論文閱讀:《Human Parsing with Contextualized Convolutional Neural Network》ICCV 2015
概述
論文主要是提出了一個local-to-global-to-local 的框架結構,主要目的是從低層加入情境化的資訊,這個框架是將交叉層內容(cross-layer context),全域性影象層內容(global image-level context)和區域性超畫素內容(local super-pixel context)整合成一個統一的網路。這個網路在ATR 資料集和Fashionista 資料集上都取得了state-of-the-art 的效果。同時,作者又擴增了Chictopia 資料集,增加了10K張圖片作為訓練集,使得準確率又有所提高。
local-to-global-to-local framework
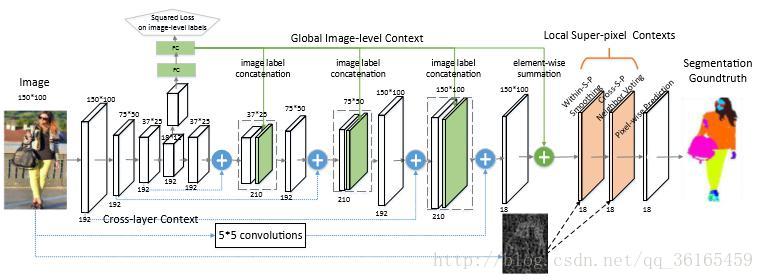
首先,輸入網路的圖片大小是150*100,這是根據卷積核的大小以及實驗環境所決定的圖片尺寸,對於不符合圖片尺寸的,採用傳統的resize 的方式。對於圖片,先做三次下采樣的操作,分別得到150*100,75*50, 37*25, 18*12 四種尺寸的圖片。對於這四個尺寸的圖片,經過逐步上取樣,分別將之前和其相同解析度的early, fine layers 的影象資訊以及deep, coarse layer 的影象資訊相結合,從而獲取cross layer 的內容。這是區域性的操作。
接著,一個輔助性的操作是將最小尺度的影象經過兩個全連線層得到影象的預測標籤,加在即將進行上取樣的影象流中。同時,這些預測結果也會結合到上取樣的最後一步中,用來重新定位pixel-wise 的預測權重。這是全域性的操作。
最後對於已經和輸入圖片相同大小的預測圖做一些區域性的濾波優化處理,包
括within-super-pixel smoothing 和cross-super-pixel neighborhood
voting,最終得到pixel-wise prediction。
框架細節
local-to-global-to-local
使用這個框架的優點在於能夠獲取cross layer 的資訊,這樣同時可以獲取local fine 細節資訊,又可以獲取global 結構資訊。對輸入影象使用下采樣是通過卷積層池化後得到的特徵圖,卷積核的大小是5*5。高解析度的影象具有更多的低層語義的全域性細節資訊,低解析度的影象具有更多高層的結構化資訊,通過結合低層的cross layer 和上取樣帶有結構資訊的高層特徵圖,能夠同時獲取這兩個層次的特徵。框架最終得到的預測結果是對每一個畫素有C 個特徵分數圖,C 是分類的標籤數。訓練採用的loss function 是所有畫素的交叉熵。
global image-level context
這個輔助性的操作是將解析度最低的特徵圖(18*12)輸入到全連線層中,最終輸出結果是C 類分類標籤。將這些分類預測標籤與中間卷積層的結果聯絡起來,這樣就得到結合後的特徵圖。相鄰層的特徵圖要經過以下卷積操作作為下一層的輸出。
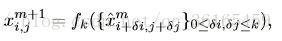
對於經過第三次image label 結合後的150*100 的特徵圖, 再使用element-wise 的相加方法,將全域性預測標籤加到特徵圖上。這和之前的image label 結合方式是不相同的,之前的結合方式是上取樣後進過卷積操作,才輸出到下一層;這種相加的方式對每一個特徵元素直接相加。這樣經過下一個階段的濾波優化操作後,預測概率低的標籤就會被消除掉,只保留預測概率高的標籤。
local super-pixel context
對於區域性超畫素內容, 主要有兩個操作, 一是within-super-pixel smoothing,二是cross-super-pixel neighborhood voting。
Within-super-pixel smoothing 實際上就是對每一張圖片產生500 個超畫素,超畫素實際上就是將影象聚類分割成500 個區域。然後使用以下的公式進行濾波,進行平滑處理:
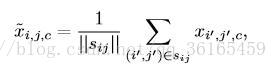
Cross-super-pixel neighborhood voting 主要是一種投票機制。對於每一超畫素s,首先從RGB,LAB,HOG 三種特徵描述方式建立bag-of-words 的“詞典”,對於每一個畫素的特徵可以定義為bs,它的cross neighborhood voted response Xs 用以下公式計算:
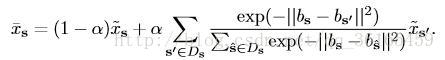
對於每一個超畫素的鄰接區域,檢視周圍與該畫素的相似程度,若相似程度
越高,則投票權重越大。這兩步操作有點類似池化的操作。
訓練細節
論文使用的資料集是ATR database,總共有18 個標籤,包括7700 張圖片,其中6000 張訓練,1000 張測試,700 張驗證。另一個小的資料集是fashionista,只有685 張圖片,其中229 張用來測試。論文提升準確率的另一個方法是增大數集,蒐集了10000 張真實世界的human picture,構造了一個更大的資料集Chictopia 10K,網路在這個資料上的表現又提升了幾個百分點的準確率。
訓練中的全連線層的dropout 比例是0.3,不是多數的0.5;採取帶動量的梯度下降方法,batch-size = 12,學習率設為0.001,每30 epoch 縮小10 倍,總共訓練90 個epochs。網路的對單張圖片的測試速度非常快,達到0.15 秒/張,超過之前的state-of-the-art。
實驗結果
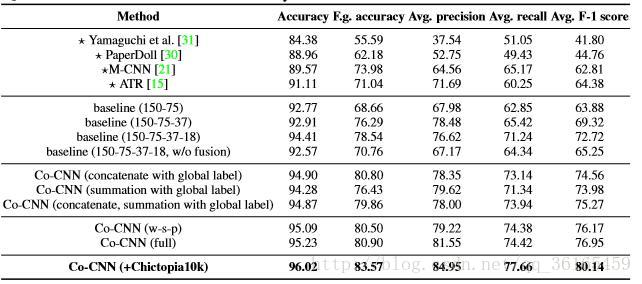
由以下這張表可以看出Co-CNN 的框架設計比之前的baseline 都有所提升,並且其後期的區域性優化處理也有顯著提升效果。其實從資料結果上可以看出,比較顯著的提升還是加入了Chictopia 10K 資料集,因為模型是擬合數據集的,好的資料集才能讓模型擬合的更好,足夠的訓練資料才能訓練出理想的模型。