
Kafka 的七年之癢

自從 2011 年被捐獻給 Apache 基金會到現在,Kafka 專案已經走過了七個年頭。作為一個優秀的分散式訊息系統,Kafka 已經被許多企業採用併成為其大資料架構中不可或缺的一部分。但 Kafka 的野心明顯不止於此。從去年 11 月推出 KSQL,到今年 7 月釋出 2.0 版本增加諸多新特性,無不是在宣告:Kafka 已經不再只是分散式訊息佇列,而是集成了分發、儲存和計算的“流式資料平臺”。
與此同時,競爭對手的崛起也給 Kafka 的未來帶來了新的變數。在今年 9 月 InfoWorld 釋出的最佳開源資料庫與資料分析平臺獎中,大資料新秀 Pulsar 首次獲獎,而在獲獎點評中明確提到“Pulsar 旨在取代 Apache Kafka 多年的主宰地位”。
從最早的“分散式訊息系統”,到現在集成了分發、儲存和計算的“流式資料平臺”,Kafka 經歷了哪些挑戰?又經過了什麼樣的演進變化?Kafka 社群踩過哪些“坑”?本文將為你一一道來。本文整理自王國璋老師在 QCon 2018 上海站的演講。
Kafka 的小歷史

嘗試
Kafka 是 2010 年左右在 LinkedIn 研發的一套流資料處理平臺。當時 LinkedIn 也和很多大的網際網路公司一樣,分很多的組,有很多的產品,每天收集非常多的資料。這些資料都是實時生成的,比如使用者活躍度、日誌,我們有各種各樣的產品來利用這些資料,資料的產生者和消費者之間採用點對點的資料傳輸,在運維方面非常耗費人力和物力。所以我們需要一個集中式的資料通道,所有的人都只跟這個資料通道進行互動,不再點對點地傳輸資料。
從 2010 年開始,我們開始做這方面的嘗試,包括訊息系統和 MQ 系統。但是後來發現,所有這些 MQ 系統都有兩個比較通用的缺陷:一是當消費者出現,無法及時消費的時候,資料就會丟掉;二是可延展性問題,MQ 系統很難很好地配合資料的波峰或波谷。
所以 2010 年我們開始自己開發 Kafka。它的設計理念非常簡單,就是一個以 append-only 日誌作為核心的資料儲存結構。簡單來說,就是我們把資料以日誌的方式進行組織,所有對於日誌的寫操作,都提交在日誌的最末端,對日誌也只能是順序讀取。Kafka 的日誌儲存是持久化到磁碟上的,雖然普遍感覺上 HDD 非常慢,但其實如果能夠把所有的讀和寫都按照順序來進行操作,會發現它幾乎可以媲美記憶體的隨機訪問。另外,我們直接使用檔案系統的快取,如果你讀取的基本上是在日誌最尾端,那麼絕大可能性只會訪問到這個檔案系統的快取,而不需落盤。所以它的速度非常快。
接下來要做的是如何做到規模上的可延展性,我們把所有的資料以 Topic 為單位來組織,每個 Topic 可以被分片,儲存在不同的伺服器上。資料的釋出和訂閱都基於 Topic,資料更新時,消費端的客戶端會自動把它們從伺服器上拉取下來。基於 Partition 的擴容會變得非常簡單,增加 Partition,然後把它們放在新加入的伺服器上,就可以保證 Topic 不斷擴容。
0.7 版本,進入 Apache 孵化器
大概不到一年之後, Kafka 就進入了 Apache 孵化器,並且釋出了第一個開源的版本 0.7.0。最主要的兩個特徵就是壓縮以及 MirrorMaker,也就是跨叢集之間的資料拷貝。
關於壓縮,我們是按純位元組組織資料的,也就是說在 0.7.0 版本里面的偏移量是基於位元組的。當一個釋出者客戶端積攢了很多資料,要一次性發布的時候,所有這些資料會被打包成為一個大的 Wrapper message,它可能會包含很多真正的 Message。Wrapper message 其實會儲存的所有這些 Message 是加在一起的總的資料偏移量,比如每個 message 是 100,那麼總偏移量就是 300。壓縮,就是要讓它的位元組數變少。舉個例子,比方說壓縮之前是 300 位元組,壓縮後變成了 50 位元組。
