Hadoop-->HDFS原理總結
本篇博文主要講講HDFS的一些基礎性的原理以及應用。
HDFS:Hadoop Distributed File System
HDFS概述
HDFS 優點:
高容錯性
- 資料自動儲存多個副本(不同的副本放在不同的節點上)
- 副本丟失後,自動恢復
適合批處理
- 移動計算而非資料
- 資料位置暴露給計算框架
適合大資料處理
- GB、TB、甚至PB級資料
- 百萬規模以上的檔案數量
- 10K+節點規模
流式檔案訪問
- 一次性寫入,多次讀取(只能一次寫入,不能修改已有檔案,只能追加)
- 保證資料一致性(多個副本)
可構建在廉價機器上
- 通過多副本提高可靠性
- 提供了容錯和恢復機制
HDFS 缺點:
不適合低延遲資料訪問
- 比如毫秒級
- 低延遲與高吞吐率
追求的是高吞吐率,犧牲的是低延遲,是一個折中的辦法。
不太適合小檔案存取
- 佔用NameNode大量記憶體
每個檔案都有一些元資訊,比如這個檔案在哪個節點上,有哪些block構成等,小檔案太多會有很多元資訊,而這些元資訊會佔用大量的記憶體。 - 尋道時間超過讀取時間
例如:拷貝一個1G的檔案比拷貝1G的許多小檔案要快得多。當存在許多小檔案時,大量時間都花在尋道上面。
不支援併發寫入、檔案隨機修改
- 一個檔案只能有一個寫者
僅支援append,儲存副本一致性。應用場景:日誌,搜尋等
HDFS基本架構與原理
HDFS 設計思想
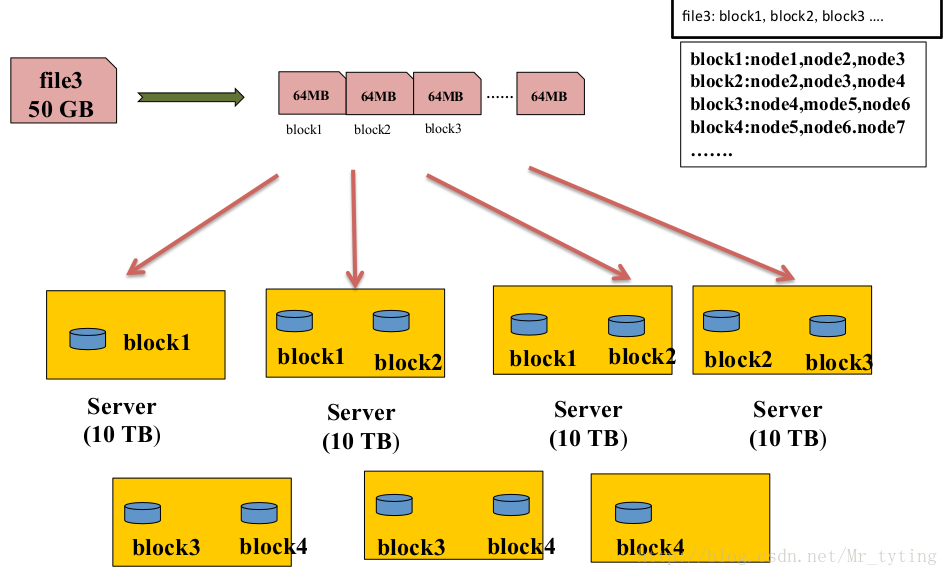
一個檔案傳到叢集中,先把這個檔案切分成等大,這裡假設是64MB的block。然後以塊為單位存到不同的節點上。再用兩張表來記錄,第一張表記錄這個檔案由多少block組成,注意這個有先後順序;第二張表記錄每個block在哪些節點上。有了這兩張表就很容易追蹤這個檔案是怎樣存的。使用者是感知不到檔案的切分和拼裝。
這種儲存方式有兩點好處:
①很容易做負載均衡:塊是等大的,一個節點最多比其他節點多存一個block。這樣每個節點的利用率差不多,不會存在一個節點利用率很大,而另一個節點利用率很小。
②很容易和上層的計算框架做結合:因為檔案以多個塊分在多個節點上,這裡我們假設起五十個任務來並行處理這些檔案,那麼這個五十個任務並行的跑在儲存這些檔案的節點上,這樣就分攤了每個節點的頻寬
