
如何有效構建使用者畫像,如何更新你的使用者畫像
使用者畫像
有過一次網購經歷後,下次登陸該網站,會彈出各種同類型替代商品或者互補商品的推薦;成為某品牌的註冊會員,特殊的日子(會員日、生日)經常會收到品牌商發來的通知(祝福)簡訊或者郵件。這一切都是精準化營銷的常見套路。
在網際網路大資料時代,得使用者者得天下。以龐大的使用者資料為依託,構建出一整套完善的使用者畫像,藉助其標籤化、資訊化、視覺化的屬性,是企業實現個性化推薦、精準營銷強有力的前提基礎。
可見,深入瞭解使用者畫像的含義,掌握使用者畫像的搭建方法,顯得尤其重要。
使用者畫像是真實使用者的虛擬模型
關於“使用者畫像是什麼”的問題,最早給出明確定義的是互動設計之父Alan Cooper,他認為:Persona(使用者畫像)是真實使用者的虛擬代表,是建立在一系列真實資料之上的目標使用者模型。
敲黑板,劃重點:真實、資料、虛擬。

如果把真實的使用者和虛擬的模型比作隔江相望的兩個平行點,資料就是搭建在大江之上,連線起彼此的橋樑。
企業利用尋找到的目標使用者群,挖掘每一個使用者的人口屬性、行為屬性、社交網路、心理特徵、興趣愛好等資料,經過不斷疊加、更新,抽象出完整的資訊標籤,組合並搭建出一個立體的使用者虛擬模型,即使用者畫像。
給使用者“打標籤”是使用者畫像最核心的部分。所謂“標籤”,就是濃縮精煉的、帶有特定含義的一系列詞語,用於描述真實的使用者自身帶有的屬性特徵,方便企業做資料的統計分析。
出於不同的受眾群體、不同的企業、不同的目的,給使用者打的標籤往往各有側重點,應該具體問題具體看待。
但是,有些標籤適用於所有情況,應該加以理解和掌握。我把常見的標籤分成兩大類別:相對靜止的使用者標籤以及變化中的使用者標籤。
相對應的,由靜態標籤搭建形成的畫像就是2D使用者畫像;由靜態標籤+動態標籤構建出來的即是3D使用者畫像。
靜態的使用者資訊標籤以及2D使用者畫像
人口屬性標籤是使用者最基礎的資訊要素,通常自成標籤,不需要企業過多建模,它構成使用者畫像的基本框架。
人口屬性包括人的自然屬性和社會屬性特徵:姓名、性別、年齡、身高、體重、職業、地域、受教育程度、婚姻、星座、血型……。自然屬性具有先天性,一經形成將一直保持著穩定不變的狀態,比如性別、地域、血型;社會屬性則是後天形成的,處於相對穩定的狀態,比如職業、婚姻。
心理現象包括心理和個性兩大類別,同樣具有先天性和後天性。對於企業來說,研究使用者的心理現象,特別是需求、動機、價值觀三大方面,可以窺探使用者註冊、使用、購買產品的深層動機;瞭解使用者對產品的功能、服務需求是什麼;認清目標使用者帶有怎樣的價值觀標籤,是一類什麼樣的群體。
具體的心理現象屬性標籤包括但不限於:
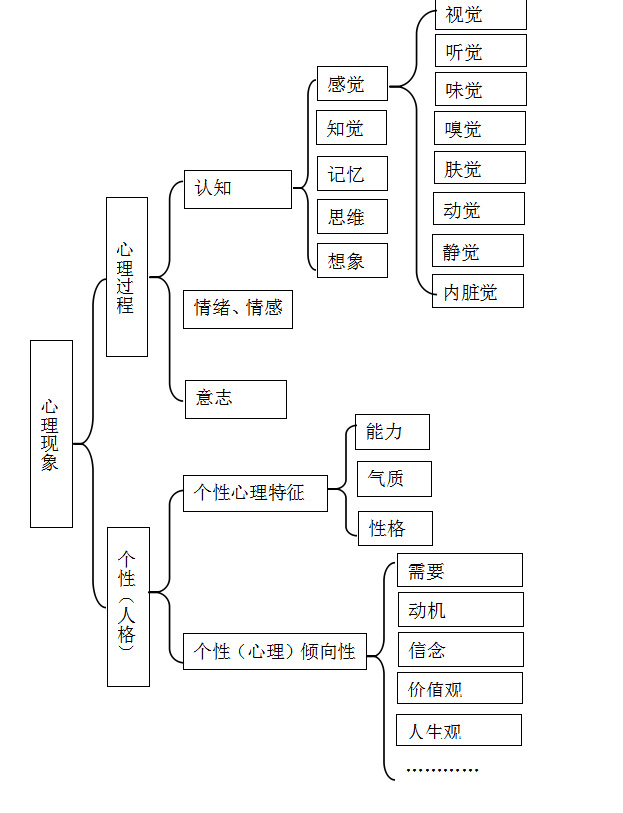
來源:“心理現象”百度百科
因為人口屬性和心理現象都帶有先天的性質,整體處於穩定狀態,共同組成使用者畫像最表面以及最內裡的資訊素,由此形成穩定的2D使用者畫像。