但這樣的做法,資料的消費端提交這個偏移量的時候,它就只能提交在這些大的、壓縮過的 Wrapper message 的邊界上。比如,消費一個大的 Message 的時候,這個 Message 裡面有一百條資料,只有把這一百條資料全部都消費完以後,才能提交準確的偏移量。原因在於,這個偏移量是壓縮過後的偏移量,中途停止或者失敗的話,無法提交一箇中間的偏移量。這是我們當時用物理的位元組作為偏移量的一個弊端,這對於使用者來說不夠靈活。但它的好處是,伺服器不需要知道任何關於這個資料的元資料,它是 bytes-in-bytes-out,而所有的邏輯都是在客戶端的。度量結果顯示,伺服器端的 CPU 利用率基本上不到 10%,而網路 99.9% 的時間都是滿的,也就是說我們基本上完全利用了所有的網路頻寬。
在 2010 年的時候,我們基本上所有的 Traffic 和 Logging Data 都已經通過 Kafka 來傳輸了,這是 Kafka 當時在領英的第一個使用者,也可以說是第一個使用場景。
0.8 版本,高可用性
在 2012 年的時候,Kafka 就正式從孵化器裡面畢業,成為了 Apache 的頂級專案。同時,我們釋出了 0.8.0。日後來看,它是一個將 Kafka 區別於非常多其他流資料平臺的版本。因為我們在 0.8.0 裡面加入了高可用性,也就是基於備份的一個高可用性的特性。
在之前,一個伺服器端失敗了,會導致這個伺服器端所存的流資料在恢復之前無法再被取得,更有甚者,這些流資料永遠丟失了。這也是為什麼在 0.7 版本的時候,當時最大的使用場景是 Logging Data 以及 User Data,這些 Data 丟了就丟了,對於公司影響不是那麼大。但是,如果要儲存重要的資料,每條價值幾美元,沒有高可用性是不合適的,所以在 0.8 版本里面我們提出要增加這樣一個特性。
這裡我簡單講一下 Kafka 0.8 的 replication。每一個 Topic 都被分片 partition,每個 partition 會被備份到多臺機器上。我們把每個 partition 叫做一個 replica,至於 Partition 的 replica 置放,基本上是一個簡單的輪詢。比如,Topic1 的第一個 Partition 被分配到 123,第二個 Partition 被分配到 231 等等。每一個 Group 裡,有一個 Partition 會成為 Leader,這個 Leader 來進行所有讀寫請求的操作。也就是說,當客戶端釋出資訊、讀取資訊的時候,都是和這個 leader 互動,並且 Leader 負責把已經發布的資料再備份到其他的 replica 上。
2011 年的時候呢,我們看了很多備份、管理資料的協議,提出了一個理念:對於流資料,我們希望基於簡單的協議做資料備份,而備份之間的管理要基於複雜的協議。當時很多產品都是以同一套協議來做兩件事情。所以,在 0.8 版本里面,相當於我們自己開發了一套資料備份協議。
我們當時提出了一個叫做 ISR,或者叫做實時備份列表的機制。我們把所有的備份分為已同步和未同步的備份。已同步的備份指,Leader 所有的 Data 在 replica 裡面都有;未同步的很簡單,由於可能比較慢,或者備份還不完整,也許有些資料在 Leader 上面有,但是在 replica 上沒有。Leader 可以通過來管理這樣的一個列表來做到實時的修改。同時,釋出者釋出資訊的時候,可以要求備份方式。
我們在 0.8 中通過一個控制器來做到備份的靈活處理,它主要包括三點:第一點就是通過 Zookeeper 來監測每一個伺服器是否還在運轉,當需要選擇新的 Leader 甚至 RSR 時,這個控制器可以進行 Leader 的選舉,最後把這個 Leader 上新的資料釋出到所有 broker 上。當時我們做了很多測試,所有的客戶、所有的伺服器端都跟 Zookeeper 進行直接互動的話,那麼 Zookeeper 的壓力會非常大。而這個控制器就起到一個在 Zookeeper 跟其他伺服器之間協同的角色,也就是說只有控制器需要跟 Zookeeper 之間進行大量的互動,當它得到了一些新的元資料的更新以後,再把這些資料釋出到其他所有的 broker 上。