HDFS 架構(master-slave架構)
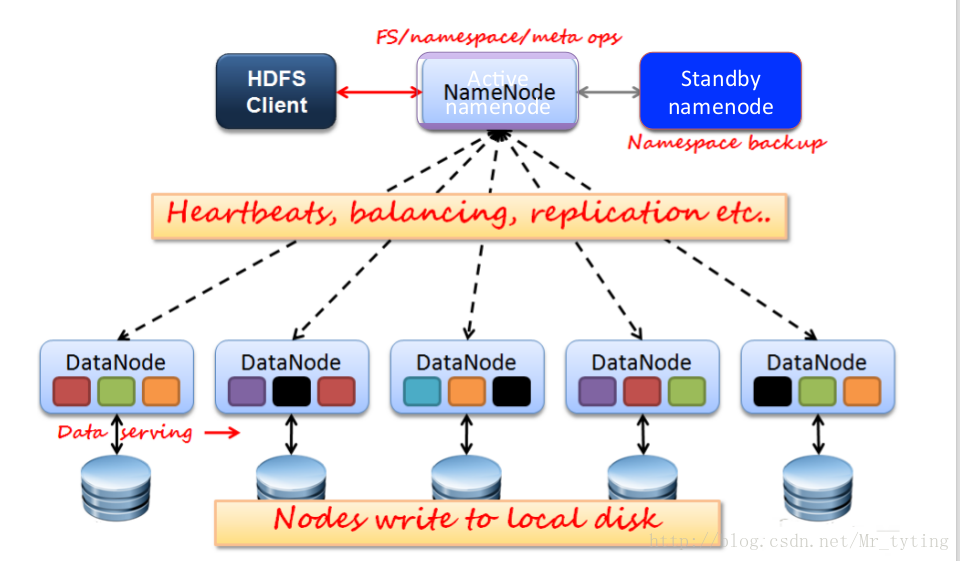
這裡面master就是namenode,slave就是這些datanode。namenode裡面存的就是這些block的元資訊,就是儲存上面的那兩張表。namenode有兩個,一個是active namenode,一個是standby namenode,一旦active namenode掛了,standby namenode就來接管他。datanode就是用來儲存實際的資料塊,datanode會定期的向namenode彙報心跳資訊,例如不斷告訴namenode我還活著,我儲存了多少資料塊等資訊。如果在指定的時間內沒有彙報資訊,那麼namenode會認為這個datanode掛了。
Active Namenode
- 主Master(只有一個)
- 管理HDFS的名稱空間(管理目錄樹,哪些檔案在哪些目錄下等)
- 管理資料塊對映資訊(每個檔案由哪些block構成,每個block存在哪個節點下)
- 配置副本策略
- 處理客戶端讀寫請求
Standby NameNode(定期同步namnode裡面的元資訊)
- NameNode 的熱備;
- 定期合併 fsimage 和fsedits ,推送給NameNode ;
- 當 Active NameNode 出現故障時,快速切換為新的 ActiveNameNode 。
Datanode
- Slave (有多個)
- 儲存實際的資料塊
- 執行行資料塊讀 / 寫
Client
- 檔案切分
- 與NameNode互動,獲取檔案位置資訊;
- 與DataNode互動,讀取或者寫入資料;
- 管理HDFS
訪問HDFS
standby namenode不是必須有的,比如在偽分散式中,只有一個節點,那麼就沒必要再弄個standby namenode。假設在線上環境,有五個節點,那麼可以搞個standby namenode,這時候建議每個節點部署datanode,兩個節點部署namenode,也就是說有兩個節點同時部署namenode和datanode,因為此時只有五個節點,namenode壓力不大,如果兩個節點僅僅部署namenode資源太浪費。
