
基於 CNN的年齡和性別檢測
自2012年深度學習火起來後,AlexNet,vgg16,vgg19,gooGleNet,caffeNet,faster RCNN等,各種模型層出不群,頗有文藝復興時的形態。
在各種頂會論文中,對年齡和性別的檢測的論文還是比較少的。而本文將要講解的是2015年的一篇cvpr,Age and Gender Classification using Convolutional Neural Networks。官方連結為
理論基礎:
其整體結構如下圖所示,輸入一幅圖片,然後經過3個卷基層,2個全連結層,最後經過svm分類器分類,輸出相應的結果。
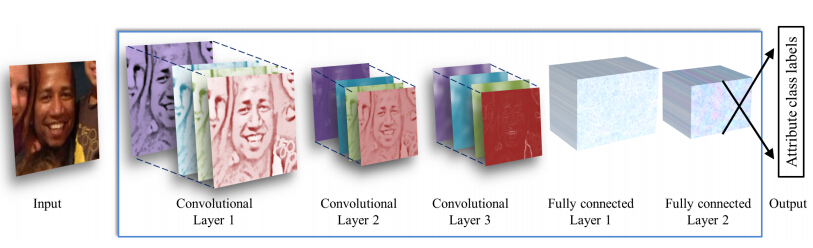
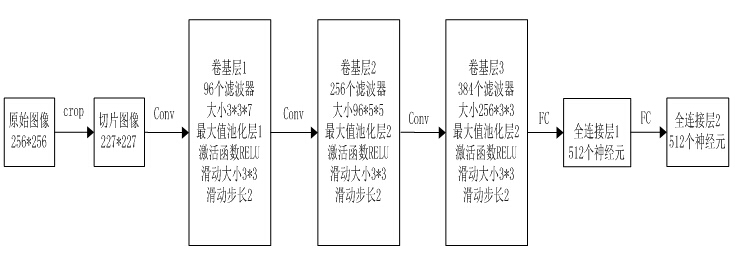
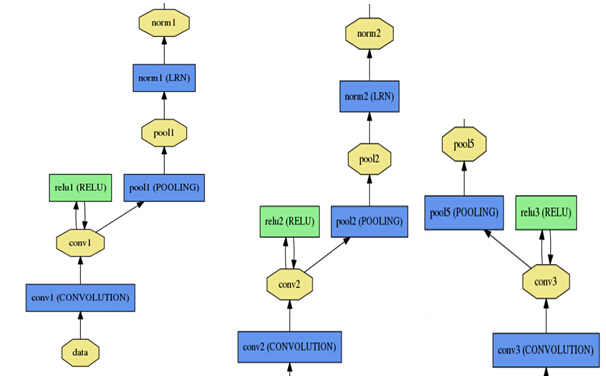
詳細結構如下圖所示,其中norm層為了提高模型的泛化能力,drop層是為了防止過擬合。
其中左中右分別為第一二三個卷基層,下面的為第六七八個全連線層。

程式執行:
可以寫一個簡單的shell指令碼來進行執行測試,touch一個.sh檔案,隨便起個名字,輸入如下的指令碼,然後命令列執行就可以輸出結果。其中路徑名換成自己電腦的實際路徑名。
#!/bin/bash #directed by watersink([email protected]) echo "Begin gender....." ./build/examples/cpp_classification/classification.bin \ models/cnn_age_gender/deploy_gender.prototxt \ models/cnn_age_gender/gender_net.caffemodel \ data/cnn_age_gender/mean.binaryproto \ data/cnn_age_gender/genderlabels.txt \ data/cnn_age_gender/example_image.jpg echo "Begin age....." ./build/examples/cpp_classification/classification.bin \ models/cnn_age_gender/deploy_age.prototxt \ models/cnn_age_gender/age_net.caffemodel \ data/cnn_age_gender/mean.binaryproto \ data/cnn_age_gender/agelabels.txt \ data/cnn_age_gender/example_image.jpg echo "Done.
classification.bin為caffe自帶的二進位制檔案,用於實現分類。
deploy_gender.prototxt,deploy_age.prototxt分別為性別,年齡部署或者測試時候的模型檔案
gender_net.caffemodel,age_net.caffemodel分別為性別,年齡訓練好的權值檔案
mean.binaryproto,為訓練的樣本的均值檔案,減均值時使用,可以達到更好的檢測效果
genderlabels.txt,agelabels.txt為性別,年齡的標籤檔案,具體內容如下
genderlabels.txt中的內容:male 1
female 0
agelabels.txt中的內容:
0-2 0
4-6 1
8-13 2
15-20 3
25-32 4
38-43 5
48-53 6
60- 7
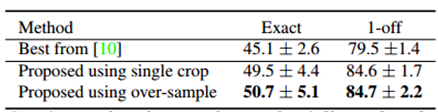
實驗結果:
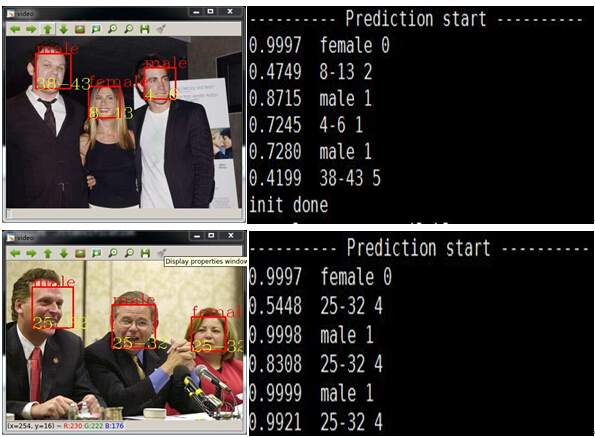
性別識別率:

