
Hadoop 原理總結
一、Hadoop技術原理
Hdfs主要模組:NameNode、DataNode
Yarn主要模組:ResourceManager、NodeManager
常用命令:
1)用hadoop fs 操作hdfs網盤,使用Uri的格式訪問(URI格式:secheme://authority/path ,預設是hdfs://namenode:namenode port /parent path / child , 簡寫為/parent path / child)
2)使用start-dfs.sh啟動hdfs
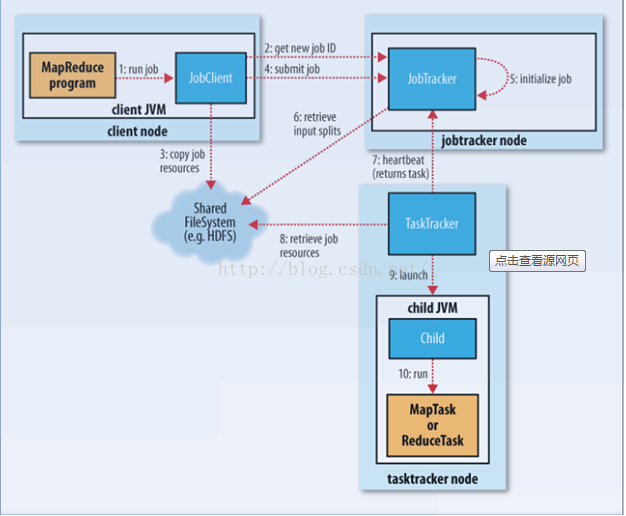
1 MR執行流程:
1)客戶端提交Mr 的jar包程式給JobClient
2)JobClient通過RPC和JobTracker 進行通訊返回新的JOB ID 和路徑
3)Client將jar包寫入到HDFS當中(提交10份)
4)開始提交任務(任務的描述資訊,不是Jar),有任務的詳細資訊
5)JobTracker進行初始化任務,把任務放到排程器中,在一臺機器上
6)讀取HDFS上的要處理的檔案,開始計算輸入分片
7)TaskTracker通過心跳機制領取任務
8)下載所需要的jar,配置檔案等
9)TaskTracker啟動一個Java child子程序
10)將結果寫入HDFS 當中
二、HDFS主要模組及執行原理
Hdfs主要模組:
Hdfs的塊的實際儲存位置:tmpHdfsPath + /dfs/data/current/BP-126879239-192.168.1.213-1648462/cureent/finalized中,儲存倆檔案一個是塊,一個是塊的描述資訊,即:blk_1073434 、blk_1073434_1015.meta
1)NameNode:
功能:是整個檔案系統的管理節點。維護整個檔案系統的檔案目錄樹,檔案/目錄的元資料和每個檔案對應的資料塊列表。接收使用者的請求。
儲存:儲存DataNode中各個檔案的基本元資料資訊,其中元資料儲存是瓶頸,因為元資料需要儲存2份,一份存在記憶體中(記憶體中有3個檔案,fsimage,edits,記憶體中的metaData),一份序列化到硬碟上,但是記憶體空間有限,如果不停的儲存幾K的元資料,容易導致記憶體的不足,同時由於不停的從記憶體序列化到硬碟,也佔CPU。
結構:
fsimage元資料映象檔案:儲存某一段時間的NameNode的記憶體元資料資訊(fsimage.ckpt檔案)
edits:操作日誌檔案。(上傳檔案的過程中,不停的向edits寫日誌,不斷的追加,直到成功後,記憶體的元資料才會更新元資料。edits都是從0開始的)
fstime:儲存最近一次checkpoint的時間(checkpoint跟檔案的一鍵還原點意義相同)
以上檔案都儲存在Linux系統中,edits日誌是實時儲存在磁碟,但edits與fsimage是v2.0版本,才是實時儲存,2.0沒有SecondaryNameNode。
2)DataNode:
以下針對Hadoop V 1.0 、V 0 的版本
SecondaryNameNode
功能:是HA(高可用性)的一個解決方案,是備用映象,但不支援熱備
執行過程:
1)Secondary通知NameNode切換edits檔案
2)Secondary從NameNode中獲取fsimage和edits(通過http),Secondary獲取檔案後,NameNode會生成新的edits.new檔案,該檔案從0開始。
3)Secondary將fsimage載入記憶體,然後開始合併
4)Secondary將新生成的fsimage,在本地儲存,並將其推送到NameNode
5)NameNode替換舊的映象。
說明:SecondNameNode預設是安裝在NameNode節點上,但是這樣不安全。
Yarn主要模組:ResourceManager、NodeManager
常用命令:
1、用hadoop fs 操作hdfs網盤,使用Uri的格式訪問(URI格式:secheme://authority/path ,預設是hdfs://namenode:namenode port /parent path / child , 簡寫為/parent path / child)
2、使用start-dfs.sh啟動hdfs
hbase行鍵設計原理~如何進行復雜表的查詢~redis原理~hdfs原理~job提交過程~hbase,hive,mapreducejvm的優化方式~資料如何採集~叢集的動態新增去除節點方法!
