
(NLP)基於分詞標籤的中文短文字相似度
基於分詞標籤的中文短文字相似度
最近接觸到了一些關於中文短文字相似度的演算法,將它們總結在此:
- 中文編輯距離
- 基於詞頻的餘弦相似度
- Python difflib
github傳送門:https://github.com/gongpx20069/DIYNLP
1.0 在相似度演算法之前的分詞處理
在比較兩個字串str1和str2之前,我們需要對它們進行分詞處理,分詞後變成兩組標籤(我認為分詞後的標籤具有原子性,不可再分),基於標籤,我們可以很容易地進行兩組資料的相似度比較。
優點:標籤的頻率以及相對的位置關係確實一定程度可以表示出重要性和時序關係。
缺點:中文編輯距離(時序關係),餘弦相似度(標籤重要性),他們沒有直接的連線。
本專案基於jieba分詞。
import jieba
str1=jieba.lcut(str1)
str2 = jieba.lcut(str2)2.1中文編輯距離
編輯距離,又稱Levenshtein距離(萊文斯坦距離也叫做Edit Distance),是指兩個字串之間,由一個轉成另一個所需的最少編輯操作(插入,刪除,替換)次數,如果它們的距離越大,說明它們越是不同。許可的編輯操作包括將一個字元替換成另一個字元,插入一個字元,刪除一個字元。
2.1.1演算法原理
假設我們可以使用d[ i , j ]個步驟(可以使用一個二維陣列儲存這個值),表示將串s[ 1…i ] 轉換為 串t [ 1…j ]所需要的最少步驟個數,那麼,在最基本的情況下,即在i等於0時,也就是說串s為空,那麼對應的d[0,j] 就是 增加j個字元,使得s轉化為t,在j等於0時,也就是說串t為空,那麼對應的d[i,0] 就是 減少 i個字元,使得s轉化為t。
然後我們考慮一般情況,加一點動態規劃的想法,我們要想得到將s[1..i]經過最少次數的增加,刪除,或者替換操作就轉變為t[1..j],那麼我們就必須在之前可以以最少次數的增加,刪除,或者替換操作,使得現在串s和串t只需要再做一次操作或者不做就可以完成s[1..i]到t[1..j]的轉換。所謂的“之前”分為下面三種情況:
- 我們可以在k個操作內將 s[1…i] 轉換為 t[1…j-1]
- 我們可以在k個操作裡面將s[1..i-1]轉換為t[1..j]
- 我們可以在k個步驟裡面將 s[1…i-1] 轉換為 t [1…j-1]
針對第1種情況,我們只需要在最後將 t[j] 加上s[1..i]就完成了匹配,這樣總共就需要k+1個操作。
針對第2種情況,我們只需要在最後將s[i]移除,然後再做這k個操作,所以總共需要k+1個操作。
針對第3種情況,我們只需要在最後將s[i]替換為 t[j],使得滿足s[1..i] == t[1..j],這樣總共也需要k+1個操作。而如果在第3種情況下,s[i]剛好等於t[j],那我們就可以僅僅使用k個操作就完成這個過程。
最後,為了保證得到的操作次數總是最少的,我們可以從上面三種情況中選擇消耗最少的一種最為將s[1..i]轉換為t[1..j]所需要的最小操作次數。
2.1.2程式碼實現
#其中的str1,str2是分詞後的標籤列表
def edit_similar(str1,str2):
len_str1=len(str1)
len_str2=len(str2)
taglist=np.zeros((len_str1+1,len_str2+1))
for a in range(len_str1):
taglist[a][0]=a
for a in range(len_str2):
taglist[0][a] = a
for i in range(1,len_str1+1):
for j in range(1,len_str2+1):
if(str1[i - 1] == str2[j - 1]):
temp = 0
else:
temp = 1
taglist[i][j] = min(taglist[i - 1][j - 1] + temp, taglist[i][j - 1] + 1, taglist[i - 1][j] + 1)
return 1-taglist[len_str1][len_str2] / max(len_str1, len_str2)2.2基於詞頻的餘弦相似度(TF-IDF)
餘弦相似度:計算兩者空間向量的夾角來表示兩者的相似性。
2.2.1演算法原理
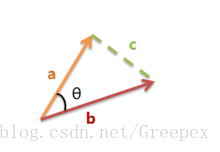
上圖是向量a和向量b以及它們的夾角θ。根據初等數學公式,假設向量a、b的座標分別為(x1,y1)、(x2,y2) ,則:
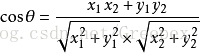
假設a是str1的標籤特徵向量,b是str2的標籤特徵向量,那麼兩者的相似度可以用cosθ表示,且0<=cosθ<=1。
而關於str1,str2的標籤特徵向量的獲取,我們這裡用了TF-IDF中的思想,利用詞頻來表示。
例如str1=[“我”,”愛”,”漫威”],str2=[“我”,”喜歡”,”漫威”,”電影”]
則所有詞語的集合為[“我”,”愛”,”喜歡”,”漫威”,”電影”]
str1(計算相應詞頻)轉變後的a=[1,1,0,1,0]
str2(計算相應詞頻)轉變後的b=[1,0,1,1,1]
計算後的相似度為:0.577350
2.2.2程式碼實現
#其中的str1,str2是分詞後的標籤列表
def cos_sim(str1, str2):