HA 與 Federation
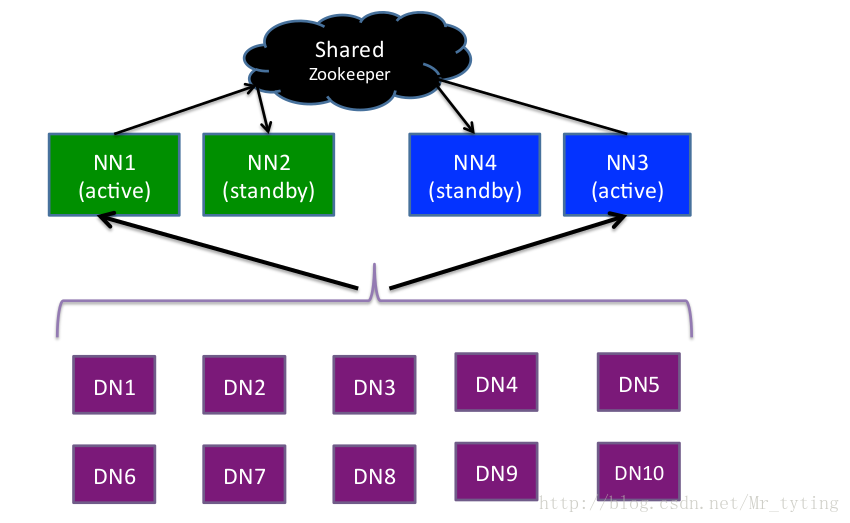
上圖中NN是namenode縮寫,DN是datanode縮寫,如果此時要管理的檔案數非常非常多,此時一對的namenode(active和standby,其實只有一個active namenode在管理,active namenode掛了standby namenode才會管理)就管理不了了,這時可以再搞一對namenode,相當於這對namenode管理這部分檔案,另外一對namenode管理另一部分的namenode。然後一對的namenode,裡面選誰做active namenode,誰做standby namenode呢?avtive namenode掛了怎麼切換到standby namenode呢?這個是有Zookeeper來管理的。有兩個namenode時需要Zookeeper做主從的選擇以及協調。
NameNode兩個重要檔案:
- fsimage:元資料映象檔案(儲存檔案系統的目錄樹)
- edits:元資料操作日誌(針對目錄樹的修改操作),被寫入共享儲存系統中 ,比如NFS、JournalNode
元資料映象:
- 記憶體中儲存一份最新的
- 記憶體中的映象=fsimage+edits
合併fsimage與edits
- Edits檔案過大將導致NameNode重啟速度慢
- Standby Namenode負責定期合併它們
HDFS 資料塊( block ):
檔案被切分成固定大小的資料塊
- 預設資料塊大小為128MB,可配置
- 若檔案大小不到128MB,則單獨存成一個block
- 一個block只能來自一個檔案
為何資料塊如此之大
- 資料傳輸時間超過尋道時間(高吞吐率)
資料越大,時間就不會浪費在尋道上,而是更多的用在資料傳輸上。便於大資料處理。
一個檔案儲存方式
- 按大小被切分成若干個block,儲存到不同節點上
- 預設情況下每個block有三個副本,注意儲存的粒度是block,而不是檔案
