
大資料儲存系統(1)--- 分散式檔案系統
阿新 • • 發佈:2019-01-05
分散式檔案系統
一、分散式系統概念
(1)分散式系統型別:
Client/Server、P2P(Peer-to-Peer)、Master/Worker
(2)故障模型(Failure Model):
Fail stop:出現故障時,程序停止/崩潰
Fail slow:出現故障時,執行速度變得很慢
Byzantine failure:包含惡意攻擊
(3)CAP定理:三者不可得兼
Consistency:多份資料一致性
Availability:可用性
Partition tolerance:容忍網路斷開
二、分散式檔案系統
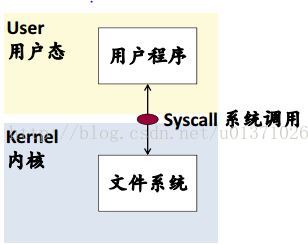
(1)本地檔案系統(Local File System):
Linux ext4、Windows ntfs、Mac OS hfs……
(2)NFS(Sun’s Network File System): 定義了開放的client/server之間的通訊協議標準。 主要目的:從不同的終端都可以訪問同一個目錄;多使用者共享資料;集中管理。 系統架構: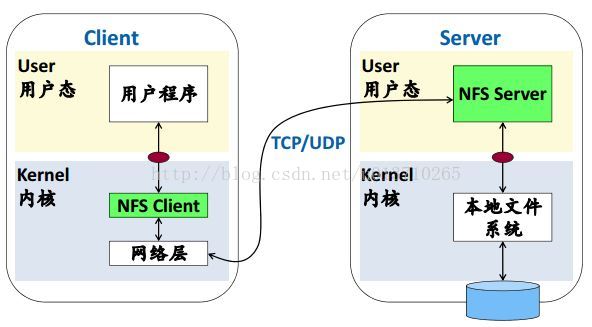
設計目標1:伺服器出現故障,可以簡單快速恢復(Fail-stop模型) 
Name Node:儲存檔案的metadata(元資料)。檔名、長度、分成多少資料塊,每個資料塊分佈在哪些Data Node上。 Data Node:儲存資料塊。 檔案切分成定長的資料塊(預設為64MB大小)。 每個資料塊獨立地分佈儲存在Data Node上。預設每個資料塊儲存3份,在3個不同的data node上。 (3)讀寫操作 HDFS/GFS讀檔案:開啟檔案(通過Name Node);讀資料(通過Data Node,繞開Name Node)。 HDFS/GFS寫檔案:向Name Node請求寫資料塊,返回應該寫的Data Node;傳送資料塊,Data Node在記憶體中快取資料;傳送寫命令,收到寫命令後才真正進行寫操作,把快取的資料寫到檔案系統中。 不支援併發寫,支援併發Append!
(2)NFS(Sun’s Network File System): 定義了開放的client/server之間的通訊協議標準。 主要目的:從不同的終端都可以訪問同一個目錄;多使用者共享資料;集中管理。 系統架構:
設計目標1:伺服器出現故障,可以簡單快速恢復(Fail-stop模型)
Name Node:儲存檔案的metadata(元資料)。檔名、長度、分成多少資料塊,每個資料塊分佈在哪些Data Node上。 Data Node:儲存資料塊。 檔案切分成定長的資料塊(預設為64MB大小)。 每個資料塊獨立地分佈儲存在Data Node上。預設每個資料塊儲存3份,在3個不同的data node上。 (3)讀寫操作 HDFS/GFS讀檔案:開啟檔案(通過Name Node);讀資料(通過Data Node,繞開Name Node)。 HDFS/GFS寫檔案:向Name Node請求寫資料塊,返回應該寫的Data Node;傳送資料塊,Data Node在記憶體中快取資料;傳送寫命令,收到寫命令後才真正進行寫操作,把快取的資料寫到檔案系統中。 不支援併發寫,支援併發Append!