
ASCII、Unicode和UTF_8的前生後世
前言
平時喜歡寫東西,看部落格,一直對編碼有些懵,今天下午也不知道看到了什麼,突然想了解下,就找到了這個文章,看完真的豁然開朗,這個必須留下來做紀念。
一、ASCII
我們知道,計算機內部,所有資訊最終都是一個二進位制值。每一個二進位制位(bit)有0和1兩種狀態,因此八個二進位制位就可以組合出256種狀態,這被稱為一個位元組(byte)。也就是說,一個位元組一共可以用來表示256種不同的狀態,每一個狀態對應一個符號,就是256個符號,從00000000到11111111。
上個世紀60年代,美國製定了一套字元編碼,對英語字元與二進位制位之間的關係,做了統一規定。這被稱為 ASCII 碼,一直沿用至今。
ASCII 碼一共規定了128個字元的編碼,比如空格SPACE是32(二進位制00100000),大寫的字母A是65(二進位制01000001)。這128個符號(包括32個不能打印出來的控制符號),只佔用了一個位元組的後面7位,最前面的一位統一規定為0。
二、非ASCII編碼
英語用128個符號編碼就夠了,但是用來表示其他語言,128個符號是不夠的。比如,在法語中,字母上方有注音符號,它就無法用 ASCII 碼錶示。於是,一些歐洲國家就決定,利用位元組中閒置的最高位編入新的符號。比如,法語中的é的編碼為130(二進位制10000010)。這樣一來,這些歐洲國家使用的編碼體系,可以表示最多256個符號。
但是,這裡又出現了新的問題。不同的國家有不同的字母,因此,哪怕它們都使用256個符號的編碼方式,代表的字母卻不一樣。比如,130在法語編碼中代表了é,在希伯來語編碼中卻代表了字母Gimel (ג),在俄語編碼中又會代表另一個符號。但是不管怎樣,所有這些編碼方式中,0--127表示的符號是一樣的,不一樣的只是128--255的這一段。
至於亞洲國家的文字,使用的符號就更多了,漢字就多達10萬左右。一個位元組只能表示256種符號,肯定是不夠的,就必須使用多個位元組表達一個符號。比如,簡體中文常見的編碼方式是 GB2312,使用兩個位元組表示一個漢字,所以理論上最多可以表示 256 x 256 = 65536 個符號
中文編碼的問題需要專文討論,這篇筆記不涉及。這裡只指出,雖然都是用多個位元組表示一個符號,但是GB類的漢字編碼與後文的 Unicode 和 UTF-8 是毫無關係的。
三、Unicode
正如上一節所說,世界上存在著多種編碼方式,同一個二進位制數字可以被解釋成不同的符號。因此,要想開啟一個文字檔案,就必須知道它的編碼方式,否則用錯誤的編碼方式解讀,就會出現亂碼。為什麼電子郵件常常出現亂碼?就是因為發信人和收信人使用的編碼方式不一樣。
可以想象,如果有一種編碼,將世界上所有的符號都納入其中。每一個符號都給予一個獨一無二的編碼,那麼亂碼問題就會消失。這就是 Unicode,就像它的名字都表示的,這是一種所有符號的編碼。
Unicode 當然是一個很大的集合,現在的規模可以容納100多萬個符號。每個符號的編碼都不一樣,比如,U+0639表示阿拉伯字母Ain,U+0041表示英語的大寫字母A,U+4E25表示漢字嚴。具體的符號對應表,可以查詢unicode.org,或者專門的漢字對應表。
四、Unicode的問題
需要注意的是,Unicode 只是一個符號集,它只規定了符號的二進位制程式碼,卻沒有規定這個二進位制程式碼應該如何儲存。
比如,漢字嚴的 Unicode 是十六進位制數4E25,轉換成二進位制數足足有15位(100111000100101),也就是說,這個符號的表示至少需要2個位元組。表示其他更大的符號,可能需要3個位元組或者4個位元組,甚至更多。
這裡就有兩個嚴重的問題,第一個問題是,如何才能區別 Unicode 和 ASCII ?計算機怎麼知道三個位元組表示一個符號,而不是分別表示三個符號呢?第二個問題是,我們已經知道,英文字母只用一個位元組表示就夠了,如果 Unicode 統一規定,每個符號用三個或四個位元組表示,那麼每個英文字母前都必然有二到三個位元組是0,這對於儲存來說是極大的浪費,文字檔案的大小會因此大出二三倍,這是無法接受的
它們造成的結果是:1)出現了 Unicode 的多種儲存方式,也就是說有許多種不同的二進位制格式,可以用來表示 Unicode。2)Unicode 在很長一段時間內無法推廣,直到網際網路的出現。