那麼為什麼是三個副本呢?為什麼不是兩個不是四個?兩個的話可靠性肯定比較低,兩個可不可靠取決於兩個節點同時掛的可能性高不高,通過實際的經驗知道,兩個節點同時掛的可能性很大。那麼如果四副本呢?其實三副本可靠性可以接受了,四副本增大了對儲存空間的要求,但是提高的可靠性並不多,所以三副本是對儲存空間要求和可靠性的一個折中。
HDFS 內部機制 — 寫流程:
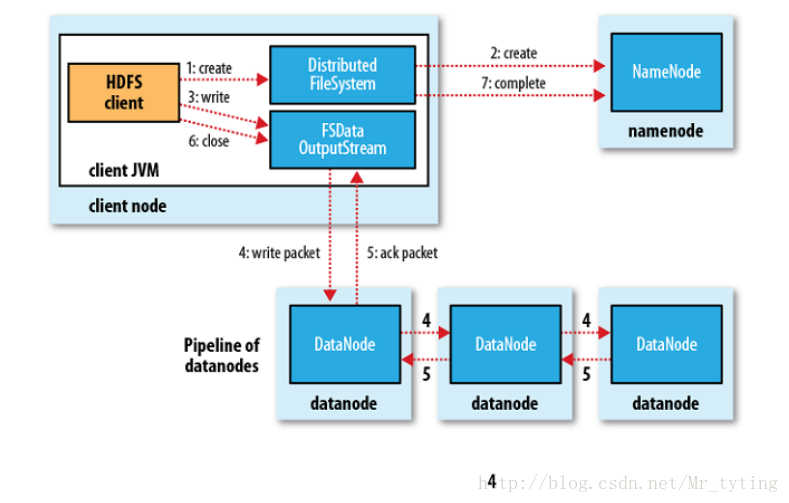
上圖中有四個節點,沒有部署standby namenode,當客戶端向namenode傳送一個寫的請求資訊,namenode收到寫請求會檢視他記憶體裡面的元資訊,看看存不存在這個目錄或檔案,如果存在就拒絕,如果不存在就接受。客戶端首先會把這個檔案切成多個block,先寫第一個block,寫的過程中和namenode通訊,領取三個datanode地址,就是要存三個副本的地址。首先客戶端會向第一個節點寫一個小的package(不是128MB,這裡假設是64k),並且會源源不斷的寫,同時的話,第一個節點會源源不斷的把這個小的package傳送到其他的副本節點。直到寫完一個block。
HDFS 內部機制 — 讀流程:
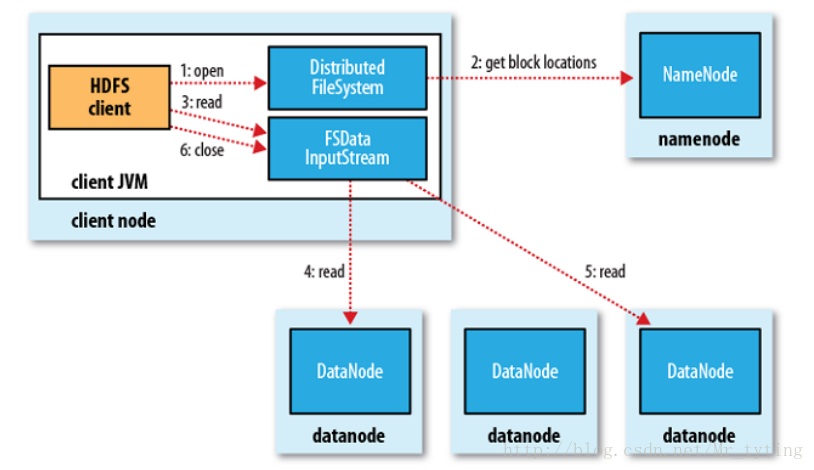
同樣客戶端向namenode傳送一個讀的請求,namenode檢視記憶體裡資訊元,如果檔案或目錄存在,則可讀,然後向其返回三個block地址。客戶段根據地址讀取檔案,然後再讀取第二個block直到把檔案讀完,客戶端會把這些block(根據讀取的先後順序)拼裝成一個完整的檔案,返回給使用者。
HDFS 內部機制 — 物理拓撲(也即副本放置策略)
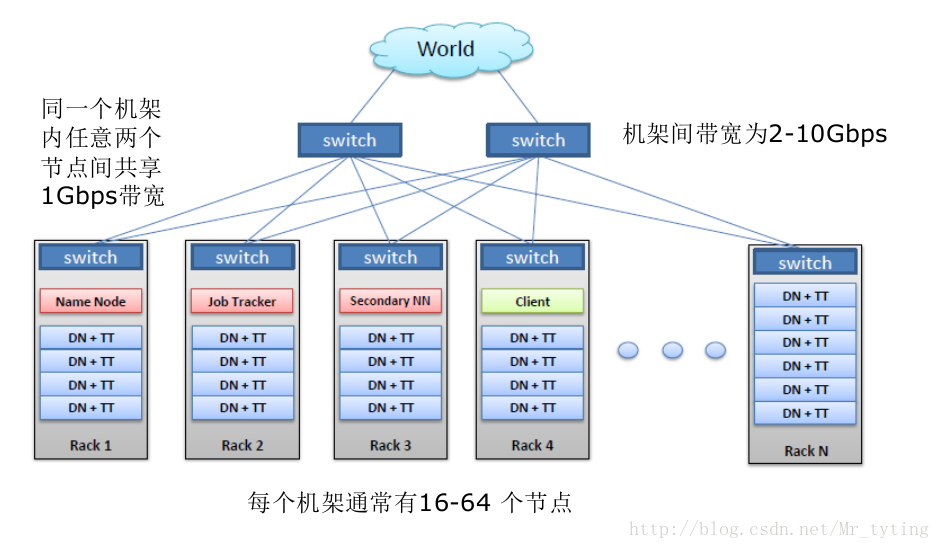
讀資料儘量在一個機櫃上讀,在不同的機櫃之間讀資料要通過交換機,延遲比較高。
同一個機櫃內兩個節點同時出故障的概率要比不同機櫃內兩個節點出故障高很多。因為同一個機櫃的兩個節點共享一個交換機,物理上許多東西都是共享的,那麼同時出故障概率要高。
HDFS 內部機制 — 副本放置策略
一個檔案劃分成多個block,每個block存多份,如何為每個block選擇節點儲存這幾份資料?