2D使用者畫像
動態的使用者資訊標籤以及3D使用者畫像
網站行為屬性,這裡我們主要討論的是使用者在網站內外進行的一系列操作行為。常見的行為包括:搜尋、瀏覽、註冊、評論、點贊、收藏、打分、加入購物車、購買、使用優惠券……。
在不同的時間,不同的場景,這些行為不斷髮生著變化,它們都屬於動態的資訊。企業通過捕捉使用者的行為資料(瀏覽次數、是否進行深度評論),可以對使用者進行深淺度歸類,區分活躍/不活躍使用者。
社交網路行為,是指發生在虛擬的社交軟體平臺(微博、微信、論壇、社群、貼吧、twitter、Instagram)上面一系列使用者行為,包括基本的訪問行為(搜尋、註冊、登陸等)、社交行為(邀請/新增/取關好友、加入群、新建群等)、資訊釋出行為(新增、釋出、刪除、留言、分享、收藏等)。
給使用者打上不同的行為標籤,可以獲取到大量的網路行為資料、網站行為資料、使用者內容偏好資料、使用者交易資料。這些資料進一步填充了使用者資訊,與靜態的標籤一起構成完整的立體使用者畫像,就是所說的3D使用者畫像。

3D使用者畫像
使用者畫像的價值
企業必須在開發和營銷中解決好使用者需求問題,明確回答“使用者是誰——使用者需要/喜歡什麼——哪些渠道可以接觸到使用者——哪些是企業的種子使用者”。
更瞭解你,是為了更好的服務你!可以說,正是企業對使用者認知的渴求促生了使用者畫像。
使用者畫像是真實使用者的縮影,能夠為企業帶來不少好處。
指導產品研發以及優化使用者體驗
在過去較為傳統的生產模式中,企業始終奉行著“生產什麼就賣什麼給使用者”的原則。這種閉門造車的產品開發模式,常常會產生“做出來的東西使用者完全不買賬”的情況。
如今,“使用者需要什麼企業就生產什麼”成為主流,眾多企業把使用者真實的需求擺在了最重要的位置。
在使用者需求為導向的產品研發中,企業通過獲取到的大量目標使用者資料,進行分析、處理、組合,初步搭建使用者畫像,做出使用者喜好、功能需求統計,從而設計製造更加符合核心需要的新產品,為使用者提供更加良好的體驗和服務。
實現精準化營銷
精準化營銷具有極強的針對性,是企業和使用者之間點對點的互動。它不但可以讓營銷變得更加高效,也能為企業節約成本。
以做活動為例:商家在做活動時,放棄自有的使用者資源轉而選擇外部渠道,換而言之,就是捨棄自家精準的種子使用者而選擇了對其品牌一無所知的活動物件,結果以超出預算好幾倍的成本獲取到新使用者。
這就是不精準所帶來的資源浪費。
包括我前面所提到的,網購後的商品推薦以及品牌商定時定點的節日營銷,都是精準營銷的成功示範。
要做到精準營銷,資料是最不可缺的存在。以資料為基礎,建立使用者畫像,利用標籤,讓系統進行智慧分組,獲得不同型別的目標使用者群,針對每一個群體策劃並推送針對性的營銷。
可以做相關的分類統計
簡單來說,藉助使用者畫像的資訊標籤,可以計算出諸如“喜歡某類東西的人有多少”、“處在25到30歲年齡段的女性使用者佔多少”等等。
便於做相關的資料探勘