在 2012 年的時候,Kafka 就已經在 LinkedIn 公司內部完成了對所有線上流資料的傳輸整合,不僅對 LinkedIn 內部,對整個業界也產生了很大的影響。由於這個高可用性的特性,Kafka 脫穎而出,成為了當時整合流資料傳輸的集中式通道的更好選擇。
在 0.8 版本里我們還更新了訊息的資料結構,把資料偏移量改成了按邏輯的,每條資訊的資料偏移量就是 1,不管訊息有多大。當壓縮和解壓縮時,你就需要知道壓縮過後的資料裡包含了多少小資料,可以通過增加偏移量來增加大資料的偏移量。舉個例子,第一個大的資料,壓縮包裡面包含了三個小資料,它們本身的偏移量是 012,那麼包壓縮的偏移量就是 2,也就是最後那個資料所對應的邏輯偏移量。當下一個訊息被髮布的時候,再根據已有的偏移量和壓縮的資料重新計算偏移量。所以在 0.8 裡,已經逐漸將系統性能壓力向 CPU 轉移,要花一些 CPU 來做解壓縮、重新壓縮、偏移量的計算,以及由於加了資料的備份,CPU 佔用率在當時已經不再是 10% 了。
0.9 版本,配額和安全性
2014 年,我們成立了 Confluent,是當時 LinkedIn Kafka 的幾個技術核心人員離開公司成立的基於 Kafka 的流資料平臺公司。同年,釋出了 0.8.2 和 0.9.0,在 0.9.0 這個版本里面,加入了兩個非常重要的特性,配額和安全性。
當 Kafka 叢集不斷變大、使用場景不斷增多的時候,多租戶之間的影響就會非常顯著,一個人可以影響其他所有使用者。當時,有一個員工寫的客戶端,當獲取元資料失敗時會一直髮請求,並部署到了幾十臺機器上,結果就影響了所有的其他使用者。所以我們在 0.9 裡第一個要加的重大機制就是配額,限定每一個 user 能夠用多大的流量跟 Kafka 互動。如果你超過配額,Kafka broker 就故意延遲你的請求,使一個 User 不會影響別人。這就是 0.9 的配額機制。
另一個很重要的機制是安全性,我們現在都知道安全性很大的三個方面就是授權、認證、加密。授權、認證說的直白一點,就是誰能幹什麼,這個誰就是認證,能幹什麼就是授權。那麼認證在 Kafka 0.9 版本里面,我們用的是 SSL 認證。認證是一個一次性的過程,也就是說當一個新的客戶端,第一次和伺服器端建立連線的時候,會通過 SSL 進行一次認證。但是授權,讀、寫、修改或者管理操作的時候,每一次都需要做我們所謂的授權檢查。
當然了,這些授權和認證其實對我們的效能是有一定影響的。正如剛剛我提到的 Kafka 本身的高效能來自於幾點,一是用日誌作為檔案儲存系統;二是利用檔案系統作為快取;三是我們當時採用了 Java 7 中新加入的零拷貝機制,原來將資料從磁碟寫入網絡卡需要經過四次拷貝,有了零拷貝機制能夠省去其中從使用者端到核心端的資料拷貝過程。但我們加了安全機制,除了認證和授權以外,還做了資料加密,即使別人惡意竊聽了你的網絡卡,也不能得到真正的資料。由於這些中間處理,就不能使用零拷貝機制直接把網絡卡資料寫入磁碟了,最後只能放棄了 Java 7 裡新加的零拷貝機制。
好在在 Java 11 對 TLS 做了重大的效能改革。我們自己做的基準測試顯示,在 0.9 版本如果加入了加密和 SSL,Kafka 的效能可能會有 20% 甚至 23% 左右的影響。後來我們到了 Kafka 0.10、0.11 以後,用了 Java 11,效能只會受到最多 9% 的影響。
在 0.9 版本里面加了授權和認證以後,就發現了一個非常新的使用場景,就是用 Kafka 來作為資料庫、多資料中心資料複製的骨幹,當拷貝元資料從一個數據中心到另外一個數據中心的時候,很多人開始使用 Kafka 來拷貝資料捕獲。因為我們加入了配額和安全性,很多使用者開始敢於把資料敏感、安全性敏感、延遲性敏感的使用場景放到 Kafka 叢集上。