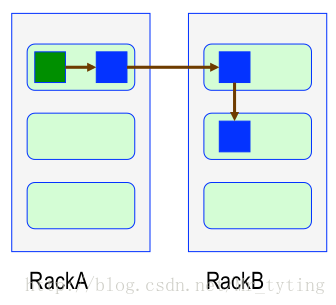
- 副本1: 同Client的節點上
- 副本2: 不同機架中的節點上
- 副本3: 與第二個副本同一機架的另一個節點上
- 其他副本:隨機挑選
那麼可能會有人問,為什麼不把三個副本放在三個不同的機架上?這樣容錯能力豈不是更強?上面已經說了不同機架之間的讀寫效率低,因為要通過一個交換機,而交換機的速率可能有瓶頸。所以把三個副本放在兩個不同的機架上基於效能和可靠性的一個折中。
HDFS 內部機制 — 可靠性策略
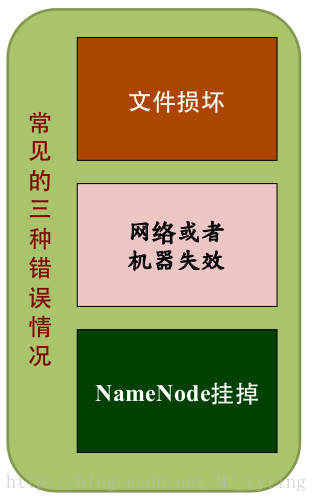
檔案完整性
- CRC32校驗
- 用其他副本取代損壞檔案
Heartbeat
- Datanode 定期向Namenode發heartbeat
datanode會定期向namenode傳送心跳,namenode會指定datanode的狀態,如果在指定時間內沒收到datanode心跳,namenode就會認為datanode已死亡,將其標記為死亡,然後把儲存在這個死亡datanode上的資料塊在其他節點上進行重構。始終保證每個資料塊的副本數為3或者是設定的副本數。
元資料資訊
- FSImage(檔案系統映象)、Editlog(操作日誌)
- 多份儲存
- 主備NameNode實時切換
HDFS程式設計方法
HDFS 訪問方方式:
- HDFS Shell命令
- HDFS Java API
- HDFS REST API
- HDFS Fuse:實現了fuse協議
- HDFS lib hdfs:C/C++訪問介面
- HDFS 其他語言程式設計API
使用thrift實現
HDFS Shell 命令
檔案操作命令:
將本地檔案上傳到HDFS上
hdfs dfs -put /local/data /hdfs/data刪除檔案/目錄
hdfs dfs -rm /hdfs/data建立目錄
hdfs dfs ‐mkdir /hdfs/data
HDFS Shell 命令 — 管理命令
- 列印拓撲圖命令:哪些節點在哪些機架上
hdfs dfsadmin -printTopology
HDFS Shell 命令 — 管理指令碼:
在sbin目錄下
- start-all.sh
- start-dfs.sh
- start-yarn.sh
- hadoop-deamon(s).sh
單獨啟動某個服務:
- hadoop-deamon.sh start namenode
- hadoop-deamons.sh start namenode(通過SSH登入到各個節點)
HDFS Shell 命令 — 文檔案管理命令 fsck:
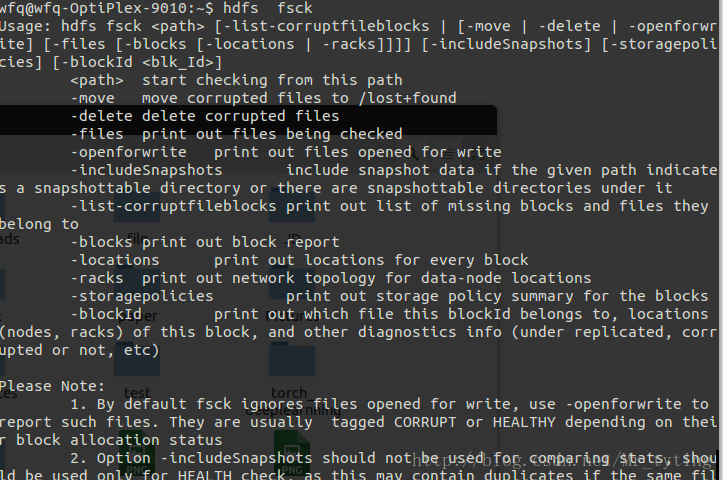
- 檢查hdfs中檔案的健康狀況
- 查詢缺失的塊以及過少或過多副本的塊
- 檢視一個檔案的所有資料塊位置
刪除損壞的資料塊
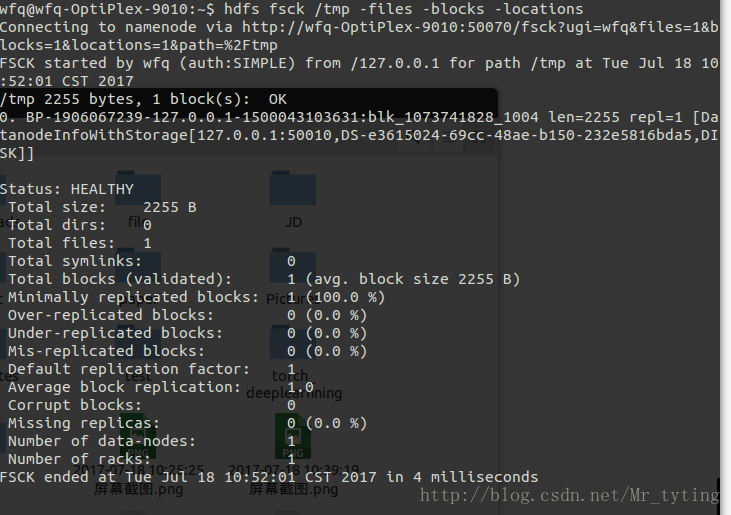
例如檢視/tmp檔案的block的狀態資訊。
HDFS Shell 命令 — 資料均衡器 balancer:
資料塊重分佈
start-balancer.sh -threshold < percentage of disk capacity >percentage of disk capacity(當節點之間負載不均衡時,比如新買了幾臺電腦,把負載很高的節點block搬運到其他節點)
HDFS達到平衡狀態的磁碟使用率偏差值
值越低各節點越平衡,但消耗時間也更長