co_str1 = (Counter(str1))
co_str2 = (Counter(str2))
p_str1 = []
p_str2 = []
for temp in set(str1 + str2):
p_str1.append(co_str1[temp])
p_str2.append(co_str2[temp])
p_str1 = np.array(p_str1)
p_str2 = np.array(p_str2)
return p_str1.dot(p_str2) / (np.sqrt(p_str1.dot(p_str1)) * np.sqrt(p_str2.dot(p_str2)))2.3Python difflib
difflib為python的標準庫模組,無需安裝。作用為對比文字之間的差異。關於該方法在python的官方文件中描述如下:
This is a flexible class for comparing pairs of sequences of any type, so long as the sequence elements are hashable. The basic algorithm predates, and is a little fancier than, an algorithm published in the late 1980’s by Ratcliff and Obershelp under the hyperbolic name “gestalt pattern matching.” The idea is to find the longest contiguous matching subsequence that contains no “junk” elements (the Ratcliff and Obershelp algorithm doesn’t address junk). The same idea is then applied recursively to the pieces of the sequences to the left and to the right of the matching subsequence. This does not yield minimal edit sequences, but does tend to yield matches that “look right” to people.
如上,來源於gestalt pattern matching,根據描述可以看出,該演算法是類似於編輯距離的一種演算法。
2.3.1程式碼實現
#其中的str1,str2並未分詞,是兩組字串
diff_result=difflib.SequenceMatcher(None,str1,str2).ratio()3.0加權三種演算法
最終的字串比較函式compare是由0.4倍的餘弦相似度,0.3倍的編輯距離相似度,0.3倍的序列化匹配加權而成。
因為上文提到,序列化匹配和編輯距離相似度演算法很相像,他們只考慮了時序關係,兩者共同所佔比例不應該過高。
最終程式碼如下:
def compare(str1, str2):
if str1 == str2:
return 1.0
#其中的str1,str2並未分詞,是兩組字串
diff_result=difflib.SequenceMatcher(None,str1,str2).ratio()
#分詞
str1=jieba.lcut(str1)
str2 = jieba.lcut(str2)
cos_result=cos_sim(str1, str2)
edit_reslut=edit_similar(str1,str2)
return cos_result*0.4+edit_reslut*0.3+0.3*diff_result中文文字情感極性分析
情感極性分析是對帶有情感色彩的主觀性文字的分析、處理、歸納和推理的過程。按照處理文字可以分為基於新聞評論和產品的情感分析;按照作用可以分為輿情監控和資訊預測。
利用情感詞典
利用詞向量和深度學習
github傳送門:https://github.com/gongpx20069/DIYNLP
1.1利用情感詞典
情感詞典來源於Boson
該情感詞典是從社交媒體中獲得。
但是情感詞典具有很大的侷限性,語言的多義性和時序關係沒有考慮,但基本可以對簡單的文字進行正負向的評分。
考慮到該詞典不會對詞典中沒有出現的詞進行評分,對文字進行停用詞處理沒有什麼意義,直接進行運算即可。
1.1.1模型匯入程式碼
import jieba
import json
import os
SAdic={}
with open(os.path.join(os.getcwd(),"DIYNLP/model/SA.model"),"r") as f:
SAdic=json.loads(f.read())
def getscore(str0):
score = 0
for i in jieba.lcut(str0):
if i in SAdic.keys():
score+=SAdic[i]
return score1.2利用詞向量和深度學習
由於缺少訓練集,等待後續探索……
參考文件:
[1] https://www.cnblogs.com/liangjf/p/8283519.html
[2] https://www.jianshu.com/p/4cfcf1610a73?nomobile=yes