另外一個非常重要的新特性,就是基於訊息 Key 的清理。在 0.8 版本以前,Kafka 僅以時間或者資料大小來清理,可以配置為資料存四天,過期一天的資料就自動清理掉。但資料其實是以 Key 作為標識的,所以資料清理的時候,應該是以 Key 作為核心,而不是通過時間。即使 7 天之內沒有被更新過,也不代表它就應該被清理掉。
由於這些特性的加入,現在 CPU 上要做壓縮、解壓縮、加密、解密、備份間的協調等操作,所以對 CPU 的消耗逐漸加大了,但網路頻寬一直不變。
0.10 版本,更細粒度的時間戳
0.10 版本里,我們又加入了一個非常重要的特性,就是時間戳,除了語義上的增強,也是對於 CPU 損耗的優化。在 0.9 版本或者更老的版本里面,對於時間的概念是非常粗粒度的,每一個分片是一個檔案,所有 record 僅以這個檔案的時間作為基準,也就是說 record 在語義上的時間被認為是一樣的。那麼當需要依據時間進行回溯時,無法得到非常確切的偏移量。在 0.10 版本里面,對每一個 record 會打一個具體的時間戳,釋出端生成一個新的 record 時可以打一個時間戳,這樣可以有細粒度的時間管理,並且可以基於偏移量進行快速的資料查詢,找到所要的時間戳。
這樣首先可以做到更細粒度的 log rolling/log retention;第二,很多基於時間上的操作的準確性大大提升。每個時間戳可以有兩種語義,第一種是釋出的時候在客戶端可以蓋一個時間戳;第二種客戶端不蓋,交由 broker,當它收到 record,append 到日誌上時蓋一個時間戳。區別在於,append time 一定是順序的,而 create time 會是亂序的,因為會有很多 producer 同時蓋時間戳,釋出到 partition 上。這是時間戳語義上的增強。
在效能上也有一個好處,在蓋時間戳的同時,把偏移量位移從絕對位移改成相對位移,當一個壓縮包裡面有位移的時候,只需要記錄相對位移,把相對位移加上絕對的基礎位移,就可以計算出絕對位移。它的好處是 0.10 版本的 producer 進來的時候,不需要做解壓縮,但如果你是 0.9 和更老的版本請求進來的時候,還需要做一步解壓縮和 up conversion。測試表明,這一改進使 CPU 的佔有率大大降低。
Kafka Streams 是在 0.10 裡面加入的,它是一個流處理的平臺,或者叫它是流處理的一個庫。它是基於釋出端和消費端的處理平臺,它能夠做到的是 Event-at-a-time、Stateful,並且支援像 Windowing 這樣的操作,支援 Highly scalable、distributed、fault tolerant。所有這些都很大程度上利用了 Kafka broker,也就是伺服器端本身的延展性和高可用性。因為 Kafka Streams 是一個庫,也就是說,你不只是在很大的叢集上,甚至在膝上型電腦上、黑莓上都可以安裝它來進行流處理的計算。而且你所要做的很簡單,只要把它作為你應用的 dependency 進行程式設計就可以了。用 Kafka Streams 編好流處理應用的時候,可以用各種方法來部署和監控。你可以只把它作為一個很普通的 Java 應用,或者用 Docker 也可以,任何地點、任何時候、任何方式均可。這就是我們的設計初衷,如果你的叢集管理已經有自己的一套成熟工具,不需要再為了用 Kafka Streams 而進行一些調整。
簡單來說,Kafka Streams 所做的就是從 Kafka 的 Topic 裡實時地抓取資料。這個資料會通過使用者所寫拓撲結構,把所有的 record 實時進行 transform 之後,最終再寫回到 Kafka 裡面,是個很簡單的流資料處理。那麼它怎麼做延展性呢?也很簡單,當用戶寫好一個拓撲結構以後,可以在多個機器,或者多個容器、多個虛擬機器、甚至是多個 CPU 上面,部署多個應用,當應用同時進行的時候,會利用 Kafka 自動地劃分每一個不同的應用所抓取的不同 partition 的資料。
