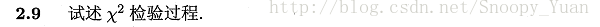周志華《機器學習》課後習題解答系列(三):Ch2
本章概要
本章講述了模型評估與選擇(model evaluation and selection)的相關知識:
2.1 經驗誤差與過擬合(empirical error & overfitting)
精度accuracy、訓練誤差(經驗誤差)training error(empirical error)、泛化誤差**generalization error、過擬合**overfitting、欠擬合underfitting;
2.2 模型評估方法(evaluate method)
測試誤差testing error、留出法hold-out、分層取樣stratified sampling、交叉驗證法cross validation、k-折交叉驗證**k-fold cross validation、留一法leave-one-out(LOO)、
自助法bootstrapping、自助取樣bootstrap sampling、包外估計out-of-bag estimate、調參**parameter tuning、驗證集validation set;
2.3 模型效能度量(performance measure)
錯誤率error rate、查準率(準確率)precision、查全率(召回率)recall、P-R曲線、平衡點BEP、F1/Fβ、混淆矩陣、ROC曲線、AUC、代價敏感cost-sensitive、**代價矩陣**cost matrix、代價曲線cost curve、期望總體代價;
2.4 模型比較檢驗(comparation & testing)
假設檢驗hypothesis test、拒絕假設、t-檢驗t-test、Friedman檢驗、後續檢驗post-hoc test、Friedman檢驗圖;
2.5 偏差與方差(bias & variance)
偏差-方差窘境bias-variance dilemma;
習題解答
2.1 分層抽樣劃分訓練集與測試集

根據分層取樣原則,共有方法:
2.2 留一法與k-折交叉驗證法比較

因為測試集被劃分到訓練樣本中多的類,設一共100個樣本:
留一法:測試集1個樣本,訓練集99個樣本且有50個與測試集真實類別不同,故測試集無法被劃分到正確的類,錯誤率100%
交叉驗證法:在採用分層抽樣的前提下,分類靠隨機猜,錯誤率因為50%;
2.3 F1值與BEP的關聯
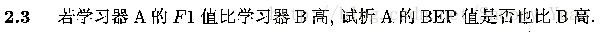
首先給出度量定義:
BEP:是P-R曲線上的平衡點座標值,BEP = P = R (即準確率 = 召回率);
F1值:是P與R的調和平均,1/F1 = (1/P + 1/R) / 2;
所以 BEP = F1 (當P = R時) -> BEP(A) > BEP(B).
2.4 TPR、FPR、P、R之間的關聯

給出混淆矩陣示例如下:
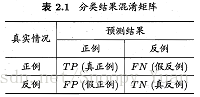
然後給出各度量的定義式:

詳細解釋是:
- P,查準率(準確率),(預測正例)中(真實正例)的比例.
- R,查全率(召回率),(真實正例)中(預測正例)的比例.
- TPR,真正例率,(真實正例)中(預測正例)的比例,TPR = R.
- FPR,假正例率,(真實反例)中(預測正例)的比例.
2.5 AUC推導(有限樣例下)
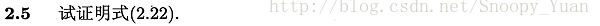
直接給出大致思路如下圖:
2.6 錯誤率與ROC曲線的關係
錯誤率可由代價-混淆矩陣得出;
ROC曲線基於TPR與FPR表示了模型在不同截斷點取值下的泛化效能。
ROC曲線上的點越靠近(1,0)學習器越完美,但是常需要通過計算等錯誤率來實現P、R的折衷,而P、R則反映了我們所側重部分的錯誤率。
2.7 ROC曲線與代價曲線的對應關係

ROC曲線的點對應了一對(TPR,FPR),即一對(FNR,FPR),由此可得一條代價線段(0,FPR)–(1,FNR),由所有代價線段構成簇,圍取期望總體代價和它的邊界–代價曲線。所以說,ROC對應了一條代價曲線,反之亦然。
2.8 ROC曲線與代價曲線的關係

比較見表:
| Max-min | z-score |
|---|---|
| 方法簡單 | 計算量相對大一些 |
| 容易受高槓杆點和離群點影響 | 對離群點敏感度相對低一些 |
| 當加入新值超出當前最大最小範圍時重新計算所有之前的結果 | 每加入新值都要重新計算所有之前結果 |