
利用Python讀取外部資料檔案
不論是資料分析,資料視覺化,還是資料探勘,一切的一切全都是以資料作為最基礎的元素。利用Python進行資料分析,同樣最重要的一步就是如何將資料匯入到Python中,然後才可以實現後面的資料分析、資料視覺化、資料探勘等。
在本期的Python學習中,我們將針對Python如何獲取外部資料做一個詳細的介紹,從中我們將會學習以下4個方面的資料獲取:
1、讀取文字檔案的資料,如txt檔案和csv檔案
2、讀取電子表格檔案,如Excel檔案
3、讀取統計軟體生成的資料檔案,如SAS資料集、SPSS資料集等
4、讀取資料庫資料,如MySQL資料、SQL Server資料
一、讀取文字檔案的資料
大家都知道,Python中pandas模組是專門用來資料分析的一個強大工具,下面我們就來介紹pandas是如何讀取外部資料的。
1、讀取txt資料
In [1]:import pandas as pd
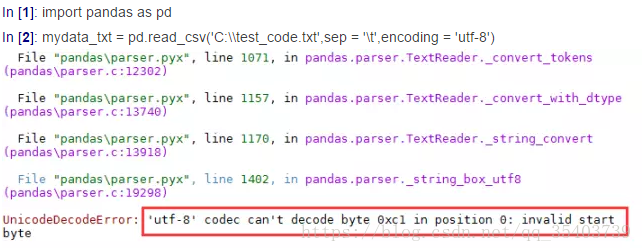
In [2]:mydata_txt = pd.read_csv('C:\\test_code.txt',sep = '\t',encoding = 'utf-8')
對於中文的文字檔案常容易因為編碼的問題而讀取失敗,正如上圖所示。遇到這樣的編碼問題該如何處置呢?解決辦法有兩種情況:
1)當原始檔案txt或csv的資料不是uft8格式時,需要另存為utf8格式編碼;
2)如果原始的資料檔案就是uft8格式,為了正常讀入,需要將read_csv函式的引數encoding設定為utf-8
將原始資料另存為utf8格式的資料,重新讀入txt資料
In [3]:mydata_txt = pd.read_csv('C:\\test.txt',sep = '\t',encoding = 'utf-8')
In [4]:mydata_txt

很順利,txt文字檔案資料就這樣進入了Python的口袋裡了。
2、讀取csv資料
csv文字檔案是非常常用的一種資料儲存格式,而且其儲存量要比Excel電子表格大很多,下面我們就來看看如何利用Python讀取csv格式的資料檔案:
In [5]:mydata_csv = pd.read_csv('C:\\test.csv',sep = ',',encoding = 'utf-8')
In [6]:mydata_csv

如果你善於總結的話,你會發現,txt檔案和csv檔案均可以通過pandas模組中的read_csv函式進行讀取。該函式有20多個引數,類似於R中的read.table函式,如果需要檢視具體的引數詳情,可以檢視幫助文件:help(pandas.read_csv)。
二、讀取電子表格檔案
這裡所說的電子表格就是Excel表格,可以是xls的電子表格,也可以是xlsx的電子表格。在日常工作中,很多資料都是存放在Excel電子表格中的,如果我們需要使用Python對其進行分析或處理的話,第一步就是如何讀取Excel資料。下面我們來看看如果讀取Excel資料集:
In [7]:mydata_excel = pd.read_excel('C:\\test.xlsx',sep = '\t',encoding = 'utf-8')
In [8]: mydata_excel

三、讀取統計軟體生成的資料檔案
往往在整合資料來源的時候,可能會讓你遇到一種苦惱,那就是你的電腦裡存放了很多統計軟體自帶的或生成的資料集,諸如R語言資料集、SAS資料集、SPSS資料集等。那麼問題來了,如果你電腦裡都裝了這些軟體的話,這些資料集你自然可以看見,並可以方便的轉換為文字檔案或電子表格檔案,如果你的電腦裡沒有安裝SAS或SPSS這樣大型的統計分析軟體的話,那麼你該如何檢視這些資料集呢?請放心,Python很萬能,它可以讀取很多種統計軟體的資料集,下面我們介紹幾種Python讀取統計資料集的方法:
1、讀取SAS資料集
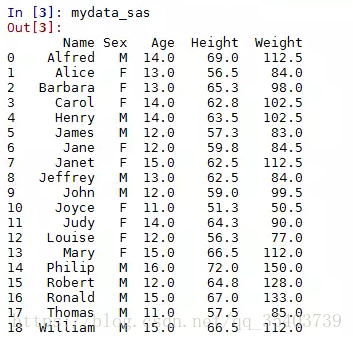
SAS資料集的讀取可以使用pandas模組中的read_sas函式,我們不妨試試該函式讀取SAS資料集。下圖是使用SAS開啟的資料集,如果你的電腦中沒有安裝SAS,那你也可以通過Python實現資料的讀取。