HDFS Shell 命令 — 設定目目錄份額:
限制一個目錄最多使用磁碟空間
hadoop dfsadmin -setSpaceQuota 1t /user/username 這個目錄下最多隻能使用1t空間限制一個目錄包含的最多子目錄和檔案數目
hadoop dfsadmin -setQuota 10000 /user/username
HDFS Shell 命令 — 增加 / 移除節點:
加入新的datanode
- 步驟1:將已存在datanode上的安裝包(包括配置檔案等)拷貝到新datanode上;
- 步驟2:啟動新datanode:
hadoop-deamon.sh start datanode
移除舊datanode
- 步驟1:將datanode加入黑名單,並更新黑名單,在NameNode上,將datanode的host或者ip加入配置選項dfs.hosts.exclude指定的檔案中
- 步驟2:移除datanode
hadoop dfsadmin -refreshNodes
HDFS Java API 介紹
Configuration類:該類的物件封裝了配置資訊,這些配置資訊來自core-*.xml;
FileSystem類:檔案系統類,可使用該類的方法對檔案/目錄進行操作。一般通過FileSystem的靜態方法get獲得一個檔案系統物件;
FSDataInputStream和FSDataOutputStream類:HDFS中的輸入輸出流。分別通過FileSystem的open方法和create方法獲得。
以上類均來自java包:org.apache.hadoop.fs
HDFS Java 程式舉例
將本地檔案拷貝到HDFS上
Configuration config = new Configuration();//建立一個配置檔案,從環境變數裡讀取hdfs-site.xml來獲取hdfs相關配置,如果沒有會使用預設的,就是本地的hdfs配置。
FileSystem hdfs = FileSystem.get(config);//獲取控制代碼
//建立兩個檔案目錄
Path srcPath = new Path(srcFile);
Path dstPath = new Path(dstFile);
hdfs.copyFromLocalFile(srcPath, dstPath);// 呼叫hdfs把新建立的兩個檔案拷貝過去。建立HDFS檔案
//byte[] buff – 檔案內容
Configuration config = new Configuration();
FileSystem hdfs = FileSystem.get(config);
Path path = new Path(fileName);
FSDataOutputStream outputStream = hdfs.create(path);
outputStream.write(buff, 0, buff.length);關鍵操作步驟:
- 在建立的目錄內用命令列建立一個maven專案。
- 再將專案匯入到eclipse裡面。
- 在pom.xml裡面增加hadoop依賴。
例如:注意我的hadoop版本是2.7.3
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency> 然後進入這個maven專案目錄內使用命令:mvn clean install,下載依賴。
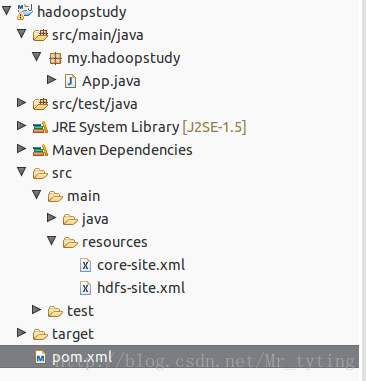