四、UTF-8
網際網路的普及,強烈要求出現一種統一的編碼方式。UTF-8 就是在網際網路上使用最廣的一種 Unicode 的實現方式。其他實現方式還包括 UTF-16(字元用兩個位元組或四個位元組表示)和 UTF-32(字元用四個位元組表示),不過在網際網路上基本不用。重複一遍,這裡的關係是,UTF-8 是 Unicode 的實現方式之一。
UTF-8 最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個位元組表示一個符號,根據不同的符號而變化位元組長度。
UTF-8 的編碼規則很簡單,只有二條:
- 對於單位元組的符號,位元組的第一位設為0,後面7位為這個符號的 Unicode 碼。因此對於英語字母,UTF-8 編碼和 ASCII 碼是相同的。
- 對於n位元組的符號(n > 1),第一個位元組的前n位都設為1,第n + 1位設為0,後面位元組的前兩位一律設為10。剩下的沒有提及的二進位制位,全部為這個符號的 Unicode 碼。
下表總結了編碼規則,字母x表示可用編碼的位。

跟據上表,解讀 UTF-8 編碼非常簡單。如果一個位元組的第一位是0,則這個位元組單獨就是一個字元;如果第一位是1,則連續有多少個1,就表示當前字元佔用多少個位元組。
下面,還是以漢字嚴為例,演示如何實現 UTF-8 編碼。
嚴的 Unicode 是4E25(100111000100101),根據上表,可以發現4E25處在第三行的範圍內(0000 0800 - 0000 FFFF),因此嚴的 UTF-8 編碼需要三個位元組,即格式是1110xxxx 10xxxxxx 10xxxxxx。然後,從嚴的最後一個二進位制位開始,依次從後向前填入格式中的x,多出的位補0。這樣就得到了,嚴的 UTF-8 編碼是11100100 10111000 10100101,轉換成十六進位制就是E4B8A5
六、Unicode和UTF-8之間的轉換
通過上一節的例子,可以看到嚴的 Unicode碼 是4E25,UTF-8 編碼是E4B8A5,兩者是不一樣的。它們之間的轉換可以通過程式實現。
Windows平臺,有一個最簡單的轉化方法,就是使用內建的記事本小程式notepad.exe。開啟檔案後,點選檔案選單中的另存為命令,會跳出一個對話方塊,在最底部有一個編碼的下拉條。

裡面有四個選項:ANSI,Unicode,Unicode big endian和UTF-8。
- ANSI是預設的編碼方式。對於英文檔案是ASCII編碼,對於簡體中文檔案是GB2312編碼(只針對 Windows 簡體中文版,如果是繁體中文版會採用 Big5 碼)。
- Unicode編碼這裡指的是notepad.exe使用的 UCS-2 編碼方式,即直接用兩個位元組存入字元的 Unicode 碼,這個選項用的 little endian 格式。
- Unicode big endian編碼與上一個選項相對應。我在下一節會解釋 little endian 和 big endian 的涵義。
- UTF-8編碼,也就是上一節談到的編碼方法。
選擇完"編碼方式"後,點選"儲存"按鈕,檔案的編碼方式就立刻轉換好了。
七、Little endian 和 Big endian
上一節已經提到,UCS-2 格式可以儲存 Unicode 碼(碼點不超過0xFFFF)。以漢字嚴為例,Unicode 碼是4E25,需要用兩個位元組儲存,一個位元組是4E,另一個位元組是25。儲存的時候,4E在前,25在後,這就是 Big endian 方式;25在前,4E在後,這是 Little endian 方式。
這兩個古怪的名稱來自英國作家斯威夫特的《格列佛遊記》。在該書中,小人國裡爆發了內戰,戰爭起因是人們爭論,吃雞蛋時究竟是從大頭(Big-endian)敲開還是從小頭(Little-endian)敲開。為了這件事情,前後爆發了六次戰爭,一個皇帝送了命,另一個皇帝丟了王位。
第一個位元組在前,就是"大頭方式"(Big endian),第二個位元組在前就是"小頭方式"(Little endian)。
那麼很自然的,就會出現一個問題:計算機怎麼知道某一個檔案到底採用哪一種方式編碼?
