
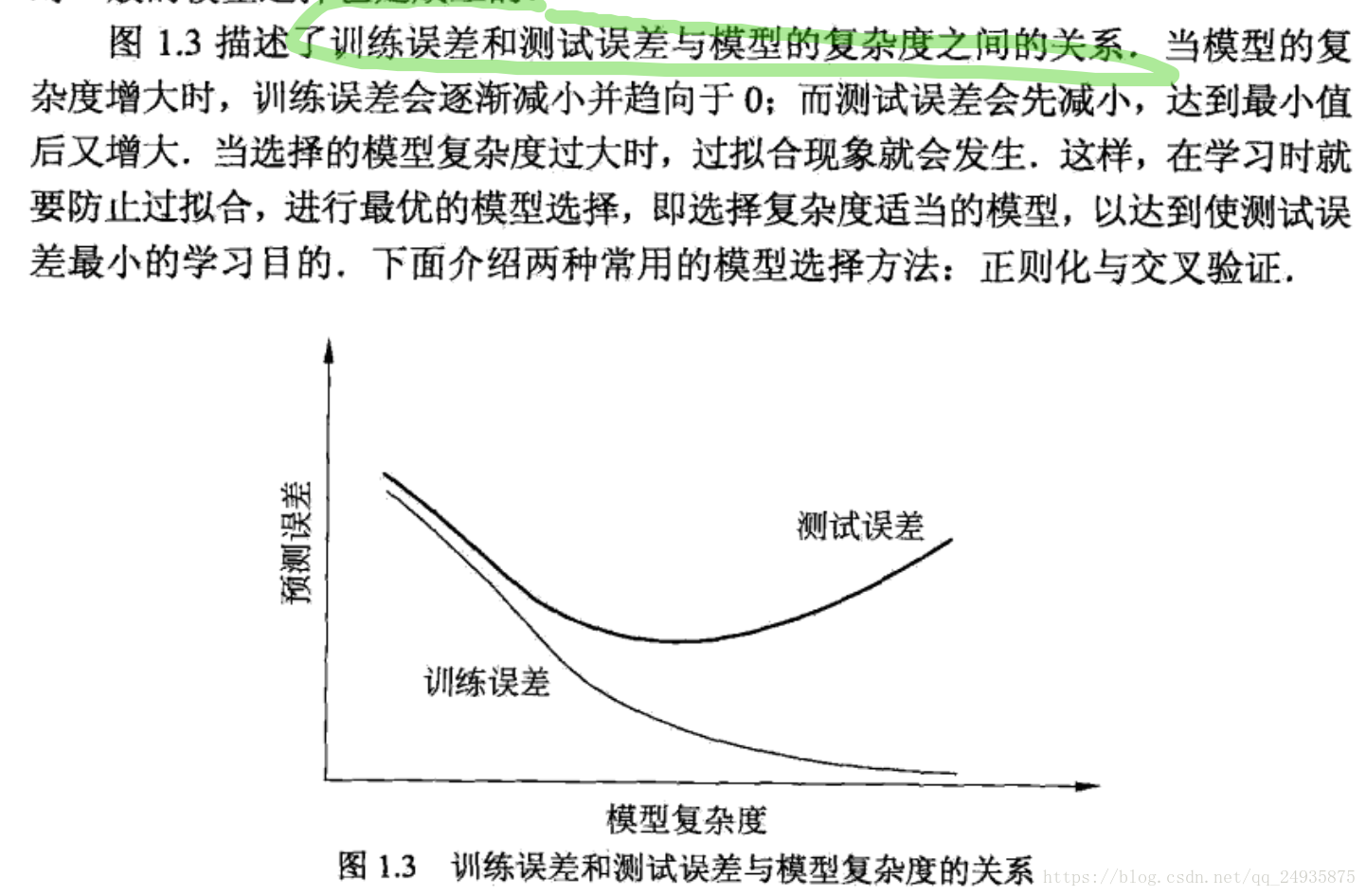
機器學習總結之正則化
之前學習總是搞不懂正則化到底什麼玩意兒,就知道它的公式,它能降低過擬合,但是,它到底為什麼能降低過擬合呢,看了李航老師的《統計學習方法》有了些許體悟。以什麼方式呈現呢,就以問答的方式吧,三省吾身,挺好的。
1 為什麼資料量過小會導致過擬合,為什麼正則化能夠降低過擬合?