三、MapReduce執行原理
1、Map過程簡述:
1)讀取資料檔案內容,對每一行內容解析成<k1,v1>鍵值對,每個鍵值對呼叫一次map函式
2)編寫對映函式處理邏輯,將輸入的<k1,v1>轉換成新的<k2,v2>
3)對輸出的<k2,v2>按reducer個數和分割槽規則進行分割槽
4)不同的分割槽,按k2進行排序、分組,將相同的k2的value放到同一個集合中
5)(可選)將分組後的資料重新reduce歸約
2、reduce處理過程:
1)對多個Map的輸出,按不同分割槽通過網路將copy到不同的reduce節點
2)對多個map的輸出進行排序,合併,編寫reduce函式處理邏輯,將接收到的資料轉化成<k3,v3>
3)將reduce節點輸出的資料儲存到HDFS上
說明:
1)Mapper Task 是邏輯切分。因為Maper記錄的都是block的偏移量,是邏輯切分,但相對於記憶體中他確實是物理切分,因為每個Mapper都是記錄的分片段之後的資料。
2)shuffle是物理切分。MapReduce的過程是倆過程需要用到Shuffle的,1個mapper的Shufflle,1個多個reduce的Shuffle,一般每個計算模型都要多次的reduce,所以要用到多次的Shuffle。.
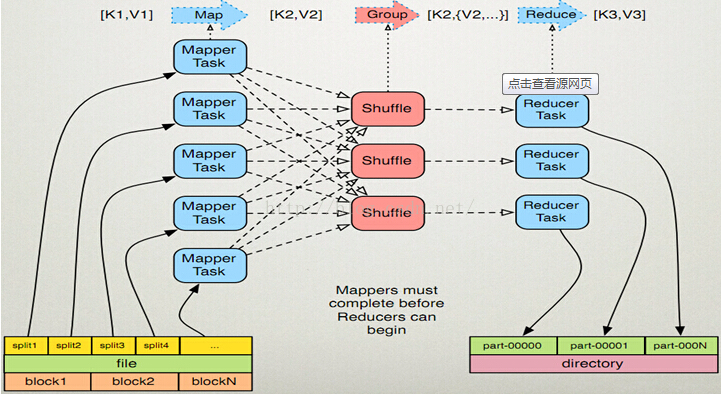
MapReduce原理圖
正常HDFS儲存3份檔案,Jar包預設寫10份,NameNode通過心跳機制領取HDFS任務,執行完畢後JAR包會被刪除。
Map端處理流程分析:
1) 每個輸入分片會交給一個Map任務(是TaskTracker節點上執行的一個Java程序),預設情況下,系統會以HDFS的一個塊大小作為一個分片(hadoop2預設128M,配置dfs.blocksize)。Map任務通過InputFormat將輸入分片處理成可供Map處理的<k1,v1>鍵值對。
2) 通過自己的Map處理方法將<k1,v1>處理成<k2,v2>,輸出結果會暫時放在一個環形記憶體緩衝(緩衝區預設大小100M,由mapreduce.task.io.sort.mb屬性控制)中,當緩衝區快要溢位時(預設為緩衝區大小的80%,由mapreduce.map.sort.spill.percent屬性控制),會在本地作業系統檔案系統中建立一個溢位檔案(由mapreduce.cluster.local.dir屬性控制,預設${hadoop.tmp.dir}/mapred/local),儲存緩衝區的資料。溢寫預設控制為記憶體緩衝區的80%,是為了保證在溢寫執行緒把緩衝區那80%的資料寫到磁碟中的同時,Map任務還可以繼續將結果輸出到緩衝區剩餘的20%記憶體中,從而提高任務執行效率。
3) 每次spill將記憶體資料溢寫到磁碟時,執行緒會根據Reduce任務的數目以及一定的分割槽規則將資料進行分割槽,然後分割槽內再進行排序、分組,如果設定了Combiner,會執行規約操作。
