
Scrapy簡單入門及例項講解與安裝
阿新 • • 發佈:2019-01-05
Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。 其可以應用在資料探勘,資訊處理或儲存歷史資料等一系列的程式中。其最初是為了頁面抓取 (更確切來說, 網路抓取 )所設計的, 也可以應用在獲取API所返回的資料(例如 Amazon Associates Web Services ) 或者通用的網路爬蟲。Scrapy用途廣泛,可以用於資料探勘、監測和自動化測試。
Scrapy 使用了 Twisted非同步網路庫來處理網路通訊。整體架構大致如下
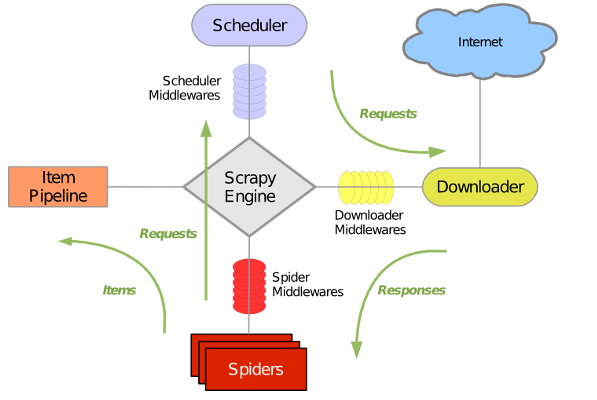
Scrapy主要包括了以下元件:
- 引擎(Scrapy)
用來處理整個系統的資料流, 觸發事務(框架核心) - 排程器(Scheduler)
用來接受引擎發過來的請求, 壓入佇列中, 並在引擎再次請求的時候返回. 可以想像成一個URL(抓取網頁的網址或者說是連結)的優先佇列, 由它來決定下一個要抓取的網址是什麼, 同時去除重複的網址 - 下載器(Downloader)
用於下載網頁內容, 並將網頁內容返回給蜘蛛(Scrapy下載器是建立在twisted這個高效的非同步模型上的) - 爬蟲(Spiders)
爬蟲是主要幹活的, 用於從特定的網頁中提取自己需要的資訊, 即所謂的實體(Item)。使用者也可以從中提取出連結,讓Scrapy繼續抓取下一個頁面 - 專案管道(Pipeline)
負責處理爬蟲從網頁中抽取的實體,主要的功能是持久化實體、驗證實體的有效性、清除不需要的資訊。當頁面被爬蟲解析後,將被髮送到專案管道,並經過幾個特定的次序處理資料。 - 下載器中介軟體(Downloader Middlewares)
位於Scrapy引擎和下載器之間的框架,主要是處理Scrapy引擎與下載器之間的請求及響應。 - 爬蟲中介軟體(Spider Middlewares)
介於Scrapy引擎和爬蟲之間的框架,主要工作是處理蜘蛛的響應輸入和請求輸出。 - 排程中介軟體(Scheduler Middewares)
介於Scrapy引擎和排程之間的中介軟體,從Scrapy引擎傳送到排程的請求和響應。
Scrapy執行流程大概如下:
- 引擎從排程器中取出一個連結(URL)用於接下來的抓取
- 引擎把URL封裝成一個請求(Request)傳給下載器
- 下載器把資源下載下來,並封裝成應答包(Response)
- 爬蟲解析Response
- 解析出實體(Item),則交給實體管道進行進一步的處理
- 解析出的是連結(URL),則把URL交給排程器等待抓取
一、安裝

1、安裝wheel pip install wheel 2、安裝lxml https://pypi.python.org/pypi/lxml/4.1.0 3、安裝pyopenssl https://pypi.python.org/pypi/pyOpenSSL/17.5.0 4、安裝Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/ 5、安裝pywin32 https://sourceforge.net/projects/pywin32/files/ 6、安裝scrapy pip install scrapy
注:windows平臺需要依賴pywin32,請根據自己系統32/64位選擇下載安裝,https://sourceforge.net/projects/pywin32/
二、爬蟲舉例
入門篇:美劇天堂前100最新(http://www.meijutt.com/new100.html)
1、建立工程
| 1 |
scrapy
startproject movie
|
2、建立爬蟲程式
| 1 2 |
cd
movie
scrapy
genspider meiju meijutt.com
|
3、自動建立目錄及檔案
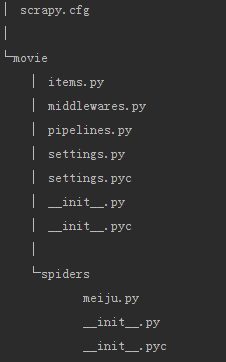
4、檔案說明:
- scrapy.cfg 專案的配置資訊,主要為Scrapy命令列工具提供一個基礎的配置資訊。(真正爬蟲相關的配置資訊在settings.py檔案中)
- items.py 設定資料儲存模板,用於結構化資料,如:Django的Model
- pipelines 資料處理行為,如:一般結構化的資料持久化
- settings.py 配置檔案,如:遞迴的層數、併發數,延遲下載等
- spiders 爬蟲目錄,如:建立檔案,編寫爬蟲規則
注意:一般建立爬蟲檔案時,以網站域名命名
5、設定資料儲存模板
items.py
| 1 2 3 4 5 6 7 8 |
import
scrapy
class MovieItem(scrapy.Item):
#
define the fields for your item here like:
#
name = scrapy.Field()
name
= scrapy.Field()
|
6、編寫爬蟲
meiju.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#
-*- coding: utf-8 -*-
import
scrapy
from movie.items
import MovieItem
class MeijuSpider(scrapy.Spider):
name
= |