在使用者畫像資料的基礎上,通過關聯規則計算,可以由A可以聯想到B。
沃爾瑪“啤酒和尿布”的故事就是使用者畫像關聯規則分析的典型例子。

資料來源:“關聯規則”百度百科
我們認識到使用者畫像具有的極高價值,下面就來看看該如何搭建使用者畫像。
如何構建使用者畫像
使用者畫像準備階段——資料的挖掘和收集
對網站、活動頁面進行SDK埋點。即預先設定好想要獲取的“事件”,讓程式設計師在前/後端模組使用 Java/Python/PHP/Ruby 語言開發,撰寫程式碼把“事件”埋到相應的頁面上,用於追蹤和記錄的使用者的行為,並把實時資料傳送到後臺資料庫或者客戶端。
所謂“事件”,就是指使用者作用於產品、網站頁面的一系列行為,由資料收集方(產品經理、運營人員)加以描述,使之成為一個個特定的欄位標籤。
我們以“網站購物”為例,為了抓取使用者的人口屬性和行為軌跡,做SDK埋點之前,先預設使用者購物時的可能行為,包括:訪問首頁、註冊登入、搜尋商品、瀏覽商品、價格對比、加入購物車、收藏商品、提交訂單、支付訂單、使用優惠券、檢視訂單詳情、取消訂單、商品評價等。
把這些行為用程式語言進行描述,嵌入網頁或者商品頁的相應位置,形成觸點,讓使用者在點選時直接產生網路行為資料(登陸次數、訪問時長、啟用率、外部觸點、社交資料)以及服務內行為資料(瀏覽路徑、頁面停留時間、訪問深度、唯一頁面瀏覽次數等等)。
資料反饋到伺服器,被存放於後臺或者客戶端,就是我們所要獲取到的使用者基礎資料。
然而,在大多數時候,利用埋點獲取的基礎資料範圍較廣,使用者資訊不夠精確,無法做更加細化的分類的情況。比如說,只知道使用者是個男性,而不知道他是哪個年齡段的男性。
在這種情況下,為了得到更加詳細的,具有區分度的資料,我們可以利用A/B test。
A/B test就是指把兩個或者多個不同的產品/活動/獎品等推送給同一個/批人,然後根據使用者作出的選擇,獲取到進一步的資訊資料。
為了知道男性使用者是哪個年齡層的,藉助A/B test,我們利用抽獎活動,在獎品頁面進行SDK埋點後,分別選了適合20~30歲和30~40歲兩種不同年齡段使用的禮品,最後使用者選擇了前者,於是我們能夠得出:這是一位年齡在20~30歲的男性使用者。
以上就是資料的獲取方法。有了相關的使用者資料,我們下一步就是做資料分析處理——資料建模。
使用者畫像成型階段——資料建模
1、定性與定量相結合的研究方法
定性化研究方法就是確定事物的性質,是描述性的;定量化研究方法就是確定物件數量特徵、數量關係和數量變化,是可量化的。
一般來說,定性的方法,在使用者畫像中,表現為對產品、行為、使用者個體的性質和特徵作出概括,形成對應的產品標籤、行為標籤、使用者標籤。
定量的方法,則是在定性的基礎上,給每一個標籤打上特定的權重,最後通過數學公式計算得出總的標籤權重,從而形成完整的使用者模型。
所以說,使用者畫像的資料建模是定性與定量的結合。
2、資料建模——給標籤加上權重