4) 當map任務結束後,可能會存在多個溢寫檔案,這時候需要將他們合併,合併操作在每個分割槽內進行,先排序再分組,如果設定了Combiner並且spill檔案大於mapreduce.map.combine.minspills值(預設值3)時,會觸發Combine操作。每次分組會形成新的鍵值對<k2,{v2...}>。
5) 合併操作完成後,會形成map端的輸出檔案,等待reduce來拷貝。如果設定了壓縮,則會將輸出檔案進行壓縮,減少網路流量。是否進行壓縮,mapreduce.output.fileoutputformat.compress,預設為false。設定壓縮庫,mapreduce.output.fileoutputformat.compress.codec,預設值org.apache.hadoop.io.compress.DefaultCodec。
Reduce端處理流程分析:
1) Reduce端會從AM那裡獲取已經執行完的map任務,然後以http的方法將map輸出的對應資料拷貝至本地(拷貝最大執行緒數mapreduce.reduce.shuffle.parallelcopies,預設值5)。每次拷貝過來的資料都存於記憶體緩衝區中,當資料量大於緩衝區大小(由mapreduce.reduce.shuffle.input.buffer.percent控制,預設0.7)的一定比例(由mapreduce.reduce.shuffle.merge.percent控制,預設0.66)時,則將緩衝區的資料溢寫到一個本地磁碟中。由於資料來自多個map的同一個分割槽,溢寫時不需要再分割槽,但要進行排序和分組,如果設定了Combiner,還會執行Combine操作。溢寫過程與map端溢寫類似,輸出寫入可同時進行。
2) 當所有的map端輸出該分割槽資料都已經拷貝完畢時,本地磁碟可能存在多個spill檔案,需要將他們再次排序、分組合並,最後形成一個最終檔案,作為Reduce任務的輸入。此時標誌Shuffle階段結束,然後Reduce任務啟動,將最終檔案中的資料處理形成新的鍵值對<k3,v3>。
3) 將生成的資料<k3,v3>輸出到HDFS檔案中。
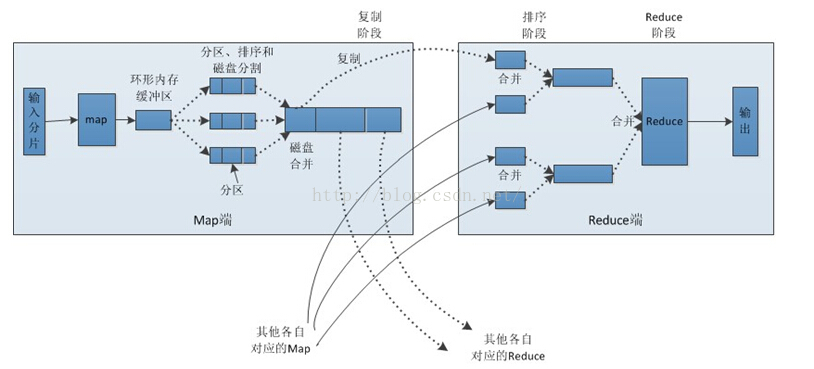
Map與Reduce執行過程圖
三 Hadoop序列化--Writable
序列化就是將記憶體當中的資料序列化到位元組流中,
他實現了WritableComparable 介面,並繼承了Writable(Write和ReadFile需要被實現)和Compare介面
1 特點:
1 )緊湊:高校使用儲存空間
2 )快速:讀寫資料的額外開銷小
3 )可擴充套件:可透明的讀取老格式的資料
4 )互操作:支援多語言的互動
說明:JAVA 的序列化對繼承等的結構都儲存了,而對hadoop用不著,只需要儲存字元就可以,所以有自己的機制。