Unicode 規範定義,每一個檔案的最前面分別加入一個表示編碼順序的字元,這個字元的名字叫做"零寬度非換行空格"(zero width no-break space),用FEFF表示。這正好是兩個位元組,而且FF比FE大1。
如果一個文字檔案的頭兩個位元組是FE FF,就表示該檔案採用大頭方式;如果頭兩個位元組是FF FE,就表示該檔案採用小頭方式。
八、例項
下面,舉一個例項。
開啟"記事本"程式notepad.exe,新建一個文字檔案,內容就是一個嚴字,依次採用ANSI,Unicode,Unicode big endian和UTF-8編碼方式儲存。
然後,用文字編輯軟體UltraEdit 中的"十六進位制功能",觀察該檔案的內部編碼方式。
- ANSI:檔案的編碼就是兩個位元組D1 CF,這正是嚴的 GB2312 編碼,這也暗示 GB2312 是採用大頭方式儲存的。
- Unicode:編碼是四個位元組FF FE 25 4E,其中FF FE表明是小頭方式儲存,真正的編碼是4E25。
- Unicode big endian:編碼是四個位元組FE FF 4E 25,其中FE FF表明是大頭方式儲存。
4)UTF-8:編碼是六個位元組EF BB BF E4 B8 A5,前三個位元組EF BB BF表示這是UTF-8編碼,後三個E4B8A5就是嚴的具體編碼,它的儲存順序與編碼順序是一致的。
九、參考文獻
文章:
十、補充
今天在看python的時候了正好看到了編碼的文章,記錄一下。基本誕生邏輯上面已經有了,補充下其他的介紹。
現在,捋一捋ASCII編碼和Unicode編碼的區別:ASCII編碼是1個位元組,而Unicode編碼通常是2個位元組。
字母A用ASCII編碼是十進位制的65,二進位制的01000001;
字元0用ASCII編碼是十進位制的48,二進位制的00110000,注意字元'0'和整數0是不同的;
漢字中已經超出了ASCII編碼的範圍,用Unicode編碼是十進位制的20013,二進位制的01001110 00101101。
你可以猜測,如果把ASCII編碼的A用Unicode編碼,只需要在前面補0就可以,因此,A的Unicode編碼是00000000 01000001。
新的問題又出現了:如果統一成Unicode編碼,亂碼問題從此消失了。但是,如果你寫的文字基本上全部是英文的話,用Unicode編碼比ASCII編碼需要多一倍的儲存空間,在儲存和傳輸上就十分不划算。
所以,本著節約的精神,又出現了把Unicode編碼轉化為“可變長編碼”的UTF-8編碼。UTF-8編碼把一個Unicode字元根據不同的數字大小編碼成1-6個位元組,常用的英文字母被編碼成1個位元組,漢字通常是3個位元組,只有很生僻的字元才會被編碼成4-6個位元組。如果你要傳輸的文字包含大量英文字元,用UTF-8編碼就能節省空間:

從上面的表格還可以發現,UTF-8編碼有一個額外的好處,就是ASCII編碼實際上可以被看成是UTF-8編碼的一部分,所以,大量只支援ASCII編碼的歷史遺留軟體可以在UTF-8編碼下繼續工作
搞清楚了ASCII、Unicode和UTF-8的關係,我們就可以總結一下現在計算機系統通用的字元編碼工作方式:
在計算機記憶體中,統一使用Unicode編碼,當需要儲存到硬碟或者需要傳輸的時候,就轉換為UTF-8編碼。
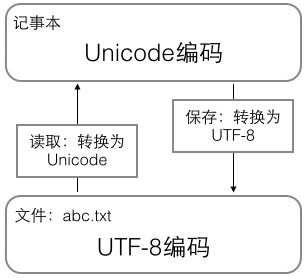
用記事本編輯的時候,從檔案讀取的UTF-8字元被轉換為Unicode字元到記憶體裡,編輯完成後,儲存的時候再把Unicode轉換為UTF-8儲存到檔案:
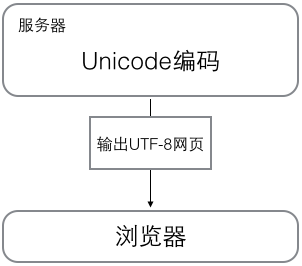
瀏覽網頁的時候,伺服器會把動態生成的Unicode內容轉換為UTF-8再傳輸到瀏覽器:
所以你看到很多網頁的原始碼上會有類似<meta charset="UTF-8" />的資訊,表示該網頁正是用的UTF-8編碼。