給使用者的行為標籤賦予權重。
使用者的行為,我們可以用4w表示: WHO(誰);WHEN(什麼時候);WHERE(在哪裡);WHAT(做了什麼),具體分析如下:
WHO(誰):定義使用者,明確我們的研究物件。主要是用於做使用者分類,劃分使用者群體。網路上的使用者識別,包括但不僅限於使用者註冊的ID、暱稱、手機號、郵箱、身份證、微信微博號等等。
WHEN(時間):這裡的時間包含了時間跨度和時間長度兩個方面。“時間跨度”是以天為單位計算的時長,指某行為發生到現在間隔了多長時間;“時間長度”則為了標識使用者在某一頁面的停留時間長短。
越早發生的行為標籤權重越小,越近期權重越大,這就是所謂的“時間衰減因子”。
WHERE(在哪裡):就是指使用者發生行為的接觸點,裡面包含有內容+網址。內容是指使用者作用於的物件標籤,比如小米手機;網址則指使用者行為發生的具體地點,比如小米官方網站。權重是加在網址標籤上的,比如買小米手機,在小米官網買權重計為1,,在京東買計為0.8,在淘寶買計為0.7。
WHAT(做了什麼):就是指的使用者發生了怎樣的行為,根據行為的深入程度新增權重。比如,使用者購買了權重計為1,使用者收藏了計為0.85,使用者僅僅是瀏覽了計為0.7。
當上面的單個標籤權重確定下來後,就可以利用標籤權重公式計算總的使用者標籤權重:
標籤權重=時間衰減因子×行為權重×網址權重
舉個栗子:A使用者今天在小米官網購買了小米手機;B使用者七天前在京東瀏覽了小米手機。
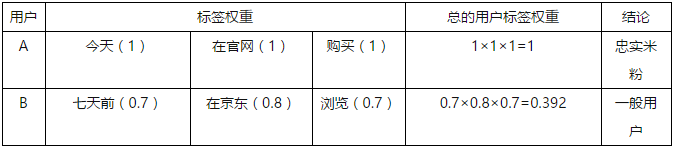
由此得出單個使用者的標籤權重,打上“是否忠誠”的標籤。
通過這種方式對多個使用者進行資料建模,就能夠更廣的覆蓋目標使用者群,為他們都打上標籤,然後按照標籤分類:總權重達到0.9以上的被歸為忠實使用者,ta們都購買了該產品……。這樣的一來,企業和商家就能夠根據相關資訊進行更加精準的營銷推廣、個性化推薦。
關於埋點
資料埋點的具體目的是:
一、在產品流程關鍵部位植相關統計程式碼,用來追蹤每次使用者的行為,統計關鍵流程的使用程度。
二、在產品中植入多段程式碼追蹤使用者連續行為,建立使用者模型來具體化使用者在使用產品中的操作行為。
三、與研發及資料分析師團隊合作,通過資料埋點還原出使用者畫像及使用者行為,建立資料分析後臺,通過資料分析、優化產品。
以上也是APP資料埋點分三個階段。
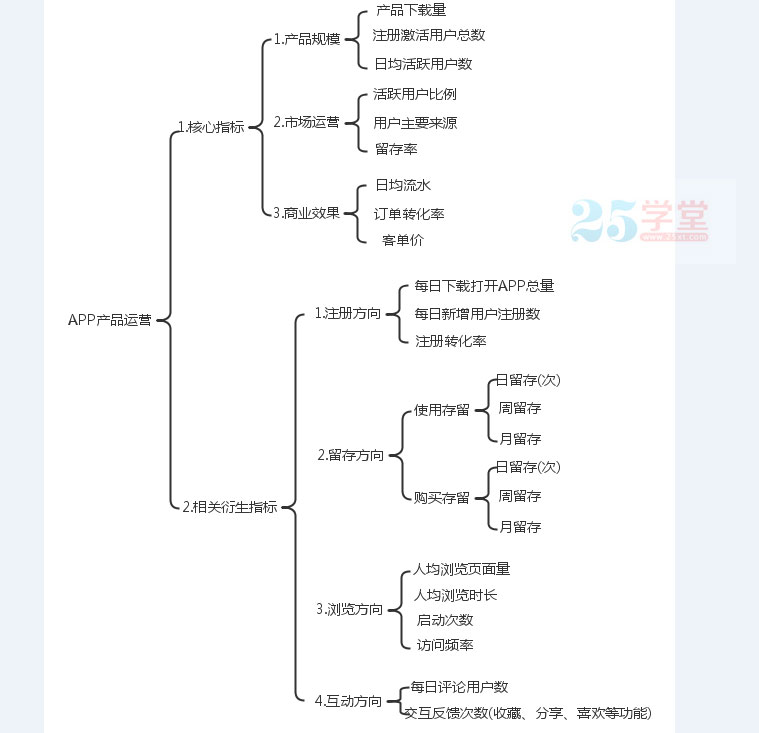
通過埋點我們可以拿到以下四大想要的的目標資料:
1、行為資料:時間、地點、人物、互動、互動的內容;
2、質量資料:瀏覽器載入情況、錯誤異常等;
3、環境資料:瀏覽器相關的元資料以及地理、運營商等;
4、運營資料:PV、UV、轉化率、留存率(很直觀的資料);
有關使用者畫像的介紹到此就告一段落了,鑑於自身能力有限,很多地方表達的不到位或者沒有提及,有啥意見或者建議歡迎留言!
來源:人人都是產品經理(直通車)