因為本質上來說我們選擇模型的標註在於損失函式,我們往往將損失函式和我們真正使用的風險函式混淆了,損失函式描述的是一次預測錯誤的程度,而風險函式時整個批量的資料平均的錯誤程度,我們一般用風險函式來作為模型選擇的標準,可是在計算風險函式的過程中,我們需要系統的聯合分佈,可是我們不知道系統的聯合分佈(正是學習的物件),故而採用的風險函式的近似經驗風險函式,也就是深度學習中理解的損失函式,但是,根據大數理論,只有當資料量足夠多的情況下,經驗風險函式才能無限趨近與風險函式,所以當資料量過小時這個假設就無法成立了,自然無法得到好的模型,所以在有監督的學習中,一般存在經驗風險最小和結構風險最小化,經驗風險最小化我們之前介紹了,那結構風險最小化是啥?下面就直接截圖了,李航第一章裡面的。

 好了,也不知道說清楚了沒。。。。卡卡卡卡
好了,也不知道說清楚了沒。。。。卡卡卡卡
相關推薦
機器學習總結之正則化
之前學習總是搞不懂正則化到底什麼玩意兒,就知道它的公式,它能降低過擬合,但是,它到底為什麼能降低過擬合呢,看了李航老師的《統計學習方法》有了些許體悟。以什麼方式呈現呢,就以問答的方式吧,三省吾身,挺好的。1 為什麼資料量過小會導致過擬合,為什麼正則化能夠降低過擬合?因為本質上
機器學習演算法之正則化
>By joey周琦 正則化 假設目標函式為 J J, 比如 J J可以是對數似然函式的負數形式,特徵 i i的係數為 wi w_i, 係數向量 w=[w1,...,
機器學習中的正則化
道理 lazy 算法 htbox 而且 有趣的 文章 很難 直接 作者:陶輕松鏈接:https://www.zhihu.com/question/20924039/answer/131421690來源:知乎著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請註明出處。
機器學習筆記:正則化
有這麼幾個問題:1、什麼是正則化?2、為什麼要用正則化?3、正則化分為哪幾類? 在機器學習中我們經常看到在損失函式後會有一個正則化項,正則化項一般分為兩種L1正則化和L2正則化,可以看做是損失函式的懲罰項。懲罰項的作用我認為就是對模型中的引數限制,從而防止
機器學習中的正則化(Regularization)
參考知乎回答:https://www.zhihu.com/question/20924039 以及部落格 https://blog.csdn.net/jinping_shi/article/details/52433975 定義&用途 經常能在L
吳恩達機器學習練習2——正則化的Logistic迴歸
機器學習練習2——正則化的Logistic迴歸 過擬合 如果我們有非常多的特徵,我們通過學習得到的假設可能能夠非常好地適應訓練集(代價函式可能幾乎為0),但是可能會不能推廣到新的資料。 解決: 1.丟棄一些不能幫助我們正確預測的特徵。可以是手工選擇保留哪些特
關於機器學習當中的正則化、範數的一些理解
The blog is fantastic! What I want to know is why we should regularlize and how we can regularlize, fortunately, this article tells all
機器學習筆記:正則化項
在機器學習演算法中如果只使用經驗風險最小化去優化損失函式則很可能造成過擬合的問題,通常我們要在損失函式中加入一些描述模型複雜程度的正則化項,使得模型在擁有較好的預測能力的同時不會因為模型過於複雜而產生過擬合現象,即結構風險最小化 正則化項一般是模型複雜程度的單調
吳恩達機器學習筆記 —— 8 正則化
本章講述了機器學習中如何解決過擬合問題——正則化。講述了正則化的作用以及線上性迴歸和邏輯迴歸是怎麼參與到梯度優化中的。 在訓練過程中,在訓練集中有時效果比較差,我們叫做欠擬合;有時候效果過於完美,在測試集上效果很差,我們叫做過擬合。因為欠擬合和過擬合都不能良好的反應一個模型應用新樣本的能力,因此需要找到
機器學習中的正則化和範數規則化
正則化和範數規則化 文章安排:文章先介紹了正則化的定義,然後介紹其在機器學習中的規則化應用L0、L1、L2規則化範數和核範數規則化,最後介紹規則化項引數的選擇問題。 正則化(regularization)來源於線性代數理論中的不適定問題,求解不適定問題的普遍方法是:用一族與
[知乎]機器學習中使用正則化來防止過擬合是什麼原理?