Kafka Streams 是基於 Kafka 流處理的一個庫。如果流處理操作平臺不在 Kafka 上,怎麼把資料先寫到 Kafka,再用 Kafka Streams 呢?可以利用 Kafka Connect,它是一個 Kafka 的 ingress、egress 框架。元資料可以是一個數據庫,也可以是 Web Server,可以是各種各樣不同的資料節點,它可以通過 Kafka Connect 實時把資料匯入到 Kafka 資料流裡面,也可以通過 Kafka Connect 把 Kafka 的流資料實時匯出到最終的終端上。Kafka Connect 本身是一個框架,我們歡迎所有人蔘與貢獻。到目前為止,我們已經有了 45 個以上基於不同系統的 Kafka Connect 可以自動被下載和使用,其中開源社群、合作伙伴做了很多的貢獻。未來,我也希望能夠看到更多來自於國內的同學參與到 Kafka Connect 框架的貢獻中。
1.0 & 1.1 版本,Exactly-Once 與運維性提升
大家共同的指標,是我們要 做到 Exactly-Once 才釋出 1.0 版本,這才能使 Kafka 作為一個成熟的流資料平臺持續發展。
什麼是 Exactly-Once?非 Exactly-Once 是指由於網路延遲或其他各種原因,導致訊息重複傳送甚至重複處理。那麼直白來說 Exactly-Once 的定義,就是從應用的角度來說,當發生了錯誤,希望做到每一個接收到的 record,處理結果會被反映到它的處理狀態中,一次且僅有一次,也就是 Exactly-Once。
那麼在 0.11 以及之前的版本里面,Kafka 的使用者普遍是如何保證 Exactly-Once 的呢?很簡單,就是基於 Kafka 的 At-Least-Once 加上去重,把處理過的 record 記錄下來,發現重複處理時就把它扔掉。這樣做的複雜性在於,對於一個機構或者一個公司,實時作業系統不只是一個應用,可以是多個應用,每一個 output record 可能就是下一個應用的 input record,那麼做去重的時候,需要在每一個階段都做去重,這樣一是成本高,二是運維難度大。
所以在 0.11 裡面,我們給兩個基礎的 Building blocks 來做 Exactly-Once。第一點是冪等性,意味著對於同一個 partition data 的多次釋出,Kafka broker 端就可以做到自動去重;第二點是 Transactions,當在一個事務下發布多條資訊到多個 topic partition 時,我們可以使它以原子性的方式被完成。基於這一點,我們在 Kafka Connect 和 Kafka Streams 上面就加入了簡單的 Exactly-Once 機制,也就是一個配置。以 Kafka Streams 為例,只要配置一個 config,就可以使 processing 從 At-Least-Once 變成 Exactly-Once。
在 0.11 以後,我們更加關注運維能力,因為大家反饋了很多這方面的問題。比如 Controller shut down,想要關閉一個 broker 的時候,需要一個很長很複雜的過程,需要通知所有 broker,完成所有相關操作,並完成相關記錄,才能完成整個 shut down 的過程。在這個過程中,需要傳送很多次請求,對元資料進行多次修改,這對於延遲性有很多的要求,使這個過程變得很緩慢,是當時普遍存在的一個問題。所以在 1.0 和 1.1 版本,我們進行了一次重寫,進行了大面積的優化。在 1.0 版本,在五個 broker node 的叢集下,要進行一次 Controller shutdown,10k partition per brocker 的規模,需要 6 分鐘的時間,而在 1.1 版本里只需要 3 秒鐘,而 Controller failover 的延遲也從 28 秒降到了 14 秒。除了 Controller,我們在 1.1 裡對運維性、進化性也做了很多工作。