年齡識別率:
訓練自己的模型:
論文的原作者給出了自己的5-folder訓練檔案,首先我們對原作者的訓練資料進行分析。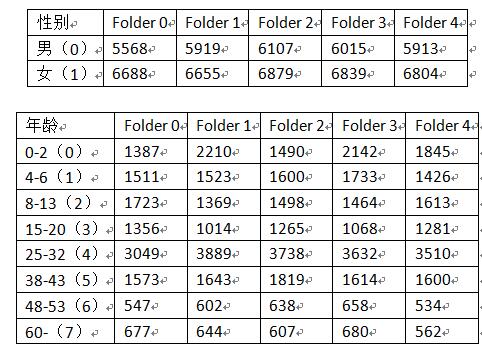
通過上面的資料可以看出,性別資料反面基本是1:1比例進行的。而年齡方面並沒有執行大概的1:1:1:1:1:1:1:1比例,而是3:3:3:3:6:3:1:1,對於這樣的訓練比例,我個人認為是很不科學和合理的,所謂的mini-batch,應該是每個batch中的屬性和整體的基本是一樣的才可以。簡單的說,任意給一張影象,這張影象中人物屬於哪一個年齡段是都有可能的,也就是是平均概率的。(個人見解,如有錯誤,希望大家指正)
下面通過一個簡單的c++程式來獲得和作者一樣的txt檔案。
int main()
{
vector<string>file_folder;
file_folder.push_back("fold_0_data.txt");
file_folder.push_back("fold_1_data.txt");
file_folder.push_back("fold_2_data.txt");
file_folder.push_back("fold_3_data.txt");
file_folder.push_back("fold_4_data.txt");
ofstream file_stream_gender_out("gender.txt", ios::app);
ofstream file_stream_age_out("age.txt", ios::app);
char buffer[500];
char str1[50], str2[50], str3[50], str4[50], str5[50], str6[50];
for (int i = 0; i < file_folder.size();i++)
{
ifstream file_stream_in(file_folder[i]);
file_stream_in.getline(buffer, 400);//提取標題
while (!file_stream_in.eof())
{
file_stream_in.getline(buffer,400);
sscanf(buffer, "%s %s %s %s %s %s", &str1, &str2, &str3, &str4, &str5, &str6);
string tmp1 = str3, tmp2 = str2;
string address = "F:\\MydataSet\\Adience\\aligned\\landmark_aligned_face." + tmp1 + "." + tmp2;
Mat image = imread(address);
if (image.data)
{
if (str4[0] == '(')
file_stream_age_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str4 << " " << str5 << endl;
if (strcmp(str6, "f") == 0 || strcmp(str6, "m") == 0 )
file_stream_gender_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str6<<endl;
else
{
if(strcmp(str5, "f") == 0 || strcmp(str5, "m") == 0)
file_stream_gender_out << "Adience/" << "landmark_aligned_face." << str3 << "." << str2 << " " << str5 << endl;
}
}
}
file_stream_in.close();
}
file_stream_gender_out.close();
file_stream_age_out.close();
return 0;
}
程式執行結束後,將會生成age.txt和gender.txt
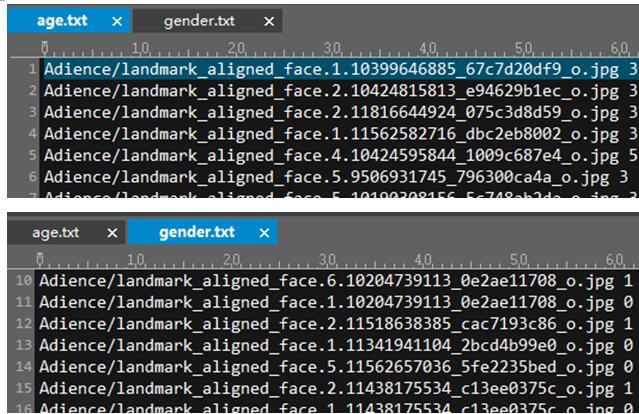
有了這2個檔案就可以進行相應的訓練工作了。當然為了得到更好的效果,可以考慮以下3點建議。
(1)對txt中的資料平均分配,不要好多相同的標籤在一起,如果不這樣做的話,需要在輸入層設定shuffle,同樣可以達到相同的效果。
(2)增加一定的樣本,使得年齡的每一個階段數量都大致相同
(3)將影象縮放到256*256,並做aligement
本人處理後資料如下圖所示,大小256*256,做了aligement