5.在src/main/java目錄下建立一個App.java檔案:
package my.hadoopstudy;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class App {
public static void testMkdirPath(String path) throws Exception {
FileSystem fs = null;
try {
System.out.println("Creating " + path + " on hdfs...");
Configuration conf = new Configuration();
// First create a new directory with mkdirs
Path myPath = new Path(path);
fs = myPath.getFileSystem(conf);
fs.mkdirs(myPath);
System.out.println("Create " + path + " on hdfs successfully.");
} catch (Exception e) {
System.out.println("Exception:" + e);
} finally {
if(fs != null)
fs.close();
}
}
public static void testDeletePath(String path) throws Exception {
FileSystem fs = null;
try {
System.out.println("Deleting " + path + " on hdfs...");
Configuration conf = new Configuration();
Path myPath = new Path(path);
fs = myPath.getFileSystem(conf);
fs.delete(myPath, true);
System.out.println("Deleting " + path + " on hdfs successfully.");
} catch (Exception e) {
System.out.println("Exception:" + e);
} finally {
if(fs != null)
fs.close();
}
}
public static void main(String[] args) {
try {
//String path = "hdfs:namenodehost:8020/test/mkdirs-test";
String path = "/test/mkdirs-test";
testMkdirPath(path);
//testDeletePath(path);
} catch (Exception e) {
System.out.println("Exceptions:" + e);
}
System.out.println("timestamp:" + System.currentTimeMillis());
}
}上面程式碼中就是用在本地對HDFS進行檔案操作,比如建立檔案,刪除檔案,寫檔案等操作等。
6.如果在eclipse裡面直接run as java Application,那麼是在本地生成這個檔案。
7.如果想在hadoop節點上生成檔案,那麼可以把這個專案打成jar包,然後在節點上用命令hadoop jar xx.jar。因為這個時候會把所有的hadoop環境變數放進去執行。