未來願景

Global Kafka:就是 Kafka 對於多資料中心的原生支援,我們想做到一個 Kafka 叢集可以部署在多個數據中心。這需要 Kafka 能夠做到更好的延展性、更便捷的可運維性等。
Infinite Kafka:目前 Kafka 的使用者都是配置儲存 4 到 7 天或者最多一個月的資料,但越來越多的使用者想在 Kafka 儲存過去更久的流資料,但是同時不會因為長時效的資料流而導致資料拷貝或者遷移的時候造成大量延遲。這同時也意味著 Kafka 需要有更好的雲架構相容性。
經驗教訓
構建可進化的系統
Kafka 作為一個流處理平臺,是一個不斷進化的平臺,也就是說,你不能把 Kafka Shut down 來進行更新,只能一邊用一邊更新。
我們在 0.8 版本里面改了資料格式,但是並沒有一個非常好的升級補丁。當時很多人的做法是通過資料複製器把 0.7 版本的資料同步複製到 0.8 版本的叢集裡,也就說在很長一段時間內,需要同時運維 0.7 版本和 0.8 版本的 Kafka 叢集,只有當 0.7 版本的所有客戶端全部轉移到 0.8 版本以後,才能關閉 0.7 版本的客戶端。這是一個非常痛苦和漫長的過程。所以我們現在認為,當你需要構建一個可以長時間使用並且永遠不下線的系統時,線上可進化性是最重要的特性。
要做到一個能夠實現百分之百線上可進化的系統,首先要提供一個簡單的升級過程,其次能讓所有的使用者自主地、只通過閱讀文件或者協議更新檔案,就能做到線上升級。
只有能被度量的問題才能得到最終解決
如果想要知道,每一個釋出的 record,是否最終通過了所有的 Kafka 叢集,通過了所有的 Tier,最終到了消費端,並且到每個 Tier 的時候耗費了多少時間,只有對 Kafka 進行全方位的觀測和監測,才能知道哪裡出現了問題,需要在哪裡進行優化,需要在哪裡進行改進。
API 保持不變
新版本釋出後,所有 API 就再也不能變了。舉個例子,Kafka1481 是社群貢獻的一個特性,我們所有的度量是用下劃線作為分隔符,由於在很多系統中下滑線是不被允許的字元,我們就把下劃線改成了單槓,在當時我們沒有想太多,就把合併到主幹裡了。結果,所有的度量板都變成白屏了。因為度量名中的分隔符從下劃線變成單槓,所有的度量項全都抓不到了。
所以我們每次設計 API 的時候,都要想清楚,到底這些 API 應該怎麼設計,每次做一個更新的時候,我們都要想,這個更新有沒有可能對使用者造成一些沒有想到的影響。
服務需要把關
一個壞使用者可以影響所有人。Kafka 進化到 1.0 版本以後,更多的人開始在雲上使用 Kafka,對安全性、多租戶的特性提出了更高的要求,包括端到端的加密、ACL/RBAC。除了安全性以外,在配額方面也有更多新的要求,不僅要有流量的限制,還有 CPU 的限制。
生態系統是關鍵
生態系統對一個開源社群來說是非常重要的。舉個例子,當時我們在 0.8.2 版本里面把所有的貢獻直接放到了 Kafka 裡面,但是之後發現,與其把所有的程式碼、元件都放到一個 repo 裡面,不如構建一個原生態的生態系統,比方說容器的支援、語言的支援,大家可以在官網上找到跟這些相關的所有生態系統的連結。
構建一個開源產品或者開源專案的時候,要做的並不是把所有的元件或者所有的貢獻都放在同一個專案裡面,而應該構建一個繁榮的開源生態系統,所有人都可以基於核心元件做不同元件的開發。不同元件的開發維護週期也不一樣,不需要跟 Kafka 核心元件同步更新或者同步維護。
寫在最後
我們講了這麼多,到底什麼是 Kafka?