將cafferoot/examples/imagenet/ (cafferoot為自己的caffe的根目錄)下的create_imagenet.sh,
make_imagenet_mean.sh,train_caffenet.sh複製到自己的工程下,分別改名為,create_age.sh,make_age_mean.sh,train_age.sh,再複製一份,改名為,create_gender.sh,make_gender_mean.sh,train_gender.sh,並對其中的引數做相應的修改。(如果這一步有疑問,請留言)
年齡的訓練:
執行create_age.sh,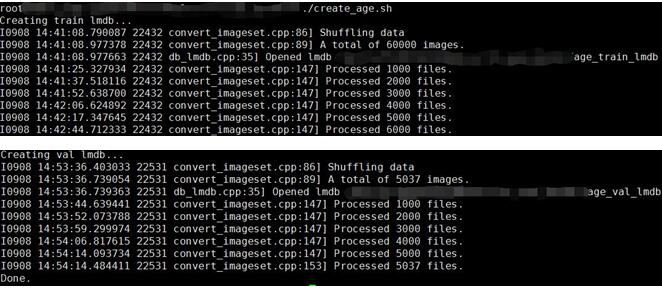
執行,make_age_mean.sh,

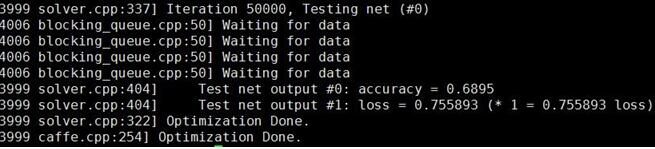
執行,train_age.sh,可以看到得到了68.95%的識別率
性別的訓練:
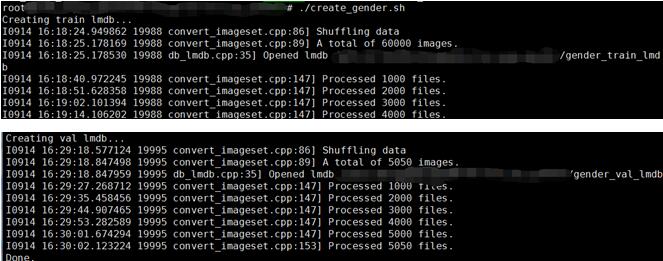
執行create_gender.sh,
執行,make_gender_mean.sh,

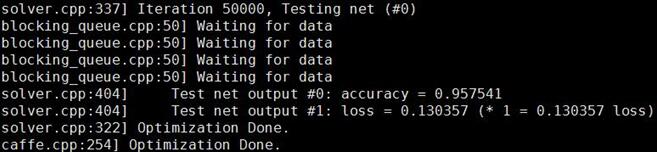
執行,train_gender.sh,可以看到得到了95.75%的識別率
本人實際在ubuntu14.04+corei7cpu+TitanX上跑的cpu進行年齡或者性別判斷的時間為150ms左右,gpu的時間為2-3ms左右。
在windows7+XeonE3上測試,cpu+debug為120ms左右,cpu+release為30ms左右。
歡迎大家指證與交流……