
Learning Spark——client mode和cluster mode的區別
在使用spark-submit提交Spark任務一般有以下引數:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]其中deploy-mode是針對叢集而言的,是指叢集部署的模式,根據Driver主程序放在哪分為兩種方式:client和cluster,預設是client,下面我們就詳細研究一下這兩種模式的區別
1. client mode
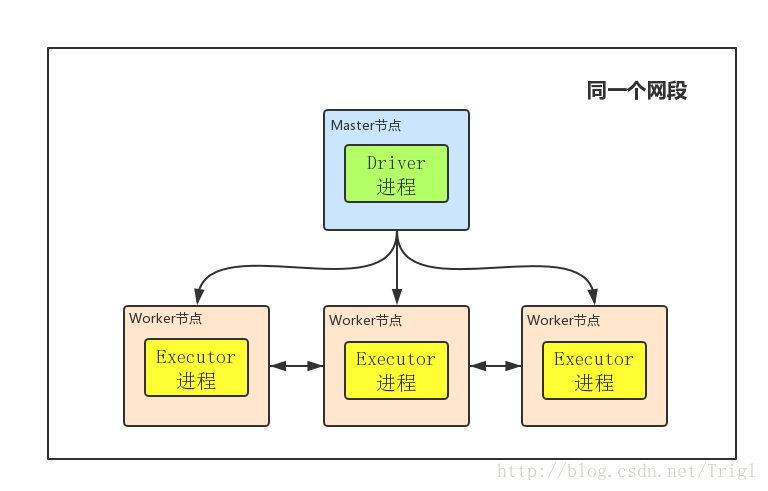
首先明白幾個基本概念:Master節點就是你用來提交任務,即執行bin/spark-submit命令所在的那個節點;Driver程序就是開始執行你Spark程式的那個Main函式,雖然我這裡邊畫的Driver程序在Master節點上,但注意Driver程序不一定在Master節點上,它可以在任何節點;Worker就是Slave節點,Executor程序必然在Worker節點上,用來進行實際的計算
1、client mode下Driver程序執行在Master節點上,不在Worker節點上,所以相對於參與實際計算的Worker叢集而言,Driver就相當於是一個第三方的“client”
2、正由於Driver程序不在Worker節點上,所以其是獨立的,不會消耗Worker叢集的資源
3、client mode下Master和Worker節點必須處於同一片區域網內,因為Drive要和Executorr通訊,例如Drive需要將Jar包通過Netty HTTP分發到Executor,Driver要給Executor分配任務等
4、client mode下沒有監督重啟機制,Driver程序如果掛了,需要額外的程式重啟
2. cluster mode
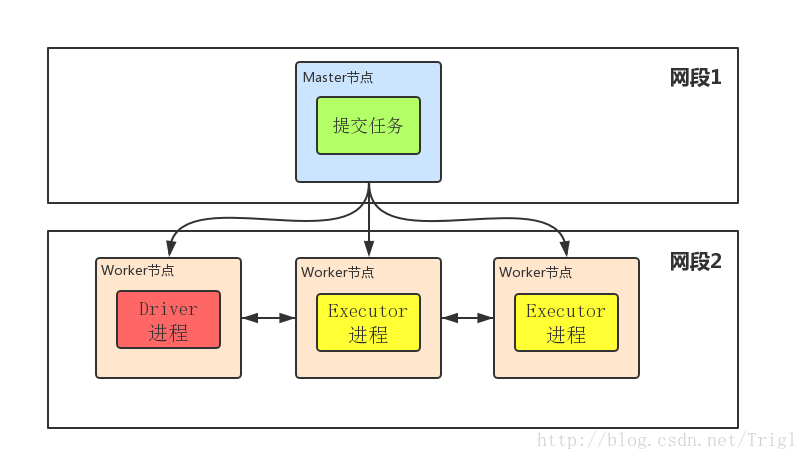
1、Driver程式在worker叢集中某個節點,而非Master節點,但是這個節點由Master指定
2、Driver程式佔據Worker的資源
3、cluster mode下Master可以使用–supervise對Driver進行監控,如果Driver掛了可以自動重啟
4、cluster mode下Master節點和Worker節點一般不在同一區域網,因此就無法將Jar包分發到各個Worker,所以cluster mode要求必須提前把Jar包放到各個Worker幾點對應的目錄下面
3. 總結
是選擇client mode還是cluster mode呢?
一般來說,如果提交任務的節點(即Master)和Worker叢集在同一個網路內,此時client mode比較合適
如果提交任務的節點和Worker叢集相隔比較遠,就會採用cluster mode來最小化Driver和Executor之間的網路延遲
Refer