最早的時候,我們說 Kafka 是一個可擴充套件的訂閱釋出的訊息系統;2013 年的時候,我們說 Kafka 是一個實時資料通道;2015 年的時候,我們說 Kafka 是一個分散式的備份 Log,同年,我們提出了 Kafka Architecture,是針對 Lamda Architecture 提出的一個新的框架,我們認為 Kafka 是一個統一資料整合堆疊。
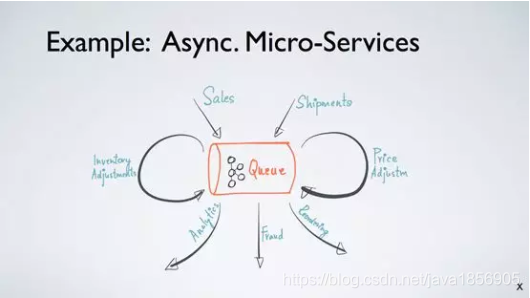
以微服務為例,什麼是微服務?我們在構建一個架構的時候,每一個小組、每一個模組只需要負責自己的生態和邏輯,而它跟所有其他小組或模組的互動,都可以通過一個非同步的流處理平臺來傳輸。形象一點說,可以把每一個應用看作流水線上的一個工人,它從流水線的上端取得一個任務,處理之後把結果釋出到流水線的下端,而它的下端可能是下一個應用的流水線的上端,每一個應用之間只需要通過這樣一個非同步的流水線來協作,每個應用升級、運維、開發都是不需要進行對偶或者重構的,可以做到完全非同步,這就是 Async Micro-Services 的核心。Kafka 在這樣一個架構下被很多應用作為非同步的流式訊息框的不二之選。
我們對於 Kafka 有這麼多不同的理解,那麼 Kafka 到底是什麼?我的答案是,以上皆是。
最早的時候,我們說 Kafka 是一個訂閱訊息系統,但是從 0.7 版本一直升級到 1.0,或者說現在的 2.0 版本以後,Kafka 已經進化成為一個流處理平臺。這個平臺不光是流資料的釋出,還能涵蓋流處理的儲存、處理、映象、備份等等,所有的使用者都可以在上面進行各種各樣的實時流資料處理的應用的開發以及維護。這是我想要說的關鍵的一點。
最後再提一下 Kafka 現在在全世界的應用情況。今年上半年,我們做過一個統計,在福布斯 500 強公司裡面,大概有 35% 的公司都在使用 Kafka。具體到不同的行業,全世界前 10 大旅行公司中有 6 個在使用 Kafka,全世界最大的 10 個銀行有 7 個在用 Kafka,最大的 10 個保險公司有 8 個在用 Kafka,最大的 10 個通訊公司中有 9 個在用 Kafka。
可以看到,雖然 Kafka 在 2010 年釋出 0.7 版本的時候還是一個由網際網路公司提出來的流資料的資料通道,但是發展到今天,它已經橫跨了非常多的領域,在非常多的平臺上被用來做各種不同的事情,但其中有一個核心,就是這些事情都是針對實時流資料的處理。
歡迎工作一到五年的Java工程師朋友們加入Java技術交流:611481448
群內提供免費的Java架構學習資料(裡面有高可用、高併發、高效能及分散式、Jvm效能調優、Spring原始碼,MyBatis,Netty,Redis,Kafka,Mysql,Zookeeper,Tomcat,Docker,Dubbo,Nginx等多個知識點的架構資料)合理利用自己每一分每一秒的時間來學習提升自己,不要再用"沒有時間“來掩飾自己思想上的懶惰!趁年輕,使勁拼,給未來的自己一個交代!
喜歡小編輕輕點個關注吧!