容易求解,這也是為什麼可以選用的原因。最後損失函式後面新增的額外項,也就是我們稱作的L1正則化,含義在後面進行講解。
說完L0範數和L1範數,就不得不提L2範數。L2範數是指先求向量各元素的平方和,然後再進行求平方根,也就是通常意義上的模。同樣,對於正則化問題,我們的目標是讓W向量中的每個元素都很小,也就是讓L2範數最小。L1範數和L2範數的不同點在於,L1範數會讓其中某些元素等於0,而L2範數只是讓其中元素接近0,這裡有很大不同,我們在後面會進行詳細講解。最後損失函式後面新增的額外項||W||2,也就是我們稱作的L2正則化。
1.3 L1正則化和L2正則化
L1正則化可以產生稀疏值矩陣,即產生一個稀疏模型,可以用於特徵選擇和解決過擬合。那什麼是稀疏值矩陣呢?稀疏矩陣是矩陣中很多元素為0,只有少數元素是非零值的矩陣,稀疏矩陣的好處就是能夠幫助模型找到重要特徵,而去掉無用特徵或影響甚小的特徵。
比如在分類或預測時,很多特徵難以選擇,如果代入稀疏矩陣,能夠篩選出少數對目標函式有貢獻的特徵,去掉絕大部分貢獻很小或沒有貢獻的特徵(因為稀疏矩陣很多值是0或是很小值)。因此我們只需要關注係數是非零值的特徵,從而達到特徵選擇和解決過擬合的問題。那麼為什麼L1正則化可以產生稀疏模型呢?
假如帶有L1正則化的損失函式方程如下所示,其中是原始損失函式,是正則化項,是正則化係數。根據1.2節的介紹,可以採用一定的方法,比如梯度下降法,求出在L1的約束下的最小值。
以上述損失函式為例,我們考慮二維的情況,即只有兩個權值和,此時。對於梯度下降法,求解的過程,可以畫出如下的等值線。同時L1正則化函式也可以在二維平面上表示出來,即黑色直線所圍成的菱形。
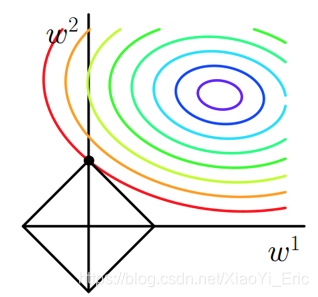
從上圖可以看出,當J0等值線與L1圖形首次相交的點就是最優解,也就是上圖中的(0,w)。而對於L1函式有許多突出的點(二維情況下是4個),J0函式與這些頂點接觸的概率遠大於與L1其他部分接觸的概率,恰好在這些頂點上會有很多權值等於0,這就是為什麼L1正則化可以產生稀疏模型,進而可以用於特徵選擇。最後針對L1正則化再介紹下係數α,其目的是控制L1圖形的大小。當α越小,L1的圖形越大,α越大,L1圖形也就越小。L1圖形可以小到在原點附近,這也就是為什麼w可以取到很小的原因。
另外L2正則化也可以很好的解決過擬合問題。從上面得知,擬合過程中通常都傾向於讓權值儘可能小,最後構造出一個讓所有引數都比較小的模型。因為一般認為引數值小的模型比較簡單,能夠適應於不同的資料集,比如對於目標方程,若引數很大,那麼資料只要偏倚一點點,那麼對結果的影響就很大。如果引數很小的話,即使資料變化範圍比較大,對結果影響也不是很大。相對來說,引數較小的話,對模型的抗擾動能力強。那麼為什麼L2正則化可以獲得很小的引數值呢?我們假設帶有L2正則化的損失函式方程如下所示,並對損失函式進行求導。