In [1]:import pandas as pd
In [2]:mydata_sas = pd.read_sas('G:\\class.sas7bdat',encoding='utf8')
2、讀取SPSS資料集
讀取SPSS資料就稍微複雜一點,自己測試了好多次,查了好多資料,功夫不負有心人啊,最終還是搞定了。關於讀取SPSS資料檔案,需要為您的Python安裝savReaderWriter模組,該模組可以到如下連結進行下載並安裝:https://pypi.python.org/pypi/savReaderWriter/3.4.2。
安裝savReaderWriter模組
可以通過該命令進行savReaderWriter模組的安裝:python setup.py install
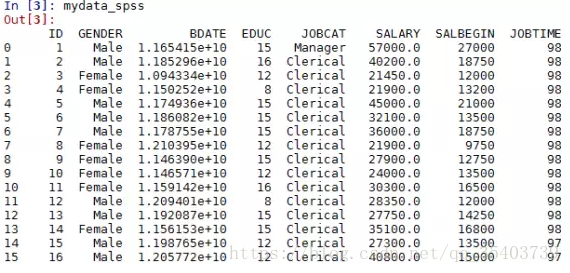
下圖是SPSS資料在SPSS中開啟的樣子:

In [1]:import savReaderWriter
In [2]:mydata_spss = savReaderWriter.SavReader('employee_data.sav')
In [3]:mydata_spss
3、實在沒辦法該怎麼辦?
如果你嘗試了好多種模組都無法讀取某個統計軟體的資料,我建議你還是回到R中,R也是開源的統計分析工具,體積也非常小,只有40M左右,而且R自帶的foreign包可以讀取很多種統計軟體的資料集,當讀取成功後,再利用write.csv函式將資料集寫出為csv格式的資料,這樣Python就可以輕鬆讀取csv資料集了,萬事靈活一點就可以完成你想要的任何結果~
四、讀取資料庫資料
企業中更多的資料還是存放在諸如MySQL、SQL Server、DB2等資料庫中,為了能夠使Python連線到資料庫中,科學家專門設計了Python DB API的介面。我們仍然通過例子來說明Python是如何實現資料庫的連線與操作的。
1、Python連線MySQL
MySQLdb模組是一個連線Python與MySQL的中間橋樑,但目前只能在Python2.x中執行,但不意味著Python3就無法連線MySQL資料庫。這裡向大家介紹一個非常靈活而強大的模組,那就是pymysql模組。我比較喜歡他的原因是,該模組可以偽裝成MySQLdb模組,具體看下面的例子:
In [1]:import pymysql
In [2]:pymysql.install_as_MySQLdb() #偽裝為MySQLdb模組
In [3]:import MySQLdb
使用Connection函式聯通Python與MySQL
In [4]:conn = MySQLdb.Connection(
...: host = 'localhost',
...: user = 'root',
...: password = 'snake',
...: port = 3306,
...: database = 'test',
...: charset='gbk')
使用conn的遊標方法(cursor),目的是為接下來的資料庫操作做鋪墊。
In [5]:cursor = conn.cursor()
In [6]:sql = 'select * from memberinfo'
執行SQL語句
In [7]:cursor.execute(sql)
Out[7]:4
In [8]:data = cursor.fetchall()
In [9]:data
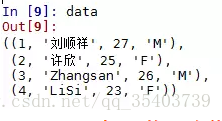
我們發現data中儲存的是元組格式的資料集,我們在《Python資料分析之pandas學習(一)》中講到,構造DataFrame資料結構只能通過陣列、資料框、字典、列表等方式構建,但這裡是元組格式的資料,該如何處理呢?很簡單,只需使用list函式就可以快速的將元組資料轉換為列表格式的資料。
In [10]:data = list(data)
In [11]:data
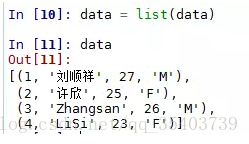
下面我們就是要pandas模組中的DataFrame函式將上面的data列表轉換為Python的資料框格式:
In [14]:import pandas as pd
In [15]:mydata = pd.DataFrame(data, columns = ['id','name','age','gender'])

最後千萬千萬注意的是,當你的資料讀取完之後一定要記得關閉遊標和連線,因為不關閉會導致電腦資源的浪費。
In [19]:cursor.close()
In [20]:conn.close()
2、Python連線SQL Server
使用Python連線SQL Server資料庫,我們這裡推薦使用pymssql模組,該模組的語法與上面講的pymysql是一致的,這裡就不一一講解每一步的含義了,直接上程式碼:
In [21]:import pymssql
In [22]:connect = pymssql.connect(
...: host = '172.18.1.6\SqlR2',
...: user = 'sa',
...: password = '1q2w3e4r!!',
...: database='Heinz_Ana',
...: charset='utf8')
In [23]:cursor = connect.cursor()
In [24]:sql = 'select * from HeinzDB2_10'
In [25]:cursor.execute(sql)
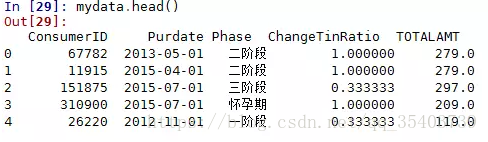
In [26]:data = cursor.fetchall()
In [27]:data[0]
Out[27]:(67782, '2013-05-01', '二階段', 1.0, 279.0)
In [28]:mydata = pd.DataFrame(list(data),columns = ['ConsumerID',
...: 'Purdate',
...: 'Phase',
...: 'ChangeTinRatio',
...: 'TOTALAMT'])
In [29]:mydata.head()
本期的內容就是向大家介紹如何使用Python實現外部資料的讀取,只有完成了這個基本的第一步,才會順利的進行下面的清洗、處理、分析甚至挖掘部分。這一期的內容出來的有點晚,主要還是工作比較繁忙,後期繼續再接再勵,謝謝大家一直以來的支援和互動。在下一期中,我們將介紹R語言中caret包如何實現特徵選擇。
每天進步一點點2015
學習與分享,取長補短,關注小號!