HDFS優化小技巧
HDFS 優化小小技巧:原始日日誌儲存格式選擇
文字檔案
- 不便於壓縮,選擇合適的壓縮演算法很重要;
- 不建議將日誌直接存成文字格式
SequenceFile
- 二進位制格式,便於壓縮,壓縮格式作為元資訊存到檔案中;
- 建議採用該格式儲存原始日誌
- flume預設的輸出格式就是SequenceFile
HDFS 優化小技巧:小檔案優化
合併成大檔案
合併成Sequence file
用Hadoop Archive打包儲存到key/value系統中
HBase
TFS(Tao Bao FileSystem)
分散式日誌收集系統:檔案管理模組
日誌分析系統: 文檔案儲存模組注意事項
資料分割槽
年/月/日資料壓縮
較少儲存空間資料儲存格式選擇
原始日誌儲存格式選擇Sequence file(便於壓縮),而不是文字格式
原始使用者資訊和商品資訊可採用列式儲存格式(ORC或Parquet)儲存
日誌分析系統:資料格式選擇
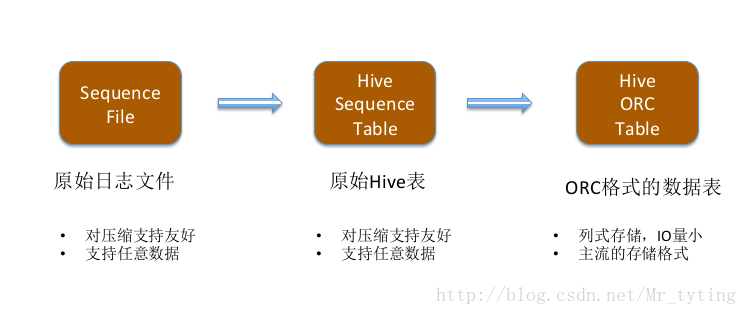
日誌分析系統:增大“熱點檔案”的副本數
通過程式API修改
FileSystem fs = FileSystem.get(path, conf);
fs.setReplication(path, (short) 4);//預設是3通過配置引數修改
在hdfs-site.xml修改dfs.replication: 4,這樣的話所有檔案的block都是4,故不建議使用。通過命令列
增加檔案的副本數:hadoop dfs -setrep -w 4 /path/to/file // 這裡面file是一個檔案
遞迴增加目錄下檔案的的副本數:hadoop dfs –setrep -R -w 4 /path/to/file // file是一個目錄。
日誌分析系統:分析冷熱資料:
“冷熱”資料
冷資料:過去半年內沒訪問過的資料
冷資料可進行特殊處理,包括高壓縮,小檔案合併等找出“冷熱”資料
hdfs oiv -i /home/hadoop/data/hdfs/name/current/fsimage_0000000000001619538 -p XML -o fsimage.xml找出上次訪問時間為半年之前的檔案:< atime>1475047293212< /atime>
就是利用hdfs裡面的命令oiv命令將hdfs裡面的一些元資訊(故oiv後面要設定一個路徑,就是hadoop安裝目錄裡面的配置檔案hdfs-site.xml裡面配置的dfs.namenode.name.dir對應的value值就是儲存元資訊的位置資訊)拉出來然後儲存為xml格式,然後xml檔案內有一個atime就是上一次訪問的時間。
日誌分析系統:處理“冷”資料
高壓縮比演算法進行壓縮
Gzip或bzip2合併小檔案
使用MapReduce實現-
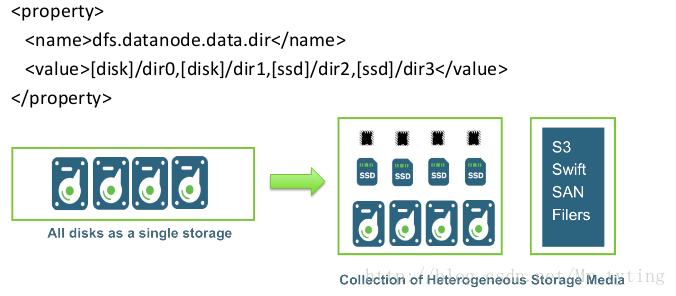
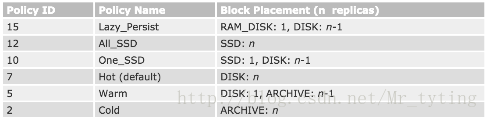
每個節點是由多種異構儲存介質構成的
可以在datanode節點上配置每個盤的型別,比如是disk型別還是ssd型別。
然後可以使用命令:
hdfs storagepolicies -setStoragePolicy -path < path> -policy < policy>
對指定路徑下path的目錄指定他的儲存策略policy。
比如All_SSD,表示這個目錄下檔案都採用SSD。