
論文翻譯------Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches
原文介紹了一種基於深度學習的密集匹配方法MC-NET,是第一篇將深度學習引入密集匹配方面的文章。
**********************************************************手動分割線****************************************************************************
標題:基於卷積神經網路的影象立體匹配
摘要:我們展示了一種從糾正後的立體像對中提取出深度資訊的方法。我們的方法關注於大多數立體匹配方法的第一個步驟:匹配代價計算。我們通過使用卷積神經網路學習小影象塊上的相似性度量來解決該問題。通過構建具有相似和不相似的像對的示例的二元分類資料集,以監督的方式執行訓練。我們測試了兩個不同的網路結構:一個為了計算速度做了調整,一個為了計算精度做了調整。卷積神經網路的輸出被用來作為立體匹配代價的初值。緊接著是一系列的後處理步驟:基於交叉的成本聚合(這個地方不知道翻譯正確沒有),半全域性匹配,左右一致性檢驗,亞畫素增強,中值濾波器,和雙邊濾波器。我們在KITTI2012,KITTI2015和Middubury三個資料集上對我們的方法進行了測試,結果顯示該方法在三個資料集上的表現都優於其他的演算法。
關鍵詞:立體,匹配代價,相似度學習,監督學習,卷積神經網路
1、簡介
考慮這樣的問題:通過獲得的兩張相機拍攝的在不同的水平方向位置的影像,我們希望能夠計算左影像上的每個畫素的視差。視差是指一個物體在左右影像上的水平位置的差異(這裡的影像已經經過了核線糾正),例如,一個物體在左影像上的位置是(x,y),那麼這個物體在右影像上的位置就是(x-d,y)。如果我們知道一個物件的視差,我們就可以計算這個物件的深度z通過如下的簡單公式。
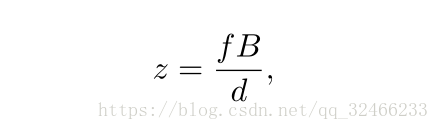
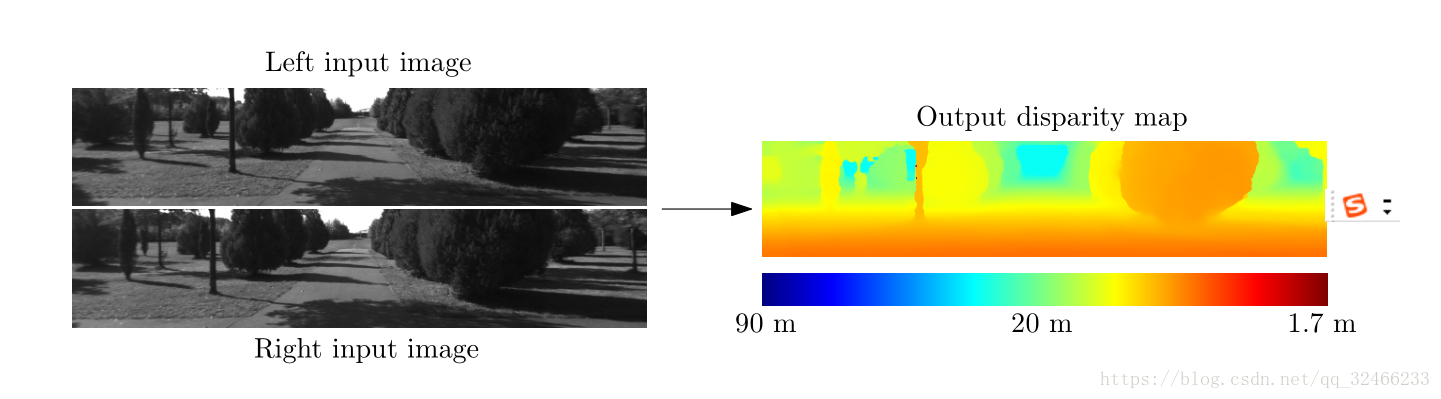
主要區別在於物體的水平位置(其他差異是由於
反射,遮擋和透視扭曲)。 請注意,物體更接近
相機比遠處的物體有更大的差異。 輸出是一個
右側顯示密集的視差圖,較暖的顏色代表較大
視差值(和較小的深度值)。
其中,f是相機的焦距,B是相機中心之間基線的長度。所描述的立體匹配問題在諸如以下的許多領域中是重要的
自動駕駛,機器人,中間檢視生成和3D場景重建。根據Scharstein和Szeliski(2002)的分類法,一種典型的立體演算法
包括四個步驟:匹配成本計算,匹配成本聚合,優化和視差細化。繼Hirschmüller和Scharstein(2009)之後,我們將典型的立體匹配演算法的前兩步統一為計算匹配代價,而後兩個步驟稱之為立體匹配方法。本文工作的重點就是計算出優良的匹配代價。
我們訓練一個卷積神經網路在一系列的立體像對當中 (LeCun et al., 1998),這些立體像對的真實視差是已知的。(例如,通過LIDAR來獲得真實的視差)。這個卷積神經網路的輸出被用來初始化匹配成本。接下來,我們進行的一些列後處理步驟並不是新穎的方法,但是是為了得到好的結果的必要步驟。匹配成本在具有相似的相鄰畫素之間組合使用基於交叉的成本聚合的影象強度。平滑約束由半全域性匹配強制執行,左右一致性檢查用於檢測和消除遮擋區域中的錯誤。我們執行子畫素增強並應用中值濾波器和雙邊濾波器以獲得最終視差圖。
這篇論文的貢獻主要是:
1、基於卷積神經網路的兩種架構的描述,用於計算立體匹配成本;
2、一種方法,附有原始碼,KITTI 2012,KITTI 2015和Middlebury立體聲資料集的錯誤率最低;
3、實驗分析資料集大小的重要性,與其他方法相比的錯誤率,以及超引數的不同設定的準確性和執行時間之間的權衡。
本文通過包括對新架構的描述,兩個新資料集的結果,較低的錯誤率和更徹底的實驗,擴充套件了我們之前的工作(Zbontar和LeCun,2015)。
2、相關的工作
在引入像KITTI和Middlebury這樣的大型立體資料集之前,相對較少的立體演算法使用地面實況資訊來學習其模型的引數;在本節中,我們將回顧那些做過的事情。 有關立體演算法的一般概述,請參閱Scharstein和Szeliski(2002)。
**************************************************未完待續************************************************************************************