我們相當於是給模型引數w 添加了一個協方差為1/alpha 的零均值高斯分佈先驗。 對於alpha =0,也就是不新增正則化約束,則相當於引數的高斯先驗分佈有著無窮大的協方差,那麼這個先驗約束則會非常弱,模型為了擬合所有的訓練資料,w可以變得任意大不穩定。alph
機器學習C6筆記:正則化文本回歸(交叉驗證,正則化,lasso)
非線性模型 廣義加性模型 Generalized Additive Model (GAM)同過使用ggplot2程式包中的geom_smooth函式,使用預設的smooth函式,就可以擬合GAM模型: set.seed(1) x <- se
機器學習中的正則化方法
引數範數懲罰 L1 L2 regularization 正則化一般具有如下形式:(結構風險最小化) 其中,第一項是經驗風險,第二項是正則化項,lambda>=0為調整兩者之間關係的係數。 正則化項可以取不同的形式,如引數向量w的L2範數:
[機器學習實驗4]正則化(引入懲罰因子)
線性迴歸中引入正則化引數。 x再線性迴歸的實踐中是一維的,如果是更高維度的還要做一個特徵的轉化,後面的logic迴歸裡面會提到 引入正則化引數之後公式如上,當最小化J(θ)時,λ 越大,θ越小,所以通過調節λ的值可以調節擬合的h函式中中θ的大
機器學習中regularization正則化(加入weight_decay)的作用
Regularization in Linear Regression 轉載自:http://blog.sina.com.cn/s/blog_a18c98e5010115ta.html Regularization是Linear Regression中很重要的一步。
吳恩達機器學習筆記21-正則化線性回歸(Regularized Linear Regression)
減少 ear 額外 利用 line pan 兩種 方程 res 對於線性回歸的求解,我們之前推導了兩種學習算法:一種基於梯度下降,一種基於正規方程。 正則化線性回歸的代價函數為: 如果我們要使用梯度下降法令這個代價函數最小化,因為我們未對theta0進行正則化,
機器學習之正則化(Regularization)
1. The Problem of Overfitting 1 還是來看預測房價的這個例子,我們先對該資料做線性迴歸,也就是左邊第一張圖。 如果這麼做,我們可以獲得擬合數據的這樣一條直線,但是,實際上這並不是一個很好的模型。我們看看這些資料,很明顯,隨著房子面積增大,住房價格的變化趨於穩定或者說越往右越平緩
系統學習機器學習之正則化(二)
監督機器學習問題無非就是“minimizeyour error while regularizing your parameters”,也就是在規則化引數的同時最小化誤差。最小化誤差是為了讓我們的模型擬合我們的訓練資料,而規則化引數是防止我們的模型過分擬合我們的訓練資料。多麼簡約的哲學啊!因為引數太多,會導致
theano學習之正則化
先上程式碼: from __future__ import print_function import theano from sklearn.datasets import load_boston#波士頓房價資料 import theano.tensor as T import numpy a
深度學習之正則化系列(2):資料集增強(資料增廣)
讓機器學習模型泛化得更好的最好辦法是使用更多的資料進行訓練。當然,在實踐中,我們擁有的資料量是很有限的。解決這個問題的一種方法是建立假資料並新增到訓練集中。對於一些機器學習任務,建立新的假資料相當簡單。對分類來說這種方法是最簡單的。分類器需要一個複雜的高維輸入