
【填坑】KMP
KMP用於求b串在a串的出現位置(字串匹配)。我們通過一道題來講講KMP的演算法過程。
【HDU 1711】給定兩個數字串a、b。求b在a第一次出現的位置。若沒出現輸出-1。
一般的暴力演算法就是暴力匹配。若有一個位置匹配失敗,則回溯後重新匹配。時間複雜度高達
。
可以發現,這個過程中有大量的冗餘運算。比方說,匹配失敗後(藍色點),圖中的紅色段都是已經匹配好的了。
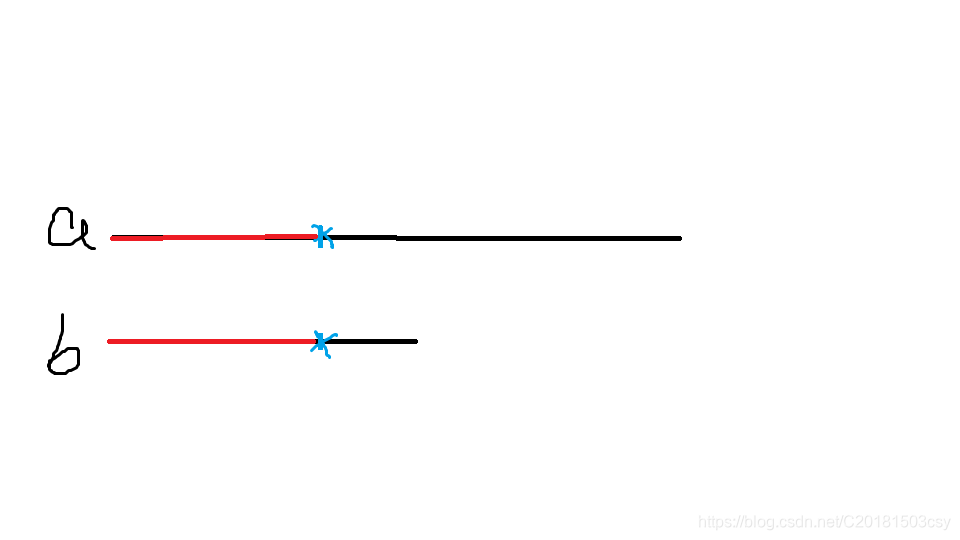
那麼我們想要做的,就是將b向右移動若干個單位,使得a中的藍點能夠匹配上就行了。
我們把移動後的串記作b’(如圖)
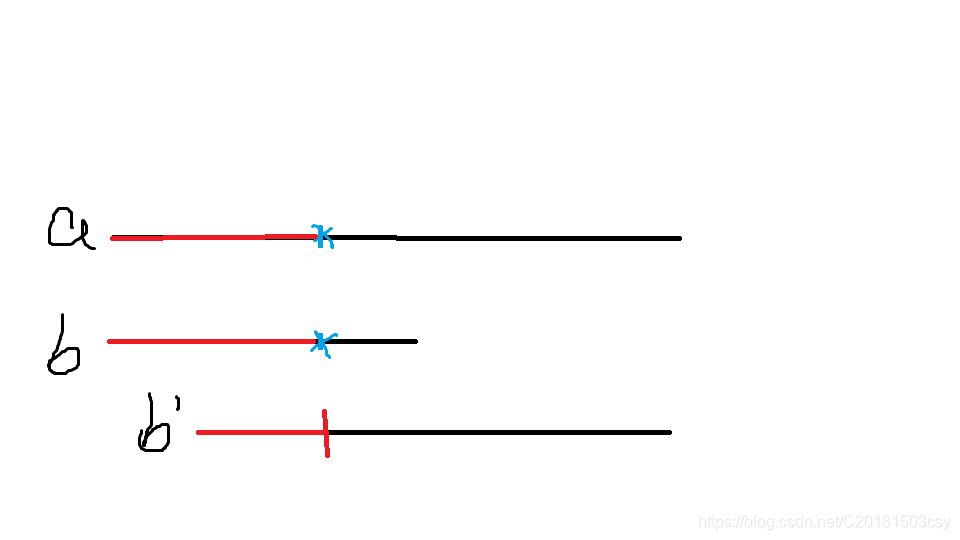
顯然,b’的紅色段(即b紅色段的開頭一小段)等於a紅色段的末尾一小段(即b紅色段的末尾一小段),也就是說。b’的紅色段是b的一個字首字尾公共子串。為了避免遺漏,b’的紅色段就應該是b前i-1個元素的最長字首字尾公共子串。
舉一個例子。若現在有一個串:
abababa
其字首有:
a
ab
aba
abab
ababa
ababab
字尾有:
a
ba
aba
baba
ababa
ababab
字首字尾公共子串有:
a
aba
ababa
(原串本身不能作為字首字尾公共子串)
於是,我們用nxt[i]表示若在b的i處匹配失敗,應該再從哪裡開始匹配。這個陣列可以用遞推搞定。特殊地,nxt[0]=-1
首先,由上面的分析可知,nxt[i]就相當於b前i-1個元素的最長字首字尾公共子串的長度。
考慮已求出前i-1個nxt[i]。那麼就判斷第i-1個字元是否能加入到i-2的最長字首字尾公共子串中。如果能,就有nxt[i]=nxt[i-1]+1。否則,令j=nxt[i-1],重複上述過程。
講得不是很清楚,但看看程式碼應該就能明白:
nxt[0] = -1;
for(i = 1; i < m; i++)
{
j = 然後用nxt[i]計算匹配位置:
for(i = j = 0; i <= n; i++, j++)
{
if(j == m)
{
printf("%d\n", i - j + 1);
break;
}
if(i == n)
{
puts("-1");
break;
}
while(j != -1 && a[i] != b[j])
j = nxt[j];
}
題目的完整程式碼:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int mn = 1000005, mm = 10005;
int a[mn], b[mm], nxt[mm];
int main()
{
int t, n, m, i, j;
scanf("%d", &t);
while(t--)
{
scanf("%d%d", &n, &m);
for(i = 0; i < n; i++)
scanf("%d", &a[i]);
for(i = 0; i < m; i++)
scanf("%d", &b[i]);
if(n < m)
{
puts("-1");
continue;
}
nxt[0] = -1;
for(i = 1; i < m; i++)
{
j = nxt[i - 1];
while(j != -1 && b[i - 1] != b[j])
j = nxt[j];
nxt[i] = j + 1;
}
for(i = j = 0; i <= n; i++, j++)
{
if(j == m)
{
printf("%d\n", i - j + 1);
break;
}
if(i == n)
{
puts("-1");
break;
}
while(j != -1 && a[i] != b[j])
j = nxt[j];
}
}
}
附:時間複雜度分析:
計算匹配位置部分顯然為
預處理nxt[i]時,根據其構造方法可知,每一個位置最多會被當做“跳板”1次。這樣,內層處理的平攤複雜度為
。於是預處理部分為
,總時間複雜度為